
pix2pix
Torch 实现了从输入图像到输出图像的映射学习,例如:
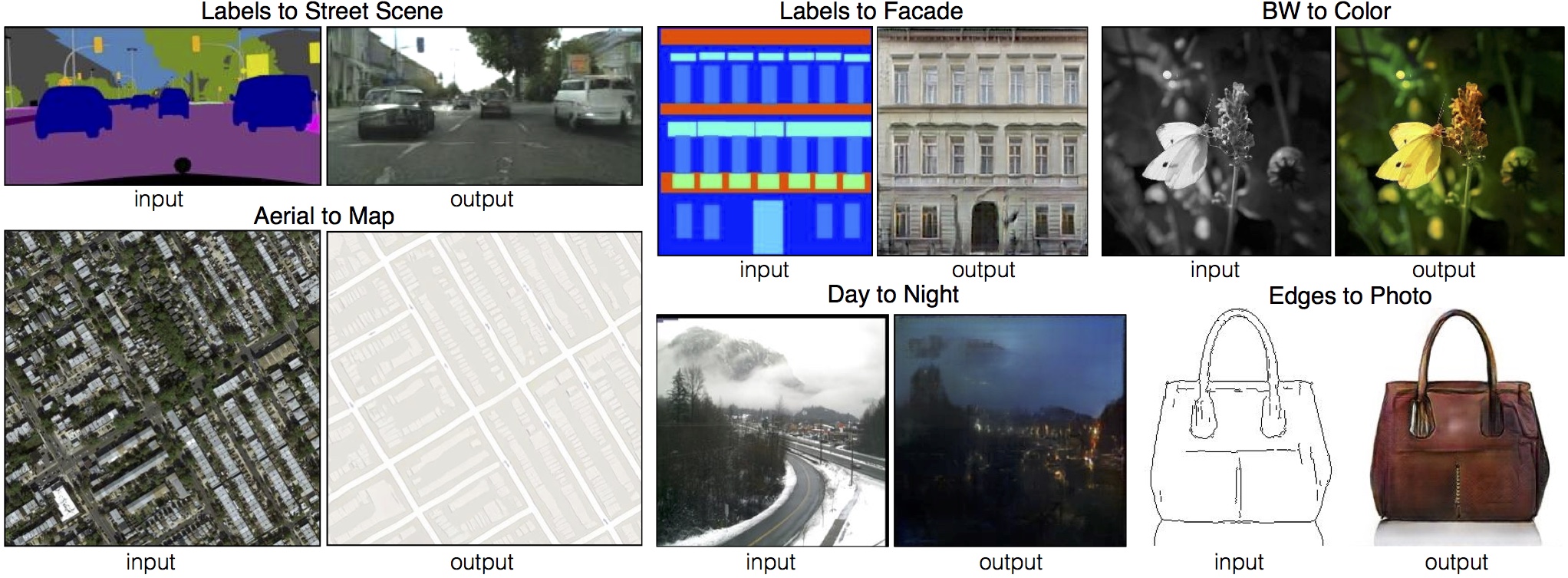
基于条件对抗网络的图像到图像翻译
Phillip Isola,Jun-Yan Zhu,Tinghui Zhou,Alexei A. Efros
CVPR,2017年。
在某些任务中,可以在较短时间内和小数据集上获得相当不错的结果。例如,为了学习生成立面图(如上图所示),我们仅在 400 张图像上训练了约 2 小时(使用一块 Pascal Titan X GPU)。然而,对于更难的问题,可能需要在更大的数据集上训练许多小时甚至几天。
注意:请查看我们的 PyTorch 版本的 pix2pix 和 CycleGAN 实现。PyTorch 版本正在积极开发中,其效果可以与这个 Torch 版本相媲美甚至更好。
设置
先决条件
- Linux 或 OSX
- NVIDIA GPU + CUDA CuDNN(CPU 模式和不使用 CuDNN 的 CUDA 可能可以通过少量修改工作,但未经测试)
开始使用
- 从 https://github.com/torch/distro 安装 torch 及其依赖项
- 安装 torch 包
nngraph和display
luarocks install nngraph
luarocks install https://raw.githubusercontent.com/szym/display/master/display-scm-0.rockspec
- 克隆此仓库:
git clone git@github.com:phillipi/pix2pix.git
cd pix2pix
- 下载数据集(例如 CMP Facades):
bash ./datasets/download_dataset.sh facades
- 训练模型
DATA_ROOT=./datasets/facades name=facades_generation which_direction=BtoA th train.lua
- (仅 CPU)不使用 GPU 或 CUDNN 的相同训练命令。通过设置环境变量
gpu=0 cudnn=0强制仅使用 CPU
DATA_ROOT=./datasets/facades name=facades_generation which_direction=BtoA gpu=0 cudnn=0 batchSize=10 save_epoch_freq=5 th train.lua
- (可选)启动显示服务器以查看模型训练时的结果。(详见 Display UI)
th -ldisplay.start 8000 0.0.0.0
- 最后,测试模型:
DATA_ROOT=./datasets/facades name=facades_generation which_direction=BtoA phase=val th test.lua
测试结果将保存为 html 文件,路径为:./results/facades_generation/latest_net_G_val/index.html。
训练
DATA_ROOT=/path/to/data/ name=expt_name which_direction=AtoB th train.lua
将 AtoB 切换为 BtoA 以训练相反方向的翻译。
模型会保存到 ./checkpoints/expt_name(可通过在 train.lua 中传递 checkpoint_dir=your_dir 来更改保存路径)。
有关其他训练选项,请参见 train.lua 中的 opt。
测试
DATA_ROOT=/path/to/data/ name=expt_name which_direction=AtoB phase=val th test.lua
这将以 AtoB 方向运行名为 expt_name 的模型,对 /path/to/data/val 中的所有图像进行测试。
结果图像以及一个查看它们的网页将保存到 ./results/expt_name(可通过在 test.lua 中传递 results_dir=your_dir 来更改保存路径)。
