
 访问官网
访问官网 Github
Github 文档
文档 论文
论文RNA-FM
2024年3月更新:
- RNA家族聚类和RNA类型分类教程和教程视频(中文)。
- mRNA-FM,一个在mRNA中的编码序列(CDS)上预训练的基础模型现已发布!该模型可以接收CDS并用上下文嵌入表示它们,有利于mRNA和蛋白质相关任务。
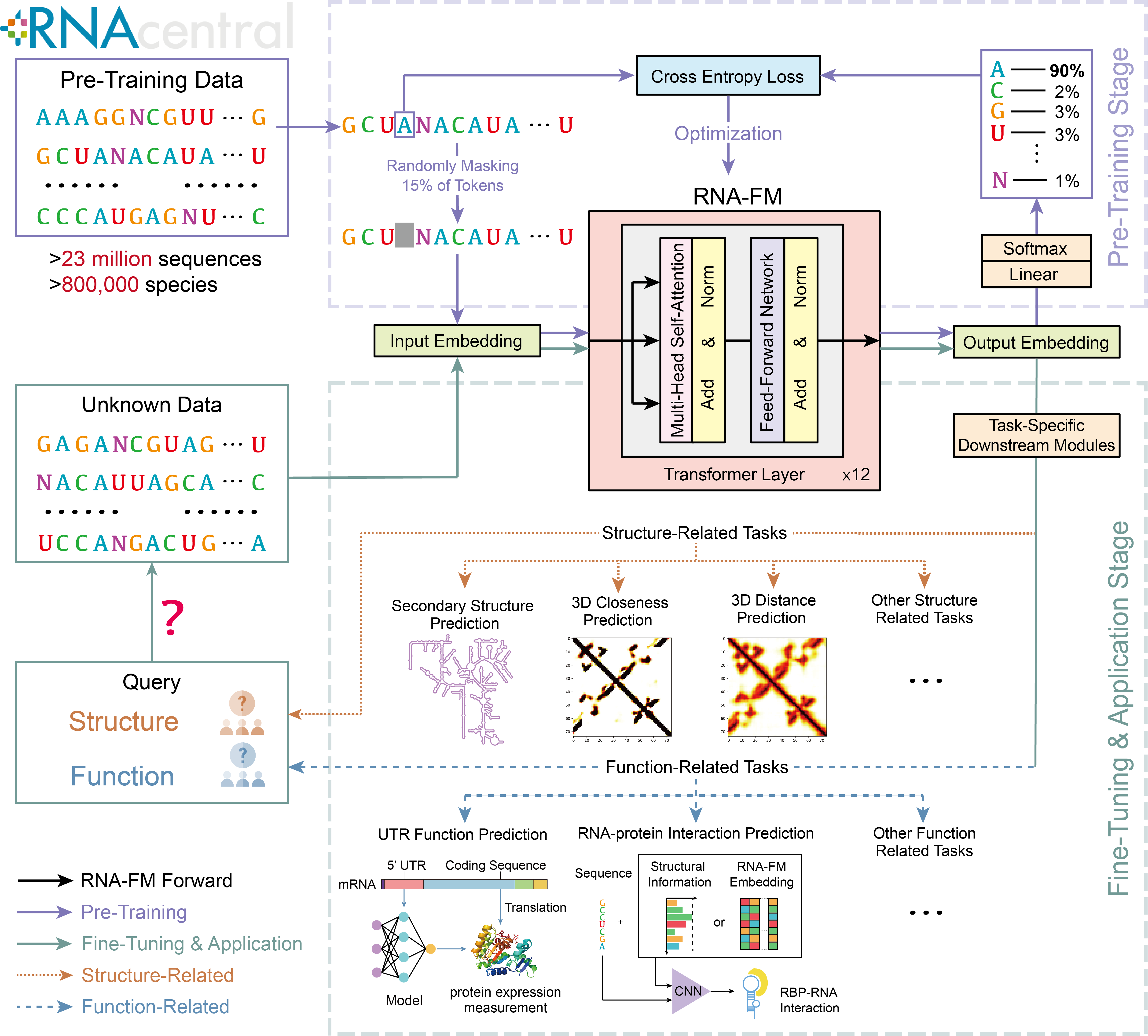
本仓库包含RNA基础模型(RNA-FM)的代码和预训练模型。 RNA-FM在各种结构预测任务以及几个功能相关任务中的表现优于所有测试的单序列RNA语言模型。 您可以在我们的论文《Interpretable RNA Foundation Model from Unannotated Data for Highly Accurate RNA Structure and Function Predictions》(Chen等,2022年)中找到有关RNA-FM的更多详细信息。
引用
@article{chen2022interpretable,
title={Interpretable rna foundation model from unannotated data for highly accurate rna structure and function predictions},
author={Chen, Jiayang and Hu, Zhihang and Sun, Siqi and Tan, Qingxiong and Wang, Yixuan and Yu, Qinze and Zong, Licheng and Hong, Liang and Xiao, Jin and King, Irwin and others},
journal={arXiv preprint arXiv:2204.00300},
year={2022}
}
使用Conda创建环境
首先,下载仓库并创建环境。
git clone https://github.com/ml4bio/RNA-FM.git
cd ./RNA-FM
conda env create -f environment.yml
然后,激活"RNA-FM"环境并进入工作空间。
conda activate RNA-FM
cd ./redevelop
访问预训练模型。
从这个谷歌云端硬盘链接下载预训练模型,并将pth文件放入pretrained文件夹。
使用现有脚本应用RNA-FM。
1. 嵌入提取。
python launch/predict.py --config="pretrained/extract_embedding.yml" \
--data_path="./data/examples/example.fasta" --save_dir="./resuts" \
--save_frequency 1 --save_embeddings
形状为(L,640)的RNA-FM嵌入将保存在$save_dir/representations中。
对于mRNA-FM,您可以使用额外的参数MODEL.BACKBONE_NAME来调用它:
python launch/predict.py --config="pretrained/extract_embedding.yml" \
--data_path="./data/examples/example.fasta" --save_dir="./resuts" \
--save_frequency 1 --save_embeddings --save_embeddings_format raw MODEL.BACKBONE_NAME mrna-fm
2. 下游预测 - RNA二级结构。
python launch/predict.py --config="pretrained/ss_prediction.yml" \
--data_path="./data/examples/example.fasta" --save_dir="./resuts" \
