
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文Octo


![]()
![]()
本仓库包含了训练和微调 Octo 通用机器人策略(GRPs)的代码。 Octo 模型是基于 transformer 的扩散策略,在80万个多样化的机器人轨迹上进行训练。
开始使用
按照安装说明进行操作,然后加载一个预训练的 Octo 模型!查看示例获取零样本评估和微调指南,以及
中的推理示例。
from octo.model.octo_model import OctoModel
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-base-1.5")
print(model.get_pretty_spec())
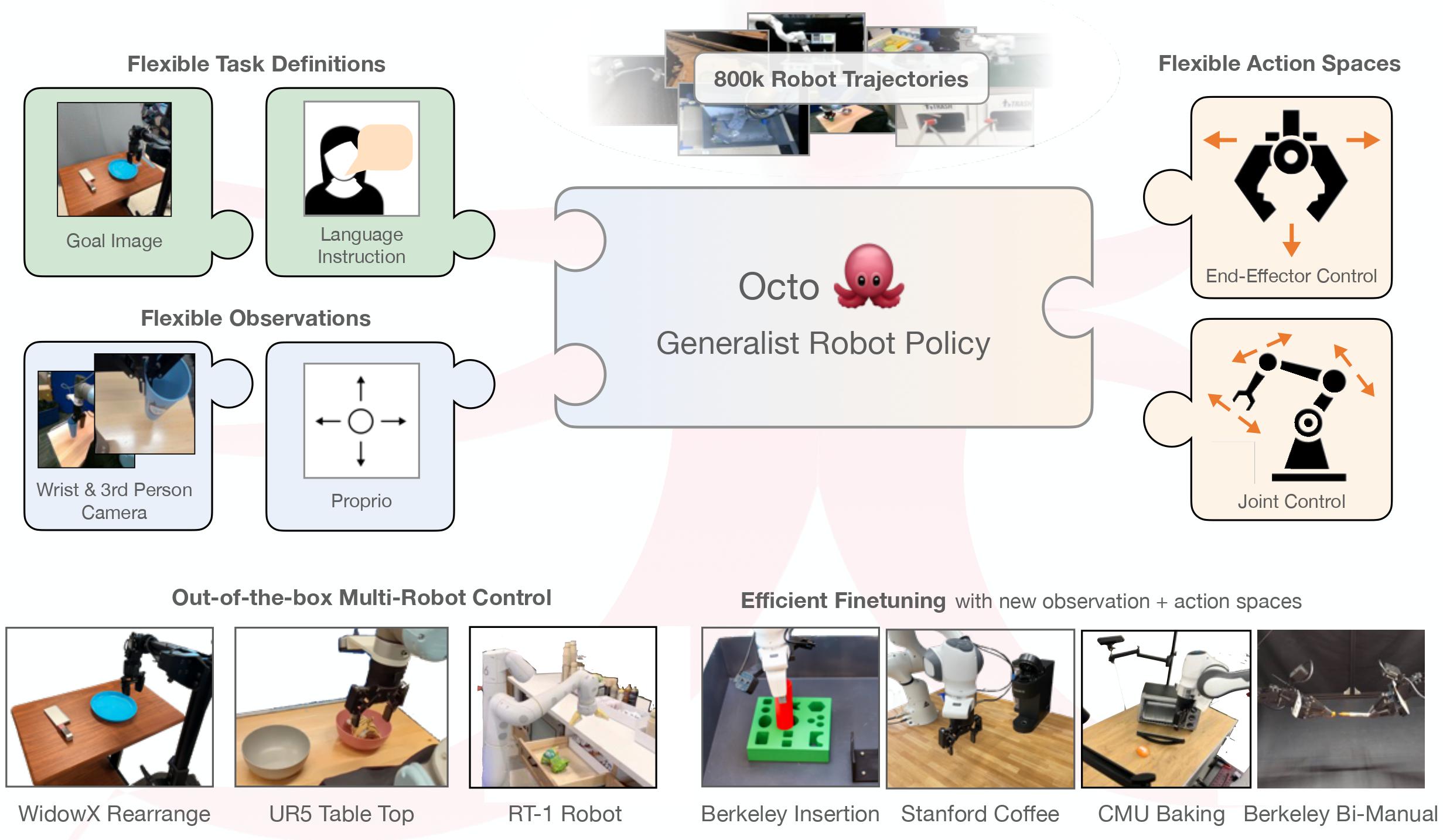
Octo 开箱即用支持多个 RGB 相机输入,可以控制各种机器人手臂, 并可以通过语言命令或目标图像进行指令。 Octo 在其 transformer 骨干网络中使用模块化注意力结构,使其能够有效地微调 以适应具有新感知输入、动作空间和形态的机器人设置,仅使用小规模目标域 数据集和可承受的计算资源。
安装
conda create -n octo python=3.10
conda activate octo
pip install -e .
