
 Github
Github 文档
文档 论文
论文XMem++
从少量标注帧实现生产级视频分割
Maksym Bekuzarov$^\dagger$, Ariana Michelle Bermudez Venegas$^\dagger$, Joon-Young Lee, Hao Li
元宇宙实验室 @ MBZUAI (穆罕默德·本·扎耶德人工智能大学)
$^\dagger$ 这些作者对本工作贡献相同。
目录
演示
受电影行业用例启发,XMem++ 是一个交互式视频分割工具,只需用户提供少量分割掩码,就能以最少的人工监督对非常具有挑战性的用例进行分割,例如:
- 物体的部分(仅提供6个标注帧):
https://github.com/max810/XMem2/assets/29955120/3d3761e2-2e73-484a-a1ed-ec717d8fed05
- 流体物体如头发(仅提供5个标注帧):
https://github.com/max810/XMem2/assets/29955120/ba746a2a-6333-4654-b39c-b93b9eb1ae0c
- 可变形物体如衣服(分别使用5和11个标注帧)
https://github.com/max810/XMem2/assets/29955120/3a8750e0-44ca-4cce-9b16-8f7154dbb217
https://github.com/max810/XMem2/assets/29955120/689512a6-f60a-4258-b282-4b799f12b0c9
[局限性]
概述
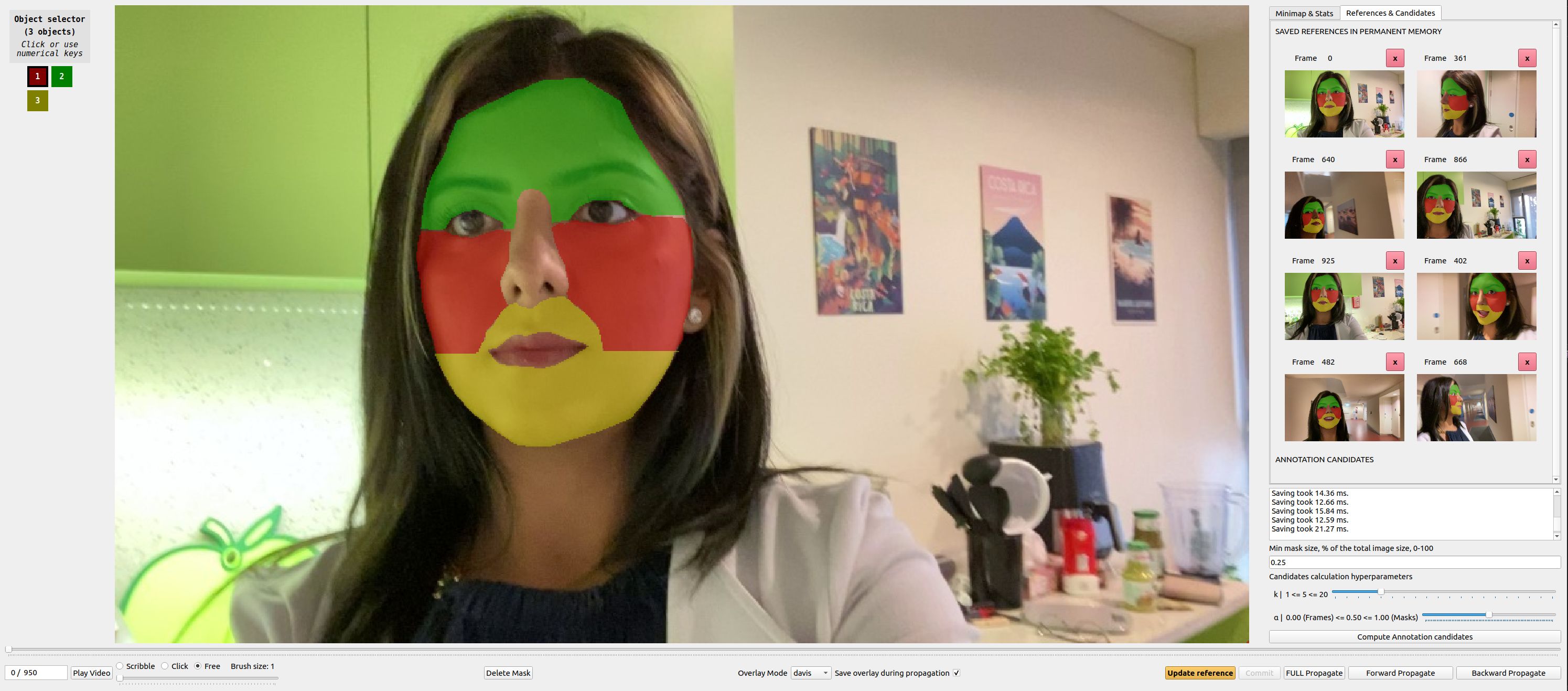 |
|---|
| XMem++ 更新后的GUI |
XMem++ 是基于 Ho Kei Cheng 和 Alexander Schwing 的 XMem 构建的,并通过添加以下内容进行了改进:
- 永久记忆模块,仅需少量手动标注即可大幅提高模型精度(参见结果)
- 标注候选选择算法,选择 $k$ 个最佳的下一帧供用户提供标注。
- 我们使用 XMem++ 收集并标注了 PUMaVOS - 23个视频数据集,包含不寻常和具有挑战性的标注场景,分辨率为480p,30FPS。参见数据集
此外还有以下特点:
- 改进的GUI - 参考标签页可查看/编辑永久记忆中的帧,候选标签页显示算法预测的标注候选帧等。
- 与XMem相比,速度和内存使用开销可忽略不计(如果只使用少量手动提供的标注)
- 易于使用的Python接口 - 现在您可以轻松地将 XMem++ 作为GUI应用程序和Python库使用。
- 在RTX 3090上处理480p视频可达30+ FPS
- 配备GUI(修改自MiVOS)。
入门
环境设置
首先,安装所需的Python包:
- Python 3.8+
- PyTorch 1.11+(参见PyTorch获取安装说明)
- 与PyTorch版本对应的
torchvision - OpenCV(尝试
pip install opencv-python) - 其他:
pip install -r requirements.txt - 使用GUI:
pip install -r requirements_demo.txt
下载权重
