
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文GLaMM  :像素级定位的大规模多模态模型 [CVPR 2024]
:像素级定位的大规模多模态模型 [CVPR 2024]

Hanoona Rasheed*, Muhammad Maaz*, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Eric Xing, Ming-Hsuan Yang 和 Fahad Khan
穆罕默德·本·扎耶德人工智能大学, 澳大利亚国立大学, 阿尔托大学, 卡内基梅隆大学, 加州大学默塞德分校, 林雪平大学, 谷歌研究院

📢 最新更新
- 2024年3月21日- 我们很高兴宣布发布GranD数据集和GranD自动标注流程 🔥
- 2024年2月27日- 我们很兴奋地宣布GLaMM已被CVPR 2024接收!🎊
- 2023年12月27日- GLaMM训练和评估代码、预训练检查点和GranD-f数据集已发布 点击获取详情 🔥🔥
- 2023年11月29日:GLaMM在线交互演示已发布 演示链接。 🔥
- 2023年11月7日:GLaMM论文已发布 arxiv链接。 🌟
- 🌟 特别推荐:GLaMM现在在HuggingFace的AK's 每日论文页面顶部突出显示! 🌟
GLaMM概述
定位大规模多模态模型(GLaMM)是一个端到端训练的LMM,它提供视觉定位能力,可以灵活处理图像和区域输入。这使得新的统一任务——定位对话生成成为可能,该任务结合了短语定位、指代表达分割和视觉语言对话。GLaMM具备详细的区域理解、像素级定位和对话能力,可以在多个粒度层面上与用户提供的视觉输入进行多样化的交互。
🏆 贡献
-