pip install -r requirements.txt
对于 GPU:
pip install --upgrade "jax[cuda11_pip]==0.4.20" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
对于 TPU:
pip install --upgrade "jax[tpu]==0.4.20" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
有关安装 Jax 的更多详细信息,请参见 Jax Github 页面。
通过在调试数据集上微调来测试安装:
python scripts/finetune.py --config.pretrained_path=hf://rail-berkeley/octo-small-1.5 --debug
检查点
您可以在这里找到预训练的 Octo 检查点。 目前我们提供以下模型版本:
| 模型 | 在 1 个 NVIDIA 4090 上的推理 | 大小 |
|---|---|---|
| Octo-Base | 13 次迭代/秒 | 9300万参数 |
| Octo-Small | 17 次迭代/秒 | 2700万参数 |
示例
我们提供了简单的示例脚本,展示如何使用和微调 Octo 模型, 以及如何独立使用我们的数据加载器。我们提供以下示例:
| Octo 推理 | 加载和运行预训练 Octo 模型的最小示例 |
| Octo 微调 | 在具有新观察和动作空间的小型数据集上微调预训练 Octo 模型的最小示例 |
| Octo 模拟 | 在 Gym 环境中运行预训练 Octo 策略的模拟 |
| Octo 机器人评估 | 在真实 WidowX 机器人上评估预训练 Octo 模型 |
| OpenX 数据加载器介绍 | 我们的 Open X-Embodiment 数据加载器功能演示 |
| OpenX PyTorch 数据加载器 | 独立的 PyTorch 版 Open X-Embodiment 数据加载器 |
Octo 预训练
要在 80 万个机器人轨迹上重现我们的 Octo 预训练,运行:
python scripts/train.py --config scripts/configs/octo_pretrain_config.py:<size> --name=octo --config.dataset_kwargs.oxe_kwargs.data_dir=... --config.dataset_kwargs.oxe_kwargs.data_mix=oxe_magic_soup ...
