
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文![]()
[![ci build status][ci badge]][ci url] [![codecov][codecov badge]][codecov url] ![supported languages][supported languages badge] [![Kotlin platforms badge][Kotlin platforms badge]][Kotlin platforms url] [![license badge][license badge]][license url] [![javadoc][javadoc badge]][javadoc url] [![Maven Central][Maven Central badge]][Maven Central] [![Download][lingua version badge]][lingua download url]
1. What does this library do?
Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a preprocessing step for linguistic data in natural language processing applications such as text classification and spell checking. Other use cases, for instance, might include routing e-mails to the right geographically located customer service department, based on the e-mails' languages.
2. Why does this library exist?
Language detection is often done as part of large machine learning frameworks or natural language processing applications. In cases where you don't need the full-fledged functionality of those systems or don't want to learn the ropes of those, a small flexible library comes in handy.
So far, three other comprehensive open source libraries working on the JVM for this task are [Apache Tika], [Apache OpenNLP] and [Optimaize Language Detector]. Unfortunately, especially the latter has three major drawbacks:
- Detection only works with quite lengthy text fragments. For very short text snippets such as Twitter messages, it doesn't provide adequate results.
- The more languages take part in the decision process, the less accurate are the detection results.
- Configuration of the library is quite cumbersome and requires some knowledge about the statistical methods that are used internally.
Lingua aims at eliminating these problems. It nearly doesn't need any configuration and yields pretty accurate results on both long and short text, even on single words and phrases. It draws on both rule-based and statistical methods but does not use any dictionaries of words. It does not need a connection to any external API or service either. Once the library has been downloaded, it can be used completely offline.
3. Which languages are supported?
Compared to other language detection libraries, Lingua's focus is on quality over quantity, that is, getting detection right for a small set of languages first before adding new ones. Currently, the following 75 languages are supported:
- A
- Afrikaans
- Albanian
- Arabic
- Armenian
- Azerbaijani
- B
- Basque
- Belarusian
- Bengali
- Norwegian Bokmal
- Bosnian
- Bulgarian
- C
- Catalan
- Chinese
- Croatian
- Czech
- D
- Danish
- Dutch
- E
- English
- Esperanto
- Estonian
- F
- Finnish
- French
- G
- Ganda
- Georgian
- German
- Greek
- Gujarati
- H
- Hebrew
- Hindi
- Hungarian
- I
- Icelandic
- Indonesian
- Irish
- Italian
- J
- Japanese
- K
- Kazakh
- Korean
- L
- Latin
- Latvian
- Lithuanian
- M
- Macedonian
- Malay
- Maori
- Marathi
- Mongolian
- N
- Norwegian Nynorsk
- P
- Persian
- Polish
- Portuguese
- Punjabi
- R
- Romanian
- Russian
- S
- Serbian
- Shona
- Slovak
- Slovene
- Somali
- Sotho
- Spanish
- Swahili
- Swedish
- T
- Tagalog
- Tamil
- Telugu
- Thai
- Tsonga
- Tswana
- Turkish
- U
- Ukrainian
- Urdu
- V
- Vietnamese
- W
- Welsh
- X
- Xhosa
- Y
- Yoruba
- Z
- Zulu
4. How good is it?
Lingua is able to report accuracy statistics for some bundled test data available for each supported language. The test data for each language is split into three parts:
- a list of single words with a minimum length of 5 characters
- a list of word pairs with a minimum length of 10 characters
- a list of complete grammatical sentences of various lengths
Both the language models and the test data have been created from separate documents of the [Wortschatz corpora] offered by Leipzig University, Germany. Data crawled from various news websites have been used for training, each corpus comprising one million sentences. For testing, corpora made of arbitrarily chosen websites have been used, each comprising ten thousand sentences. From each test corpus, a random unsorted subset of 1000 single words, 1000 word pairs and 1000 sentences has been extracted, respectively.
Given the generated test data, I have compared the detection results of Lingua, Apache Tika, Apache OpenNLP and Optimaize Language Detector using parameterized JUnit tests running over the data of Lingua's supported 75 languages. Languages that are not supported by the other libraries are simply ignored for those during the detection process.
Each of the following sections contains two plots. The bar plot shows the detailed accuracy results for each supported language. The box plot illustrates the distributions of the accuracy values for each classifier. The boxes themselves represent the areas which the middle 50 % of data lie within. Within the colored boxes, the horizontal lines mark the median of the distributions.