使用 ./scripts/download_models.sh 下载预训练模型,或手动下载并将它们放在 ./saves 目录中(如果目录不存在则创建)。您可以从 [XMem GitHub] 或 [XMem Google Drive] 下载。对于推理,您只需要 XMem.pth,但对于GUI,还需要下载 fbrs.pth 和 s2m.pth。
使用图形界面
要在新视频上运行图形界面:
python interactive_demo.py --video example_videos/chair/chair.mp4
要在一系列图像上运行:
python interactive_demo.py --images example_videos/chair/JPEGImages
这两个命令都会在工作区文件夹(默认为.workspace)中为当前视频创建一个文件夹,并将所有遮罩和预测结果保存在那里。
要继续编辑工作区中的现有项目,运行以下命令:
python interactive_demo.py --workspace ./workspace/<video_name>
如果您有多个对象,请确保在首次创建项目时在上述命令中添加--num-objects <num_objects>。之后它会为了方便起见保存在项目文件中 =)
例如:
python interactive_demo.py --images example_videos/caps/JPEGImages --num-objects 2
欲了解更多信息,请访问DEMO.md
使用**XMem++**命令行和Python接口
我们在process_video.py中提供了一个简单的命令行接口,您可以这样使用:
python process_video.py \
--video <视频文件/提取的.jpg帧路径> \
--masks <现有.png遮罩的目录路径> \
--output <保存结果的路径>
该脚本将直接使用现有的视频和真实遮罩(将使用给定目录中的所有遮罩),并运行一次分割。
也支持简写参数-v -m -o。
查看Python API或main.py以了解更复杂的用例和解释。
导入现有项目
如果您已经有来自其他工具的现有帧和/或遮罩,可以使用以下命令将它们导入到工作区:
python import_existing.py --name <要创建的项目名称> [--images <帧文件夹路径>] [--mask <遮罩文件夹路径>]
必须指定--images、--masks中的一个(或两个)。
您还可以指定--size <整数>来动态调整帧的大小(调整较短边,保持比例)
这将执行以下操作:
- 在您的工作区内创建一个项目目录,使用
--name参数中的名称。 - 将您给定的图像/遮罩复制到其中。
- 将RGB遮罩转换为必要的调色板(XMem++使用DAVIS调色板,每个新对象=新颜色)。
- 如果使用
--size参数指定,则调整帧的大小。
Docker支持
我们在DockerHub上提供了2个镜像:
max810/xmem2:base-inference- 更小更轻量 - 用于从命令行运行推理,如命令行部分所示。max810/xmem2:gui- 用于交互式运行图形界面。