要从 Open X-Embodiment 数据集 下载预训练数据集, 安装 rlds_dataset_mod 包 并运行 prepare_open_x.sh 脚本。 预处理后的数据集总大小约为 1.2TB。
我们使用 TPUv4-128 pod 进行预训练,Octo-S 模型用时 8 小时,Octo-B 模型用时 14 小时。
Octo 微调
我们提供了一个最小示例用于在新的观察和动作空间上进行微调。
我们还提供了一个更高级的微调脚本,允许您通过配置文件更改超参数并记录微调 指标。要运行高级微调,使用:
python scripts/finetune.py --config.pretrained_path=hf://rail-berkeley/octo-small-1.5
我们提供三种微调模式,根据模型保持冻结的部分而定:head_only、head_mlp_only 和 full 用于微调整个模型。
此外,可以指定要微调的任务类型:image_conditioned、language_conditioned 或 multimodal 用于两者兼有。
例如,要仅使用图像输入微调整个 transformer,使用:
--config=finetune_config.py:full,image_conditioned。
Octo 评估
加载和运行训练好的 Octo 模型非常简单:
from octo.model import OctoModel
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-small-1.5")
task = model.create_tasks(texts=["拿起勺子"])
action = model.sample_actions(observation, task, rng=jax.random.PRNGKey(0))
我们提供了在模拟 Gym 环境中以及在真实 WidowX 机器人上评估 Octo 的示例。
要在您自己的环境中进行评估,只需将其包装在 Gym 接口中,并按照评估环境 README中的说明进行操作。
代码结构
| 文件 | 描述 | |
|---|---|---|
| 超参数 | config.py | 定义训练运行的所有超参数。 |
| 预训练循环 | train.py | 主要预训练脚本。 |
| 微调循环 | finetune.py | 主要微调脚本。 |
| 数据集 | dataset.py | 用于创建单一/交错数据集和数据增强的函数。 |
| 分词器 | tokenizers.py | 将图像/文本输入编码为标记的分词器。 |
| Octo 模型 | octo_model.py | 与 Octo 模型交互的主要入口点:加载、保存和推理。 |
| 模型架构 | octo_module.py | 结合标记排序、transformer 主干和读出头。 |
| 可视化 | visualization_lib.py | 用于离线定性和定量评估的工具。 |
常见问题
观察字典中的 timestep_pad_mask 是什么?
timestep_pad_mask 指示应该关注哪些观察,这在使用多个时间步的观察历史时很重要。Octo 使用大小为 2 的历史窗口进行训练,这意味着模型可以使用当前观察和前一个观察来预测动作。然而,在轨迹的最开始,没有前一个观察,所以我们需要在相应的索引处设置 timestep_pad_mask=False。如果您使用窗口大小为 1 的 Octo,timestep_pad_mask 应该始终只是 [True],表示窗口中唯一的观察应该被关注。请注意,如果您使用 HistoryWrapper 包装您的机器人环境(参见 gym_wrappers.py),timestep_pad_mask 键将自动添加到观察字典中。
观察字典中的 pad_mask_dict 是什么?
虽然 timestep_pad_mask 在时间步级别指示应该关注哪些观察,但 pad_mask_dict 指示在单个时间步内应该关注观察的哪些元素。例如,对于没有语言标签的数据集,pad_mask_dict["language_instruction"] 被设置为 False。对于没有手腕摄像头的数据集,pad_mask_dict["image_wrist"] 被设置为 False。为方便起见,如果观察字典中缺少某个键,相当于将该键的 pad_mask_dict 设置为 False。
model.sample_actions([...]) 是否返回解决任务的完整轨迹?
Octo 使用大小为 4 的动作分块进行预训练,这意味着它一次预测接下来的 4 个动作。您可以选择在采样新动作之前执行所有这些动作,或者只执行第一个动作然后采样新动作(也称为滚动时域控制)。您还可以做一些更高级的操作,比如时间集成。
1.5 版本更新
- 通过在上下文窗口的每个时间步重复语言标记,改进了视觉和语言标记之间的交叉注意力。
- 使用 GPT-3.5 对数据中的语言指令进行了改写增强。
- 错误修复:
- 由于与层归一化不兼容,关闭了扩散头中的 dropout。
- 修复了注意力掩码中的一个差一错误。
- 修复了不同图像增强没有获得新随机种子的问题。
引用
@inproceedings{octo_2023,
title={Octo: An Open-Source Generalist Robot Policy},
author = {{Octo Model Team} and Dibya Ghosh and Homer Walke and Karl Pertsch and Kevin Black and Oier Mees and Sudeep Dasari and Joey Hejna and Charles Xu and Jianlan Luo and Tobias Kreiman and {You Liang} Tan and Pannag Sanketi and Quan Vuong and Ted Xiao and Dorsa Sadigh and Chelsea Finn and Sergey Levine},
booktitle = {Proceedings of Robotics: Science and Systems},
address = {Delft, Netherlands},
year = {2024},
}