GLaMM简介。 我们提出了定位大规模多模态模型(GLaMM),这是首个能够生成与对象分割掩码无缝集成的自然语言响应的模型。
-
新颖的任务和评估。 我们提出了一个新的定位对话生成(GCG)任务。我们还为此任务引入了全面的评估协议。
-
GranD数据集创建。 我们创建了GranD - 定位任意物体数据集,这是一个大规模的密集标注数据集,包含810M个区域中的7.5M个独特概念的定位信息。
🚀 深入探索:GLaMM的训练和评估
通过我们关于模型训练和评估方法的详细指南,深入了解GLaMM的核心。
-
安装:提供设置conda环境以运行GLaMM训练、评估和演示的指南。
-
数据集:提供下载和整理训练和评估所需数据集的详细说明。
-
GranD:提供下载GranD数据集和运行自动标注流程的详细说明。
-
模型库:提供所有预训练GLaMM检查点的下载链接。
-
训练:提供如何训练GLaMM模型以实现各种功能的说明,包括定位对话生成(GCG)、区域级描述和指代表达分割。
-
评估:概述了使用预训练检查点评估GLaMM模型的程序,涵盖了定位对话生成(GCG)、区域级描述和指代表达分割,如我们的论文中所报告的。
-
演示:指导您设置本地演示以展示GLaMM的功能。
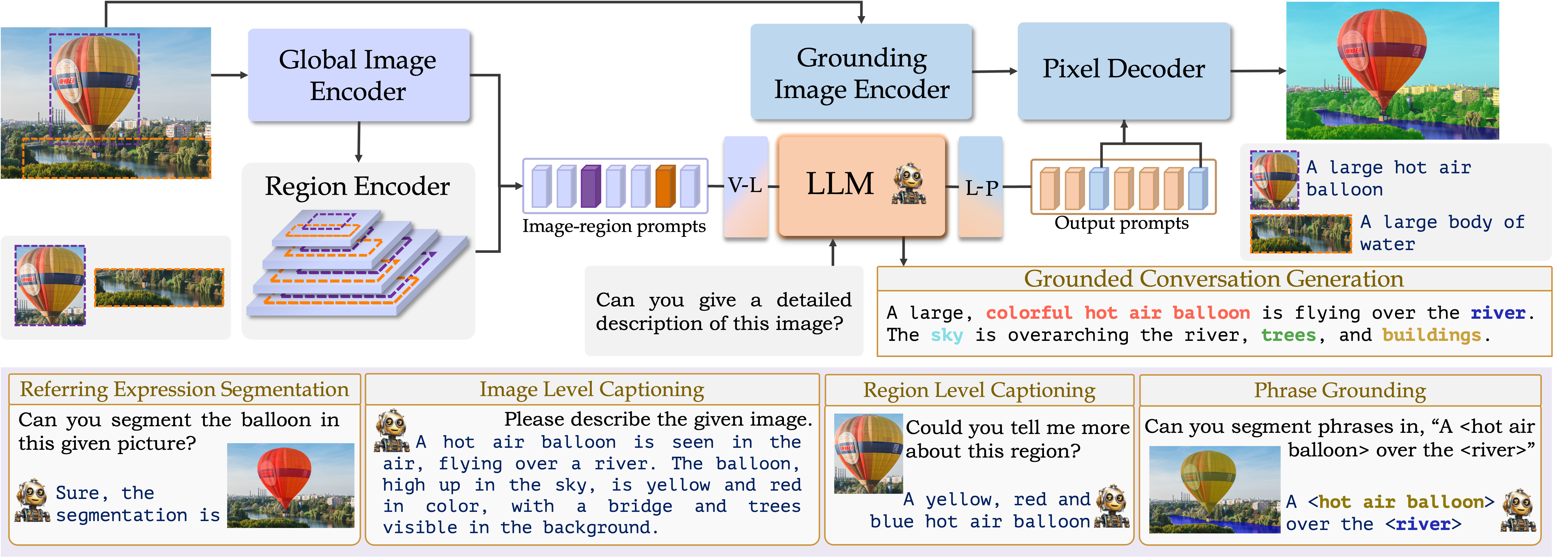
👁️💬 GLaMM:定位大规模多模态模型
GLaMM的组件被设计为既可以处理文本提示,也可以处理可选的视觉提示(图像级和感兴趣区域),允许在多个粒度级别上进行交互,并生成定位文本响应。
🔍 定位任意物体数据集(GranD)
定位任意物体 GranD数据集是一个大规模数据集,具有自动标注流程,用于详细的区域级理解和分割掩码。GranD包含7.5M个独特概念,锚定在总共810M个区域中,每个区域都有一个分割掩码。
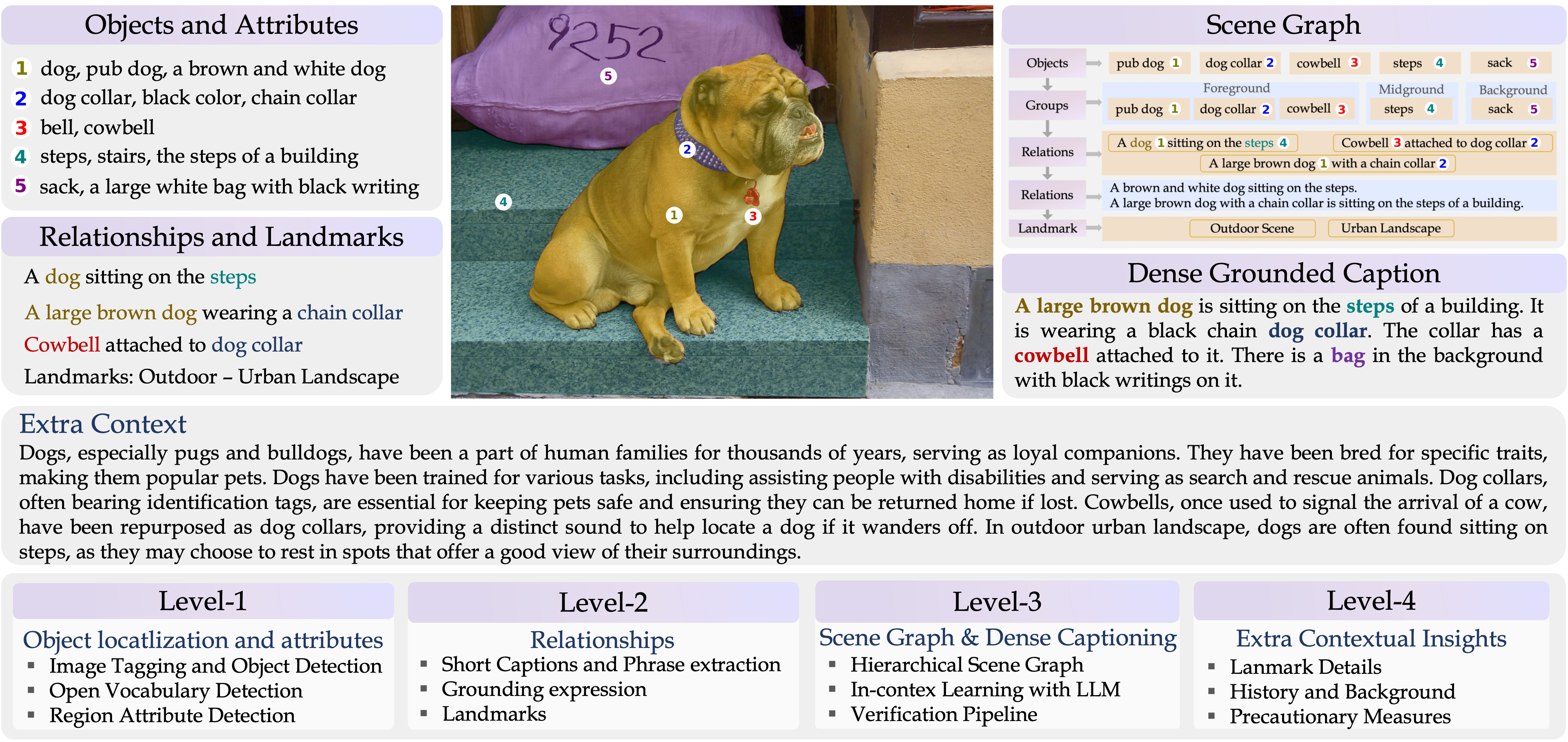