要使用它们,只需运行./run_inference_in_docker.sh或./run_gui_in_docker.sh,并附带相应的cmd/gui参数(参见相应部分[推理] [GUI])。它们会为docker run命令提供适当的参数,并自动为输入/输出目录创建相应的卷。
示例:
# 推理
./run_inference_in_docker.sh -v example_videos/caps/JPEGImages -m example_videos/caps/Annotations -o directory/that/does/not/exist/yet
# 交互式GUI
./run_gui_in_docker.sh --video example_videos/chair/chair.mp4 --num_objects 2
对于GUI,如有必要,您可以在run_gui_in_docker.sh中更改变量$LOCAL_WORKSPACE_DIR和$DISPLAY_TO_USE。
请注意,交互式导入按钮将不起作用(它们将打开容器文件系统内的路径,而不是主机的路径)。
构建您自己的镜像
对于命令行推理:
docker build . -t <your-repo/your-image-name[:your-tag]> --target xmem2-base-inference
对于GUI:
docker build . -t <your-repo/your-image-name[:your-tag]> --target xmem2-gui
数据格式
- 图像应使用.jpg格式。
- 遮罩是使用DAVIS调色板的RGB .png文件,保存为调色板图像(在Pillow Image Module中使用
Image.convert('P'))。如果您的遮罩不遵循这种调色板,只需运行python import_existing.py来自动转换它们(参见导入现有项目)。 - 当使用
run_on_video.py处理视频文件时,遮罩应命名为frame_%06d.<ext>,从0开始:frame_000000.jpg, frame_0000001.jpg, ...这是任何用例的首选文件名。
更多信息和便利命令请参见数据格式帮助
训练
关于训练,请参考原始XMem仓库。 我们使用XMem提供的原始权重,模型未经过任何重新训练或微调。
欢迎微调XMem并替换本项目中的权重。
方法论
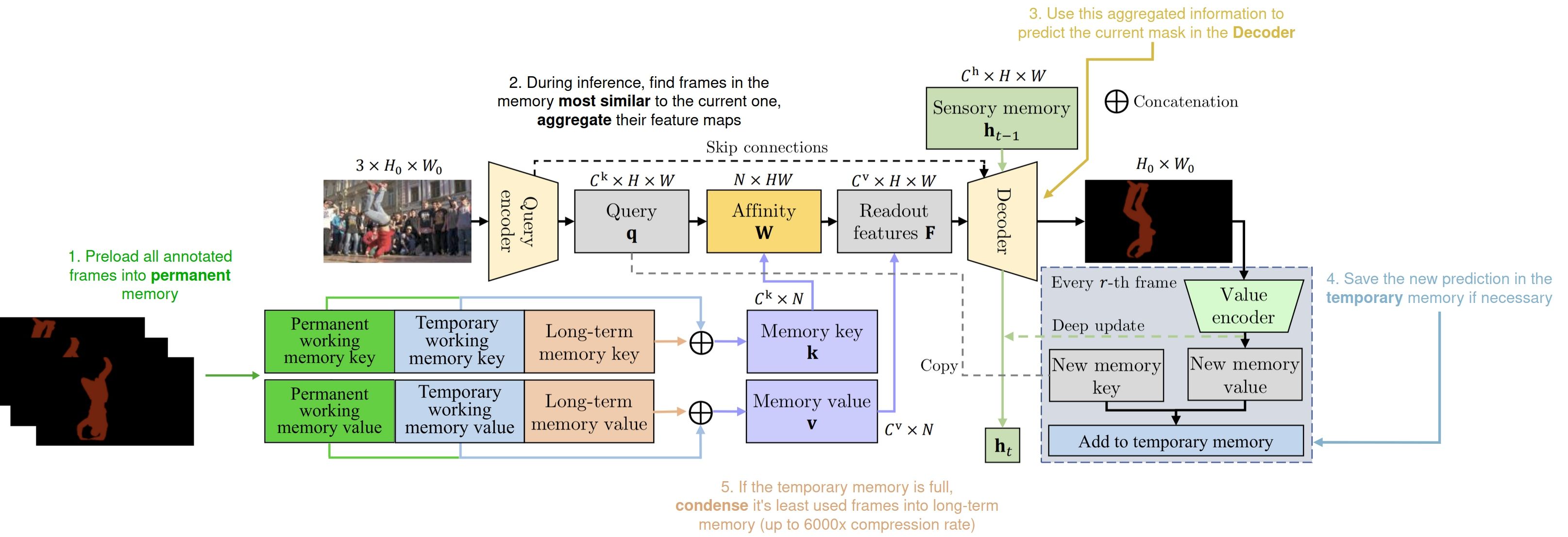 |
|---|
| 带注释的XMem++架构概览 |
XMem++是一个基于内存的交互式分割模型 - 这意味着它使用一组参考帧/特征图及其对应的掩码(预测的或可用的真实标注)来预测新帧的掩码,预测基于新帧与已处理帧的相似度。
与XMem一样,我们使用了受Atkinson-Shiffrin人类记忆模型启发的两种内存类型 - 工作记忆和长期记忆。前者存储近期的具有丰富细节的卷积特征图,后者存储经过高度压缩的特征,用于视频中相距较远帧之间的长期依赖关系。
然而,现有的使用内存机制来预测当前帧分割掩码的分割方法(如XMem、TBD、AoT、DeAOT、STCN等)通常逐帧处理,因此存在一个共同问题 - 当视频中遇到新的真实标注时,视觉质量会出现"跳跃"。
 |
|---|
| 为什么永久记忆有帮助 - 在永久记忆中保存来自视频不同部分的多个标注,使模型能够在目标对象的不同场景/外观之间平滑插值 |