--save_frequency 1
预测的概率图将以.npy文件的形式保存,后处理的二元预测将以.ct文件的形式保存。您可以在$save_dir/r-ss中找到它们。
3. 在线版本 - RNA-FM服务器。
如果您在部署RNA-FM的本地版本时遇到任何问题,可以通过这个链接访问其在线版本,RNA-FM服务器。 您可以轻松地在服务器上提交作业并随后下载结果,无需设置环境和占用任何计算资源。
进一步开发的快速入门。
Python 3.8(可能更高版本)和PyTorch是使用此仓库必须安装的先决包。
如果您只想使用预训练的语言模型,可以使用以下pip命令在自己的环境中安装rna-fm。
您可以从PIPY安装rna-fm:
pip install rna-fm
或者从github安装rna-fm:
cd ./RNA-FM
pip install .
安装后,您可以使用以下代码加载RNA-FM并提取其嵌入:
import torch
import fm
# 加载RNA-FM模型
model, alphabet = fm.pretrained.rna_fm_t12()
batch_converter = alphabet.get_batch_converter()
model.eval() # 禁用dropout以获得确定性结果
# 准备数据
data = [
("RNA1", "GGGUGCGAUCAUACCAGCACUAAUGCCCUCCUGGGAAGUCCUCGUGUUGCACCCCU"),
("RNA2", "GGGUGUCGCUCAGUUGGUAGAGUGCUUGCCUGGCAUGCAAGAAACCUUGGUUCAAUCCCCAGCACUGCA"),
("RNA3", "CGAUUCNCGUUCCC--CCGCCUCCA"),
]
batch_labels, batch_strs, batch_tokens = batch_converter(data)
# 提取嵌入(在CPU上)
with torch.no_grad():
results = model(batch_tokens, repr_layers=[12])
token_embeddings = results["representations"][12]
更多教程可以在https://ml4bio.github.io/RNA-FM/找到。相关的笔记本存储在tutorials文件夹中。
对于mRNA-FM,上述代码需要稍作修改。需要注意的是,输入RNA序列的长度应为3的倍数,以确保序列可以被标记为一系列密码子(3-mer)。
import torch
import fm
# 加载mRNA-FM模型
model, alphabet = fm.pretrained.mrna_fm_t12()
batch_converter = alphabet.get_batch_converter()
model.eval() # 禁用dropout以获得确定性结果
# 准备数据
data = [
("CDS1", "AUGGGGUGCGAUCAUACCAGCACUAAUGCCCUCCUGGGAAGUCCUCGUGUUGCACCCCUA"),
("CDS2", "AUGGGGUGUCGCUCAGUUGGUAGAGUGCUUGCCUGGCAUGCAAGAAACCUUGGUUCAAUCCCCAGCACUGCA"),
("CDS3", "AUGCGAUUCNCGUUCCC--CCGCCUCC"),
]
batch_labels, batch_strs, batch_tokens = batch_converter(data)
# 提取嵌入(在CPU上)
with torch.no_grad():
results = model(batch_tokens, repr_layers=[12])
token_embeddings = results["representations"][12]
相关RNA语言模型(BERT风格)