以下我们展示了GranD数据集的一些示例。
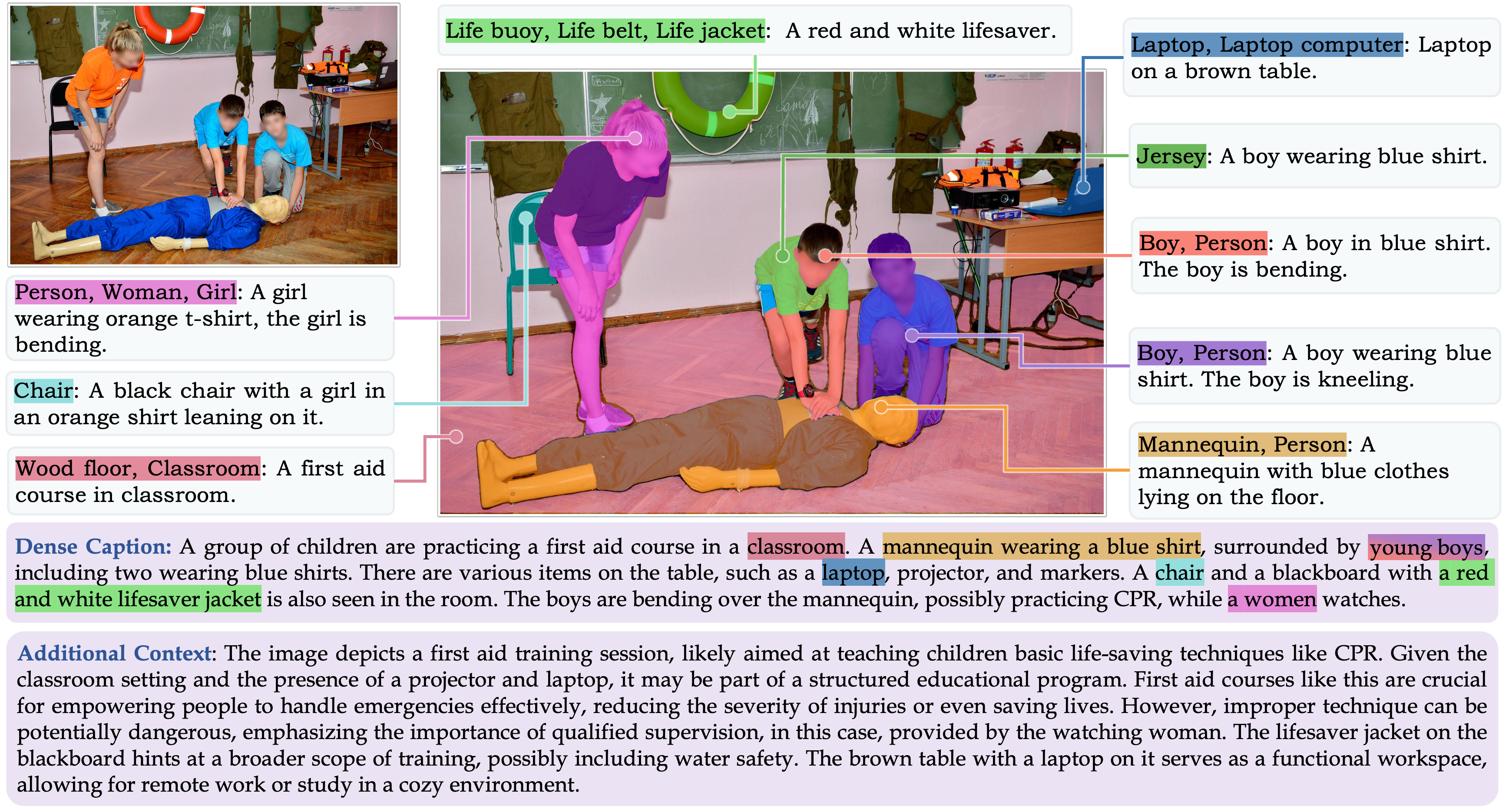

📚 构建GranD-f用于基于图像的对话生成
GranD-f数据集专为GCG任务设计,包含约21.4万对图像-文本对,用于微调阶段以获得更高质量的数据。
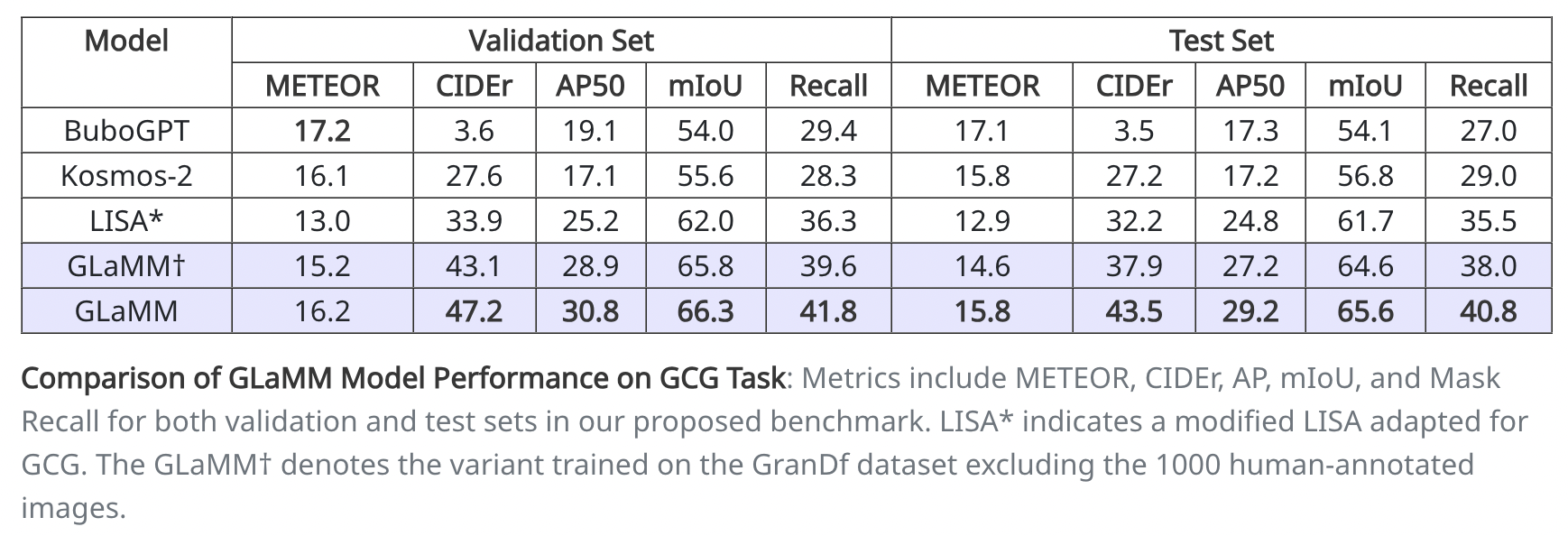
🤖 基于图像的对话生成(GCG)
介绍GCG,这是一项创建与分割掩码相关联的图像级描述的任务,旨在增强模型在自然语言描述中的视觉基础。

🚀 下游应用
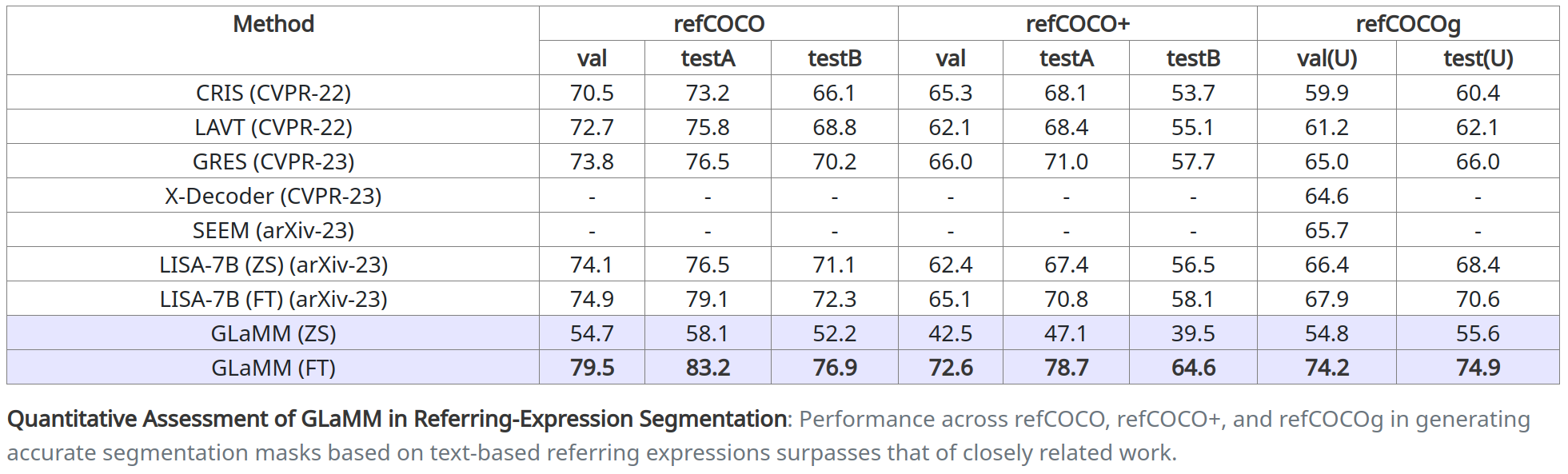
🎯 指代表达式分割
我们的模型在根据文本指代表达式创建分割掩码方面表现出色。

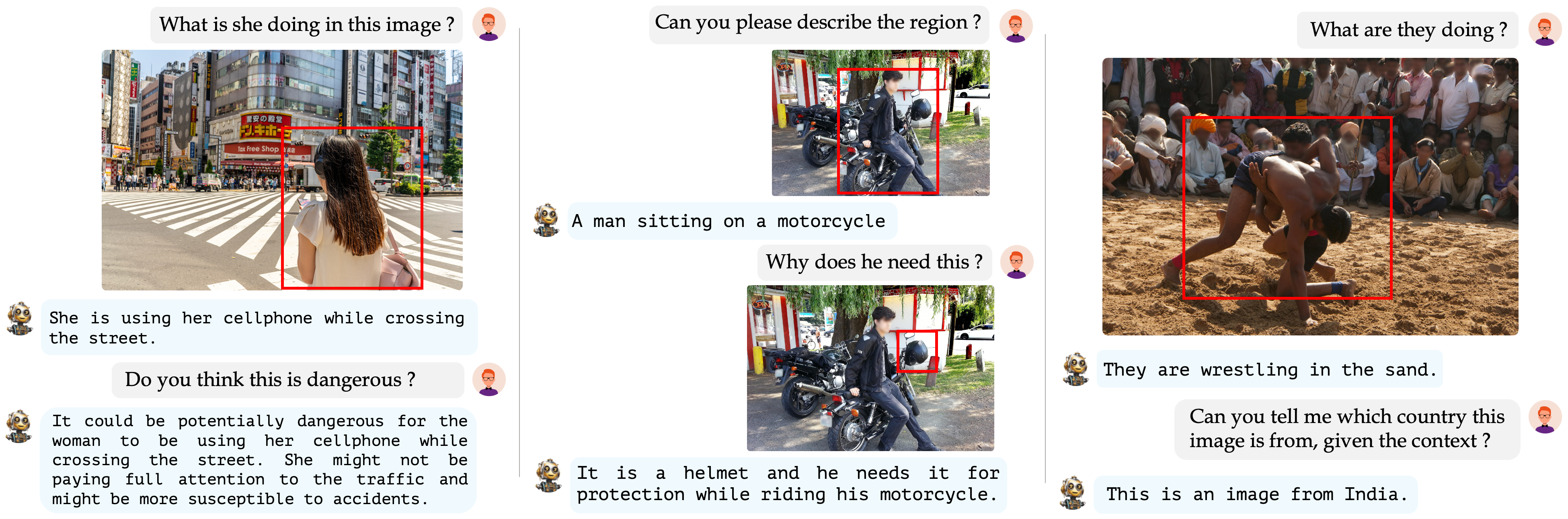