为了解决这个问题,我们提出了一个新的永久记忆模块 - 实现方式与XMem的工作记忆相同 - 我们将用户提供的所有标注进行处理并放入永久记忆模块。这样,用户提供的每个真实标注都可以影响视频中的任何帧,无论其位置如何。这提高了整体分割准确性,并使模型能够在对象的不同外观之间平滑插值(见上图)。
更多详细信息请参考我们的arxiv页面[Arxiv] [PDF],第3.2节。
帧标注候选选择器
我们提出了一个简单的算法来选择用户下一步应该标注哪些帧,以最大化性能并节省时间。它基于多样性的概念 - 选择能捕捉目标对象最多样外观的帧 - 以最大化网络从这些标注中获得的信息。
它具有以下特点:
- 目标特定:帧的选择取决于您试图分割的对象。

- 模型通用:它基于卷积特征图和像素相似度度量(负$\mathcal{L}_{2}$距离)运行,因此不特定于XMem++。
- 对分割目标无限制:一些方法试图自动估计分割的视觉质量,这隐含地假设高质量分割遵循低级图像线索(边缘、角点等)。然而,在分割对象的部分时,这并不成立,请看:

- 确定性和简单:它通过多样性度量对剩余帧进行排序,用户只需选择前$k$个最多样的候选帧。
更多详细信息请参考我们的arxiv页面[Arxiv] [PDF],第3.3节和附录D。
PUMaVOS数据集
我们使用XMem++收集和标注了一个数据集,其中包含受电影制作行业启发的具有挑战性和实用性的用例。
|
鞋子 |
反射 |
身体部位 |
可变形物体 |
|
相似物体,遮挡 |
纹身/图案 |
快速运动 |
多物体部位 |








**部分和非常规遮罩视频对象分割(PUMaVOS)**数据集具有以下特点:
- 24个视频,21187帧密集标注;
- 涵盖复杂的实际应用场景,如物体部位、频繁遮挡、快速运动、可变形物体等;
- 视频平均长度为883帧或29秒,较长的可达1分钟;
- 以30FPS的帧率进行全密集标注;
- 面向基准测试:没有分为训练/测试集,旨在尽可能多样化以测试您的模型;
- 100%开放且可免费下载。
下载
单独的序列和遮罩可在此处获取:[Google Drive] [备用Google Drive]
PUMaVOS .zip 下载链接:[Google Drive]
[备用Google Drive]
许可证
PUMaVOS 根据 CC BY 4.0 许可证 发布 - 您可以将其用于任何目的(包括商业用途),只需在使用时注明作者(我们),并指出您是否做了任何修改。完整的许可证文本请参见 LICENSE_PUMaVOS
引用
如果您在工作中使用了此代码或PUMaVOS数据集,请引用我们:
@misc{bekuzarov2023xmem,
标题:{XMem++:基于少量标注帧的生产级视频分割},
作者:{Maksym Bekuzarov 和 Ariana Bermudez 和 Joon-Young Lee 和 Hao Li},
年份:{2023},
电子预印本:{2307.15958},
预印本存档:{arXiv},
主要类别:{cs.CV}
}
联系方式:maksym.bekuzarov@gmail.com, bermudezarii@gmail.com, jolee@adobe.com, hao@hao-li.com











