
 访问官网
访问官网 Github
Github 文档
文档OpenVINO™模型服务器
模型服务器托管模型并通过标准网络协议使其可供软件组件访问:客户端向模型服务器发送请求,模型服务器执行模型推理并将响应发送回客户端。模型服务器为高效模型部署提供了许多优势:
- 远程推理使轻量级客户端只需具备执行API调用到边缘或云部署的必要功能。
- 应用程序独立于模型框架、硬件设备和基础设施。
- 支持REST或gRPC调用的任何编程语言的客户端应用程序都可以用于在模型服务器上远程运行推理。
- 客户端需要较少更新,因为客户端库很少发生变化。
- 模型拓扑和权重不直接暴露给客户端应用程序,更易于控制对模型的访问。
- 适用于基于微服务的应用程序和云环境部署的理想架构 - 包括Kubernetes和OpenShift集群。
- 通过横向和纵向推理扩展实现高效资源利用。
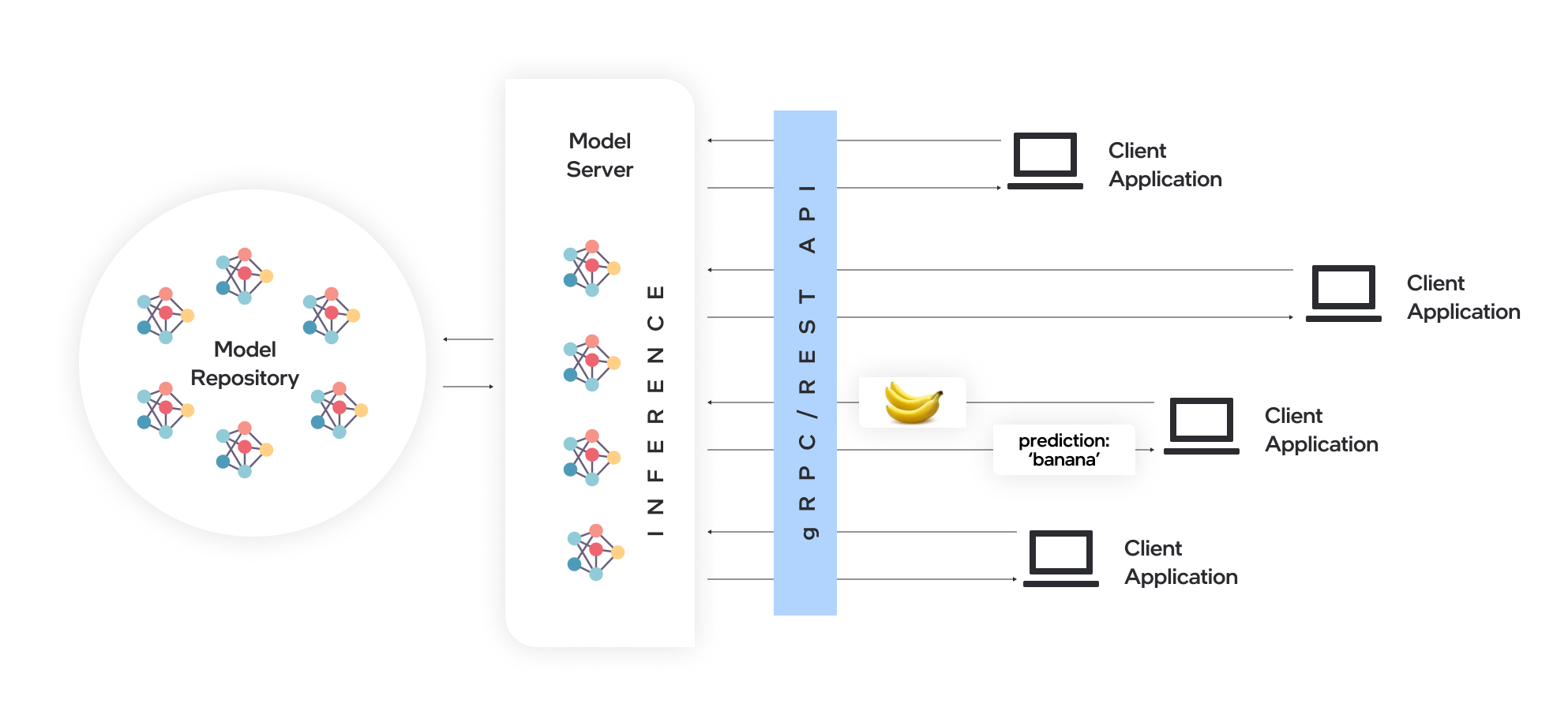
OpenVINO™模型服务器(OVMS)是一个高性能的模型服务系统。它使用C++实现以实现可扩展性,并针对Intel架构部署进行了优化,该模型服务器使用与TensorFlow Serving和KServe相同的架构和API,同时应用OpenVINO进行推理执行。推理服务通过gRPC或REST API提供,使部署新算法和AI实验变得容易。
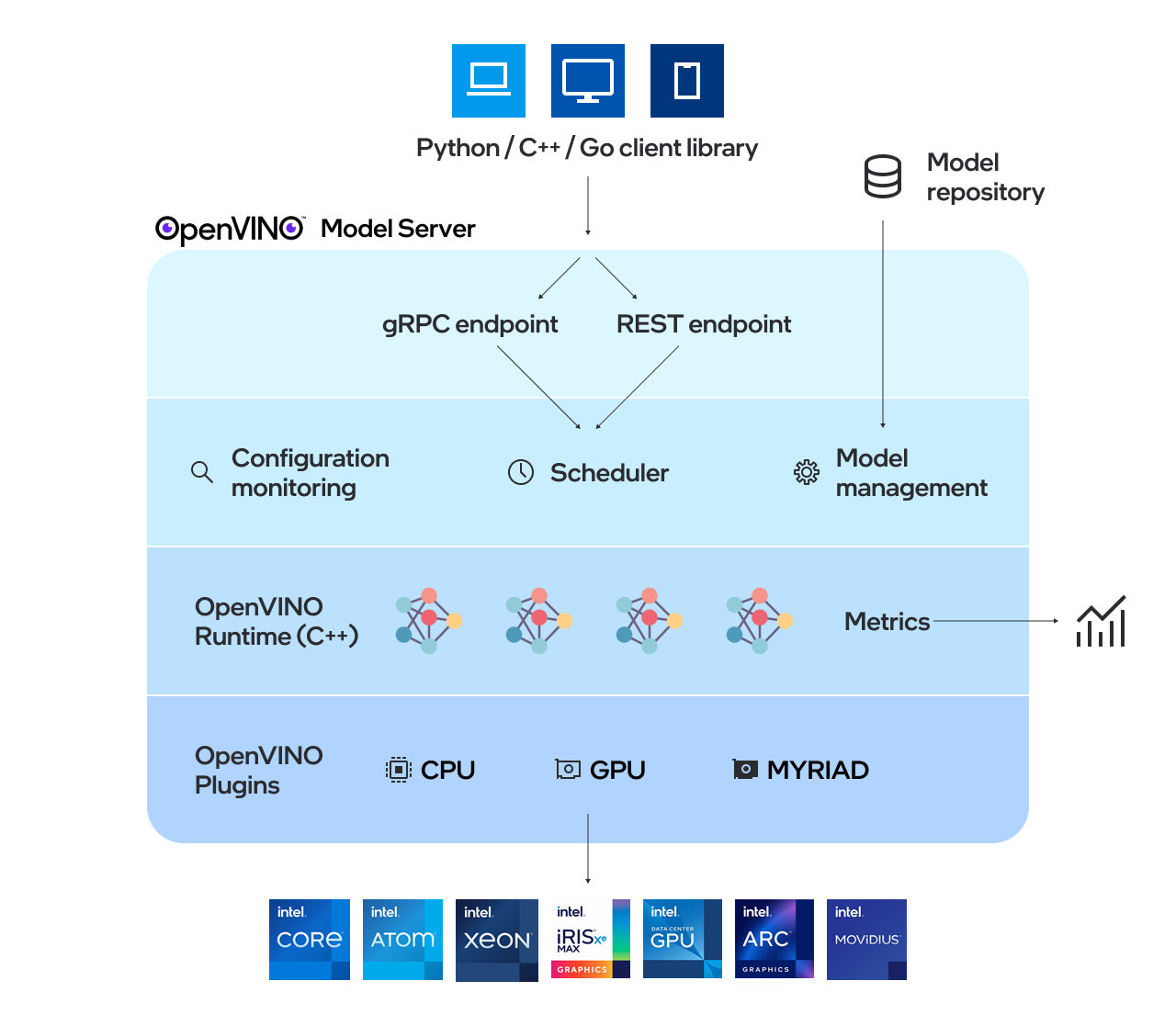
服务器使用的模型需要本地存储或由对象存储服务远程托管。有关更多详细信息,请参阅准备模型仓库文档。模型服务器可在Docker容器内、裸机上和Kubernetes环境中工作。 从快速入门指南开始使用OpenVINO模型服务器,或探索模型服务器功能。