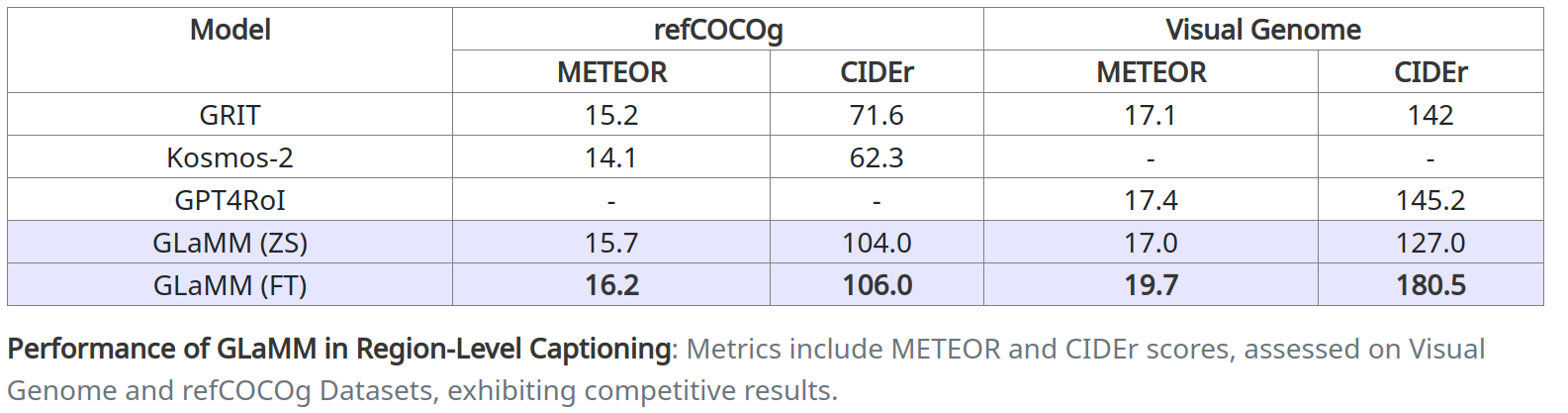
🖼️ 区域级描述
GLaMM生成详细的区域特定描述,并回答基于推理的视觉问题。
📷 图像描述
GLaMM提供高质量的图像描述,与专门的模型相比表现出色。

💬 对话式问答
GLaMM展示了其在进行详细、区域特定和基于图像的对话方面的实力。这有效地突显了其在复杂的视觉-语言交互中的适应性,以及保持大型语言模型固有推理能力的稳健性。

📜 引用
@article{hanoona2023GLaMM,
title={GLaMM: Pixel Grounding Large Multimodal Model},
author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
🙏 致谢
我们感谢LLaVA、GPT4ROI和LISA开源他们的模型和代码。