| 简称 | 代码 | 主题 | 层数 | 嵌入维度 | 最大长度 | 输入 | 标记 | 数据集 | 描述 | 年份 | 发布者 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RNA-FM | 有 | 非编码RNA | 12 | 640 | 1024 | 序列 | 碱基 | RNAcentral 19 (2300万个样本) | 首个通用RNA语言模型 | 2022.04 | arxiv/bioRxiv |
| RNABERT | 有 | 非编码RNA | 6 | 120 | 440 | 序列 | 碱基 | RNAcentral (762370) 和 Rfam 14.3 数据集(使用部分多序列比对训练) | 专门用于结构对齐和聚类 | 2022.02 | NAR Genomics and Bioinformatics |
| UNI-RNA | 无 | RNA | 24 | 1280 | $\infty$ | 序列 | 碱基 | RNAcentral、nt 和 GWH (10亿) | 比RNA-FM规模更大、数据集更广的通用模型 | 2023.07 | bioRxiv |
| RNA-MSM | 有 | 非编码RNA | 12 | 768 | 1024 | 多序列比对 | 碱基 | Rfam 14.7 中的4069个RNA家族 | 直接利用多序列比对的进化信息的模型 | 2023.03 | NAR |
| SpliceBERT | 有 | 前体mRNA | 6 | 1024 | 512 | 序列 | 碱基 | 200万个前体信使RNA (pre-mRNA) | 专门用于前体mRNA剪接 | 2023.05 | bioRxiv |
| CodonBERT | 无 | mRNA CDS | 12 | 768 | 512*2 | 序列 | 密码子 (3mer) | NCBI的1000万个mRNA | 仅关注mRNA的CDS,不包括UTR | 2023.09 | bioRxiv |
| UTR-LM | 有 | mRNA 5'UTR | 6 | 128 | $\infty$ | 序列 | 碱基 | Ensembl、eGFP、mCherry和Cao的70万个5'UTR | 用于5'UTR和mRNA表达相关任务 | 2023.10 | bioRxiv |
| 3UTRBERT | 有 | mRNA 3'UTR | 12 | 768 | 512 | 序列 | k-mer | 20,362个3'UTR | 用于3'UTR介导的基因调控任务 | 2023.09 | bioRxiv |
| BigRNA | 无 | DNA | - | - | - | 序列 | - | 数千个与基因组匹配的数据集 | 组织特异性RNA表达、剪接、微RNA位点和RNA结合蛋白 | 2023.09 | bioRxiv |
引用
如果您在研究中发现这些模型有用,我们希望您能引用相关论文:
对于RNA-FM:
@article{chen2022interpretable,
title={Interpretable rna foundation model from unannotated data for highly accurate rna structure and function predictions},
author={Chen, Jiayang and Hu, Zhihang and Sun, Siqi and Tan, Qingxiong and Wang, Yixuan and Yu, Qinze and Zong, Licheng and Hong, Liang and Xiao, Jin and King, Irwin and others},
journal={arXiv preprint arXiv:2204.00300},
year={2022}
}
本代码的模型基于esm序列建模框架构建。 我们使用fairseq序列建模框架来训练我们的RNA语言模型。 我们非常感谢这两项优秀的工作!
许可证
本源代码根据MIT许可证授权,该许可证可在本源代码树根目录中的LICENSE文件中找到。