阅读发行说明以了解新功能。
主要特性:
- [新功能] 通过OpenAI API高效生成文本 - 预览版
- Python代码执行
- gRPC流式处理
- MediaPipe图形服务
- 模型管理 - 包括模型版本控制和运行时模型更新
- 动态模型输入
- 有向无环图调度器以及DAG管道中的自定义节点
- 指标 - 与Prometheus标准兼容的指标
- 支持多种框架,如TensorFlow、PaddlePaddle和ONNX
- 支持AI加速器
注意: OVMS已在RedHat和Ubuntu上进行了测试。最新公开发布的docker镜像基于Ubuntu和UBI。 它们存储在:
- Dockerhub
- RedHat生态系统目录
运行OpenVINO模型服务器
在我们的快速入门指南中可以找到如何使用OpenVINO模型服务器的演示。 有关在各种场景中使用模型服务器的更多信息,您可以查看以下指南:
-
模型仓库配置
-
部署选项
-
性能调优
-
有向无环图调度器
-
自定义节点开发
-
服务有状态模型
-
使用Kubernetes Helm Chart部署
-
使用Kubernetes Operator部署
-
使用二进制输入数据
参考
-
OpenVINO™
-
TensorFlow Serving
-
gRPC
-
RESTful API
-
基准测试结果
-
跨多种架构加速和扩展AI推理操作 - 网络研讨会录像
-
OpenVINO模型服务器C++的新特性
-
Capital Health利用AI改善中风护理 - 使用案例示例
联系
如果您有问题、功能请求或错误报告,请随时提交Github问题。
* 其他名称和品牌可能是其他所有者的财产。