4.1 Single word detection
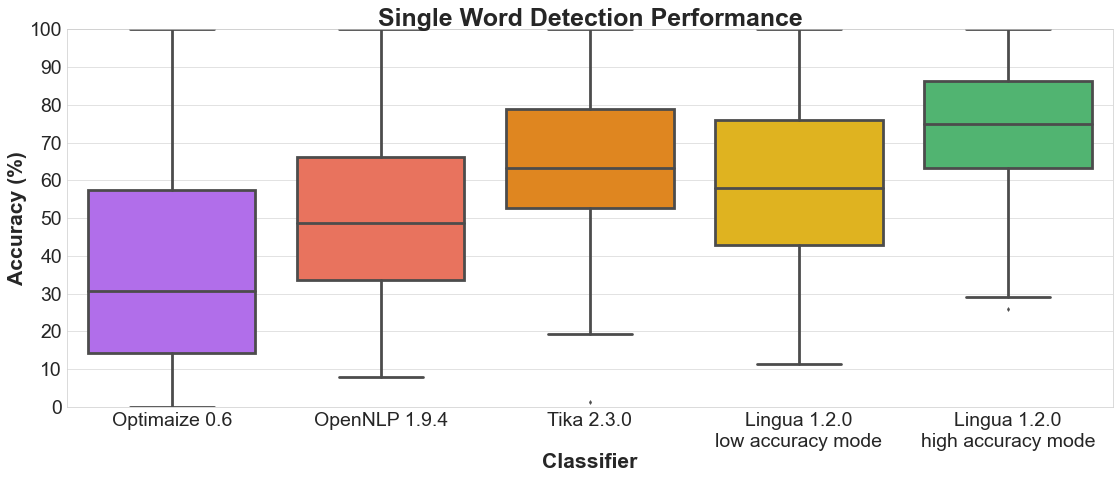
Bar plot

4.2 Word pair detection
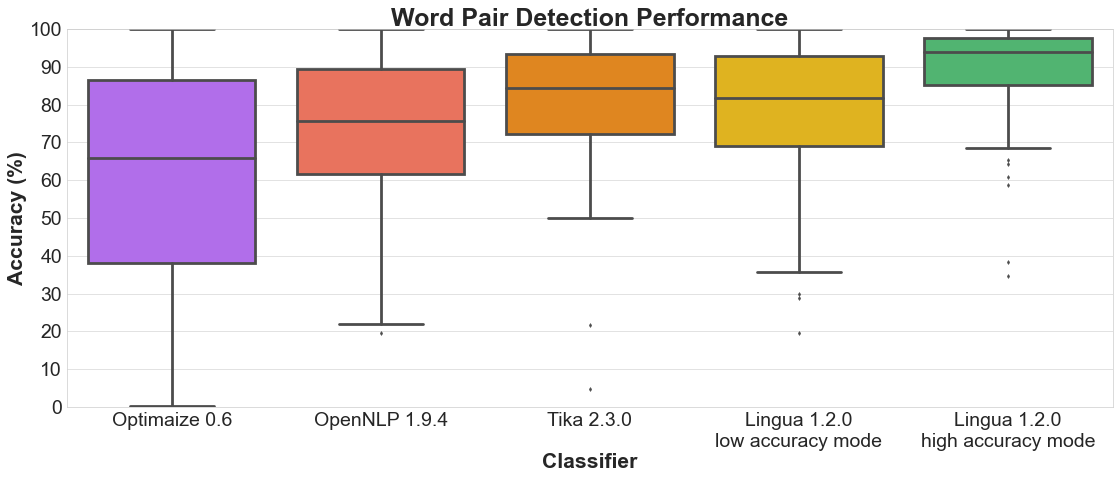
Bar plot

4.3 Sentence detection
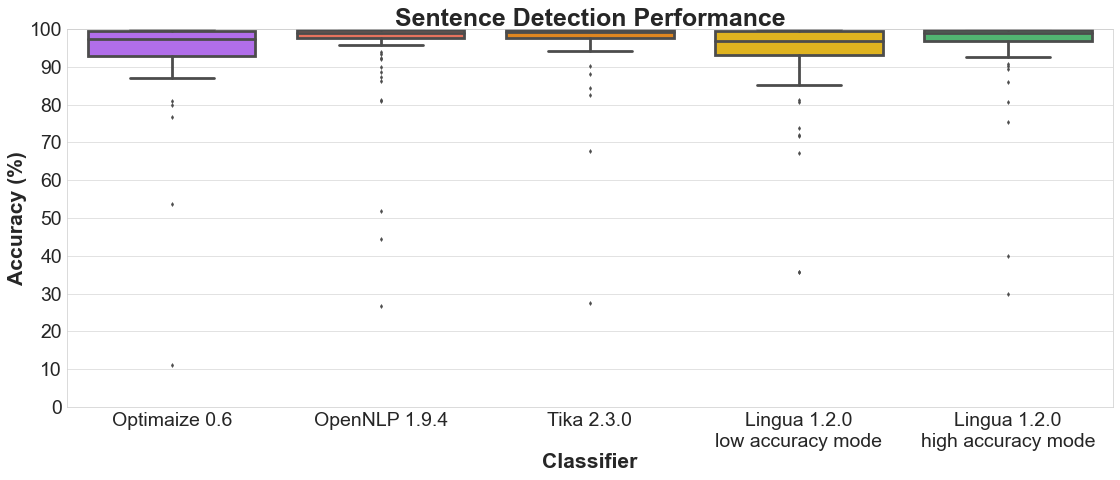
Bar plot

4.4 Average detection
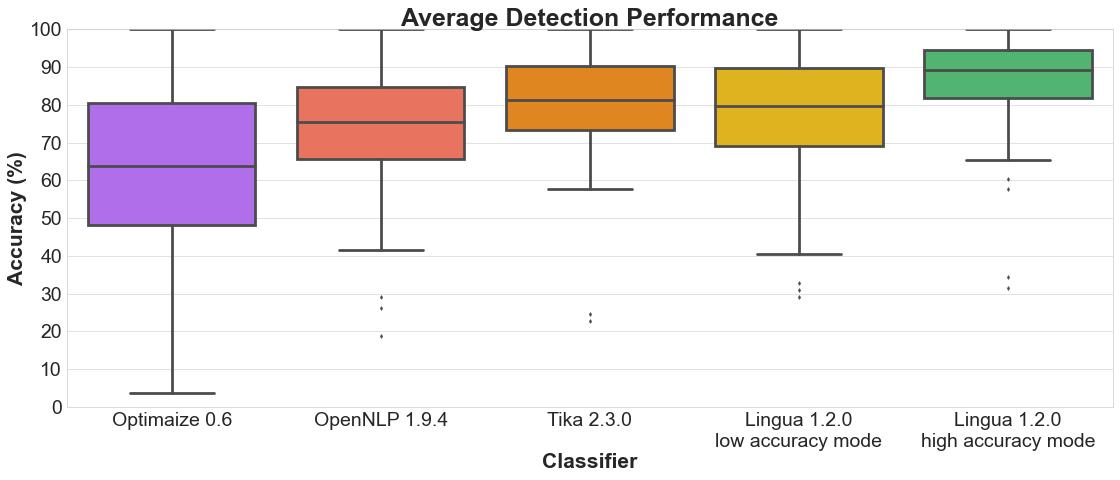
Bar plot

4.5 Mean, median and standard deviation
The table below shows detailed statistics for each language and classifier including mean, median and standard deviation.
Open table
| Language | Average | Single Words | Word Pairs | Sentences | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lingua (high accuracy mode) | Lingua (low accuracy mode) | Tika | OpenNLP | Optimaize | Lingua (high accuracy mode) | Lingua (low accuracy mode) | Tika | OpenNLP | Optimaize | Lingua (high accuracy mode) | Lingua (low accuracy mode) | Tika | OpenNLP | Optimaize | Lingua (high accuracy mode) | Lingua (low accuracy mode) | Tika | OpenNLP | Optimaize | |
| Afrikaans |  79 79 | 64 | 71 | 72 |  39 39 |  58 58 | 38 | 44 | 41 |  3 3 |  81 81 | 62 | 70 | 75 | 22 | 97 | 93 | 98 | 99 | 93 |
| Albanian | 88 | 80 | 79 | 71 | 70 | 69 | 54 | 54 | 40 | 38 | 95 | 86 | 84 | 73 | 73 | 100 | 99 | 99 | 100 | 98 |
| Arabic | 98 | 94 | 97 | 84 | 89 | 96 | 88 | 94 | 65 | 72 | 99 | 96 | 99 | 88 | 94 | 100 | 99 | 100 | 99 | 100 |
| Armenian | 100 | 100 |  - - | 100 | - | 100 | 100 | - | 100 | - | 100 | 100 | - | 100 | - | 100 | 100 | - | 100 | - |
| Azerbaijani | 90 | 82 | - | 82 | - | 77 | 71 | - | 60 | - | 92 | 78 | - | 86 | - | 99 | 96 | - | 99 | - |
| Basque | 84 | 74 | 83 | 77 | 66 | 71 | | |||||||||||||











