
 访问官网
访问官网 Github
Githubrga:ripgrep,但还可以搜索PDF、电子书、Office文档、zip、tar.gz等文件
rga是一个面向行的搜索工具,允许你在多种文件类型中查找正则表达式。rga封装了强大的ripgrep,使其能够搜索pdf、docx、sqlite、jpg、电影字幕(mkv、mp4)等文件。



更多详情,请参阅这篇介绍性博文:https://phiresky.github.io/blog/2019/rga--ripgrep-for-zip-targz-docx-odt-epub-jpg/
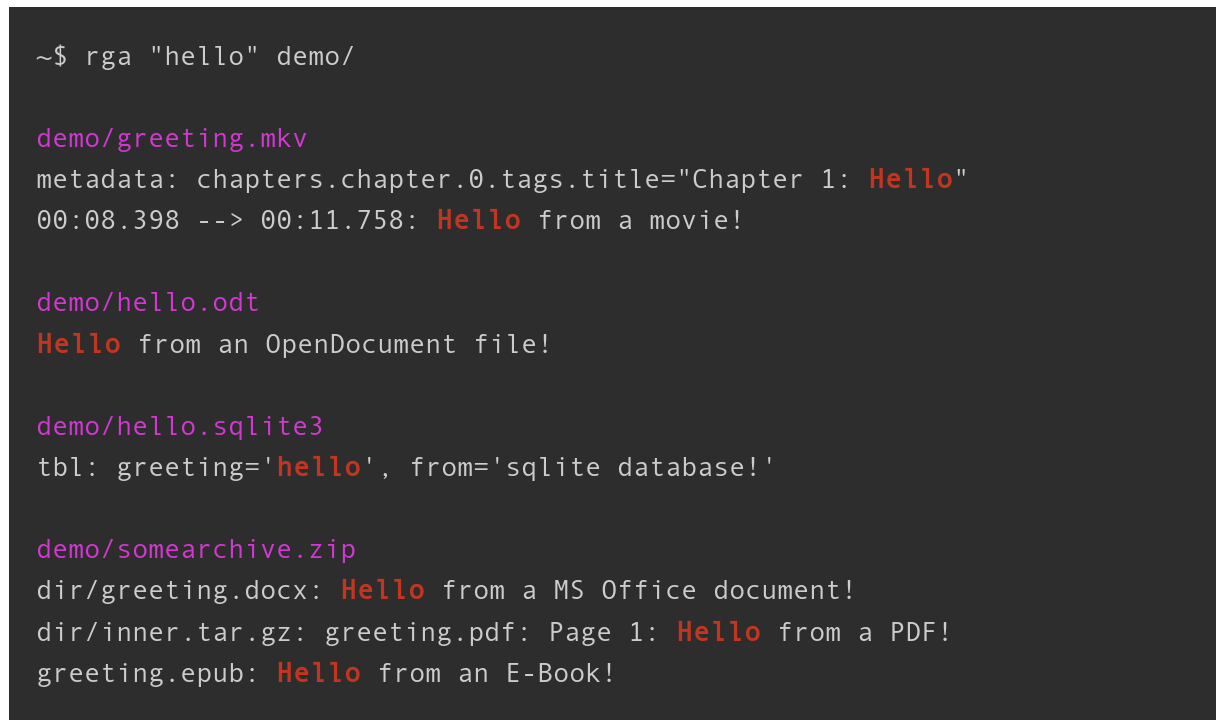
rga会递归地深入归档文件,并在它知道的每种文件类型中匹配文本。
这里是一个包含不同文件类型的示例目录:
demo/
├── greeting.mkv
├── hello.odt
├── hello.sqlite3
└── somearchive.zip
├── dir
│ ├── greeting.docx
│ └── inner.tar.gz
│ └── greeting.pdf
└── greeting.epub
与fzf集成

有关将rga与fzf集成的说明,请参阅wiki。
安装
Linux x64、macOS和Windows的二进制文件可在GitHub Releases中获取。
Linux
Arch Linux
pacman -S ripgrep-all
Nix
nix-env -iA nixpkgs.ripgrep-all
基于Debian的系统
下载rga二进制文件并通过以下方式获取依赖项:
apt install ripgrep pandoc poppler-utils ffmpeg
如果您的软件源中没有ripgrep,请从这里获取。
rga将在$PATH和其所在目录中搜索它调用的所有二进制文件。
Windows
请注意,通过chocolatey或scoop安装是唯一支持的下载方法。如果您手动从releases下载二进制文件,将无法获得依赖项(例如来自poppler的pdftotext)。
如果出现"VCRUNTIME140.DLL找不到"等错误,需要安装vc_redist.x64.exe。
Chocolatey
choco install ripgrep-all
Scoop
scoop install rga
Homebrew/Linuxbrew
可以使用Homebrew安装rga:
brew install rga
安装非必需但非常有用的依赖项:
brew install pandoc poppler ffmpeg
MacPorts
也可以通过MacPorts在macOS上安装rga:
sudo port install ripgrep-all
从源代码编译
rga应该可以用稳定版Rust(v1.75.0+,用rustc --version检查)编译。要构建它,请运行以下命令(或在您的操作系统中的等效命令):
~$ apt install build-essential pandoc poppler-utils ffmpeg ripgrep cargo
~$ cargo install --locked ripgrep_all
~$ rga --version # 现在应该可以工作了
可用适配器
rga使用适配各种文件格式的"适配器"工作。它集成了一些适配器:
rga --rga-list-adapters
您还可以添加自定义适配器。更多信息请参阅wiki。
适配器:
-
pandoc 使用pandoc将二进制/不可读的文本文档转换为纯markdown格式文本 运行:pandoc --from= --to=plain --wrap=none --markdown-headings=atx
扩展名:.epub, .odt, .docx, .fb2, .ipynb, .html, .htm -
poppler 使用pdftotext(来自poppler-utils)从PDF文件中提取纯文本 运行:pdftotext - -
扩展名:.pdf
MIME类型:application/pdf -
postprocpagebreaks 为指定页面分隔符为ASCII页面分隔字符的输入文件的每行添加页码。 主要供poppler适配器内部使用。
扩展名:.asciipagebreaks -
ffmpeg 使用ffmpeg提取视频元数据/章节、字幕、歌词和其他元数据
扩展名:.mkv, .mp4, .avi, .mp3, .ogg, .flac, .webm -
zip 将zip文件作为流读取并递归进入其内容
扩展名:.zip, .jar
MIME类型:application/zip -
decompress 将压缩文件作为流读取并对内容运行不同的提取器。
扩展名:.als, .bz2, .gz, .tbz, .tbz2, .tgz, .xz, .zst