有关其他测试选项,请参见 test.lua 中的 opt。
数据集
使用以下脚本下载数据集。一些数据集由其他研究人员收集。如果您使用这些数据,请引用他们的论文。
bash ./datasets/download_dataset.sh dataset_name
facades:来自 CMP Facades 数据集 的 400 张图像。[引用]cityscapes:来自 Cityscapes 训练集 的 2975 张图像。[引用]maps:从 Google Maps 抓取的 1096 张训练图像edges2shoes:来自 UT Zappos50K 数据集 的 5 万张训练图像。边缘由 HED 边缘检测器 + 后处理计算得出。 [引用]edges2handbags:来自 iGAN 项目 的 13.7 万张 Amazon 手袋图像。边缘由 HED 边缘检测器 + 后处理计算得出。[引用]night2day:来自 Transient Attributes 数据集 的约 2 万张自然场景图像[引用]。要训练day2night的 pix2pix 模型,您需要添加which_direction=BtoA。
模型
使用以下脚本下载预训练模型。下载完成后,需要重命名模型(例如,将 facades_label2image 重命名为 /checkpoints/facades/latest_net_G.t7)。
bash ./models/download_model.sh model_name
facades_label2image(标签 -> 外立面): 在 CMP Facades 数据集上训练。cityscapes_label2image(标签 -> 街景): 在 Cityscapes 数据集上训练。cityscapes_image2label(街景 -> 标签): 在 Cityscapes 数据集上训练。edges2shoes(轮廓 -> 照片): 在 UT Zappos50K 数据集上训练。edges2handbags(轮廓 -> 照片): 在亚马逊手袋图像上训练。day2night(白天场景 -> 夜晚场景): 在大约 100 个 webcams 上训练。
设置训练和测试数据
生成配对数据
我们提供了一个 Python 脚本,用于生成成对的训练数据 {A,B},其中 A 和 B 是同一场景的不同描绘。例如,这些可能是 {标签图,照片} 或 {黑白图,彩色图} 对。然后我们可以学习将 A 转换为 B 或 B 转换为 A:
创建文件夹 /path/to/data,并在其中建立子文件夹 A 和 B。A 和 B 应各自有 train、val、test 等子文件夹。在 /path/to/data/A/train 中放入风格 A 的训练图像。在 /path/to/data/B/train 中放入相应风格 B 的图像。其他数据分组 (val,test 等) 重复相同步骤。
配对的图像 {A,B} 必须具有相同的大小和相同的文件名,例如 /path/to/data/A/train/1.jpg 应对应 /path/to/data/B/train/1.jpg。
数据按此格式准备好后,调用:
python scripts/combine_A_and_B.py --fold_A /path/to/data/A --fold_B /path/to/data/B --fold_AB /path/to/data
这将把每一对图像 (A,B) 合并为一个单一图像文件,准备进行训练。
关于颜色化的注意事项
颜色化不需要运行 combine_A_and_B.py。你需要准备一些自然图像,并在脚本中设置 preprocess=colorization。程序会在训练过程中自动将每个 RGB 图像转换为 Lab 色彩空间,并创建 L -> ab 图像对。同时设置 input_nc=1 和 output_nc=2。
提取轮廓
我们提供了 Python 和 Matlab 脚本来从照片中提取粗略轮廓。运行 scripts/edges/batch_hed.py 以计算 HED 轮廓。运行 scripts/edges/PostprocessHED.m 以使用额外的后处理步骤简化轮廓。更多细节请查看代码文档。
在 Cityscapes 上评估 Labels2Photos
我们提供了在 Cityscapes 验证 集上运行 Labels2Photos 任务评估的脚本。假设你已经在系统中安装了 caffe(和 pycaffe)。如果没有,请参阅 官网 的安装说明。caffe 安装成功后,通过运行以下命令下载预训练的 FCN-8s 语义分割模型(512MB)
bash ./scripts/eval_cityscapes/download_fcn8s.sh
然后确保 ./scripts/eval_cityscapes/ 在系统的 Python 路径中。如果没有,请运行以下命令添加
export PYTHONPATH=${PYTHONPATH}:./scripts/eval_cityscapes/
现在你可以运行以下命令来评估你的预测:
python ./scripts/eval_cityscapes/evaluate.py --cityscapes_dir /path/to/original/cityscapes/dataset/ --result_dir /path/to/your/predictions/ --output_dir /path/to/output/directory/
存储在 --result_dir 下的图像应包含你的模型在 Cityscapes 验证 集上的预测结果,并保留原始 Cityscapes 命名规范(例如 frankfurt_000001_038418_leftImg8bit.png)。脚本将在 --output_dir 下输出一个包含指标的文本文件。
进一步说明:我们的预训练 FCN 模型不适用于原始分辨率(1024x2048)的 Cityscapes,因为它是在 256x256 的图像上训练的,然后在训练过程中上采样到 1024x2048。训练时调整大小的目的是 1) 保持标签图在原始高分辨率下不变,2) 避免修改标准的 FCN 训练代码和 Cityscapes 的架构。在测试时,你需要生成 256x256 的结果。我们的测试代码将在将结果输入预训练 FCN 模型之前,自动将结果上采样到 1024x2048。输出分辨率为 1024x2048,并将与 1024x2048 的真实标签进行比较。你不需要调整真实标签的大小。验证一切是否正确的最佳方法是首先再现论文中的真实图像数据。为此,你需要将原始/真实的 Cityscapes 图像(不是标签)调整大小至 256x256,然后将其输入评估代码。
显示界面
可选:若要在训练和测试期间显示图像,请使用 display package。
- 使用以下命令安装:
luarocks install https://raw.githubusercontent.com/szym/display/master/display-scm-0.rockspec - 然后启动服务器:
th -ldisplay.start - 在浏览器中打开此 URL:http://localhost:8000
默认情况下,服务器监听 localhost。传递 0.0.0.0 以允许外部连接到任何接口:
th -ldisplay.start 8000 0.0.0.0
然后在浏览器中打开 http://(hostname):(port)/ 加载远程桌面。
默认情况下,L1 误差绘制到显示界面。将环境变量 display_plot 设置为由 errL1、errG 和 errD 组成的逗号分隔列表,以可视化 L1、生成器和判别器的误差。例如,要绘制生成器和判别器误差到显示界面而非默认的 L1 误差,请设置 display_plot="errG,errD"。
引用
如果你在研究中使用了此代码,请引用我们的论文 基于条件对抗网络的图像到图像翻译。
@article{pix2pix2017,
title={基于条件对抗网络的图像到图像转换},
author={Isola, Phillip 和 Zhu, Jun-Yan 和 Zhou, Tinghui 和 Efros, Alexei A},
journal={CVPR},
year={2017}
}
猫咪论文合集
如果你喜欢猫咪,并且喜欢阅读炫酷的图形、视觉和学习类论文,请查看猫咪论文合集:
[Github] [网页]
致谢
代码大量参考了DCGAN。数据加载器经过DCGAN和Context-Encoder的修改。