MIME类型:application/gzip, application/x-bzip, application/x-xz, application/zstd -
tar 将tar文件作为流读取并递归进入其内容
扩展名:.tar -
sqlite 使用sqlite绑定将sqlite数据库转换为简单的纯文本格式
扩展名:.db, .db3, .sqlite, .sqlite3
MIME类型:application/x-sqlite3
以下适配器默认禁用,可以使用'--rga-adapters=+foo,bar'启用:
- mail
读取邮箱/邮件文件并对内容和附件运行提取器。
扩展名:.mbox, .mbx, .eml
MIME类型:application/mbox, message/rfc822
用法:
rga [RGA选项] [RG选项] 模式 [路径 ...]
标志:
--rga-accurate
使用更精确但速度较慢的按 MIME 类型匹配
默认情况下,rga 将使用文件扩展名进行匹配。某些程序,如 sqlite3,完全不关心文件扩展名,因此用户有时会使用任意扩展名或不使用扩展名。使用此标志,rga 将尝试通过魔术字节(类似于
file工具)检测输入文件的 MIME 类型,并用它来选择适配器。检测仅在文件的前 8KiB 进行,因为我们并不总能在输入(如压缩文件中)中任意定位。
--rga-no-cache
禁用结果缓存
默认情况下,如果提取的文本足够小,rga 会将其缓存到数据库中。在 Linux 上,路径为 ${XDG_CACHE_DIR-~/.cache}/ripgrep-all;在 macOS 上,路径为 ~/Library/Caches/ripgrep-all;在 Windows 上,路径为 C:\Users\username\AppData\Local\ripgrep-all。这样,对同一组文件的重复搜索会快得多。如果传递此标志,所有缓存将被禁用。
-h, --help
打印帮助信息
--rga-list-adapters
列出所有已知适配器
--rga-print-config-schema
打印配置文件的 JSON Schema
--rg-help
显示 ripgrep 本身的帮助信息
--rg-version
显示 ripgrep 本身的版本
-V, --version
打印版本信息
选项:
--rga-adapters=<适配器>...
更改要使用的适配器及其优先级顺序(降序)
"foo,bar" 表示仅使用适配器 foo 和 bar。"-bar,baz" 表示使用除 bar 和 baz 之外的所有默认适配器。"+bar,baz" 表示使用所有默认适配器以及 bar 和 baz。
--rga-cache-compression-level=<压缩级别>
在存储到缓存数据库之前应用于适配器输出的 ZSTD 压缩级别
范围从 1 到 22 [默认值:12]
--rga-config-file=<配置文件路径>
--rga-max-archive-recursion=<最大压缩包递归深度>
递归进入压缩包的最大嵌套深度 [默认值:5]
--rga-cache-max-blob-len=<最大 blob 长度>
缓存的最大压缩大小
存储在缓存中的最长字节长度(压缩后)。超过此长度的适配器输出将不会被缓存,每次都会重新计算。
命令行允许的后缀:k M G [默认值:2000000]
--rga-cache-path=<路径>
存储缓存数据库的路径 [默认值:/home/phire/.cache/ripgrep-all]
-h 显示简明概述,--help 显示更多详细信息和高级选项。
这里未显示的所有其他选项都直接传递给 rg,特别是 [PATTERN] 和 [PATH ...]
配置
配置文件位置利用以下机制定义:
- 在 Linux 上使用 XDG 基本目录 和 XDG 用户目录 规范(例如:
~/.config/ripgrep-all/config.jsonc) - 在 Windows 上使用 Known Folder API(例如:
C:\Users\Alice\AppData\Roaming\ripgrep-all/config.jsonc) - 在 macOS 上遵循 Standard Directories 指南(例如:
~/Library/Application Support/ripgrep-all/config.jsonc)
开发
要启用调试日志:
export RUST_LOG=debug
export RUST_BACKTRACE=1
同时记得使用 --rga-no-cache 禁用缓存或清除缓存(macOS 上为 ~/Library/Caches/rga,其他 Unix 系统为 ~/.cache/rga,Windows 上为 C:\Users\username\AppData\Local\rga)以调试适配器。
Nix 和 Direnv
你可以使用提供的 flake.nix 来设置所有构建时和运行时依赖:











