
 访问官网
访问官网 Github
Github 文档
文档 论文
论文

让使用Prometheus的SLO变得易于管理、易于访问,并且对每个人都易于使用!
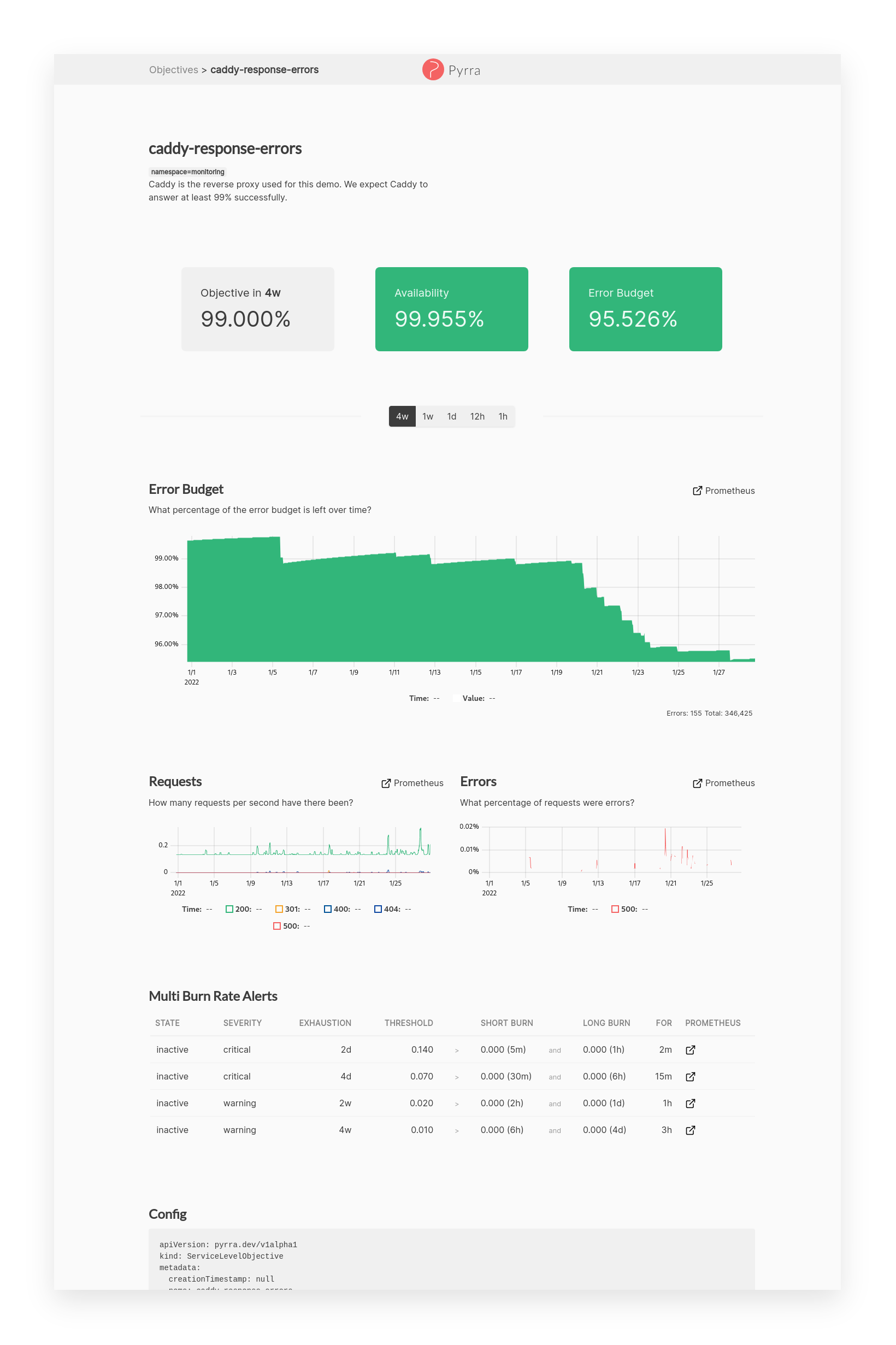
在Grafana中可视化SLO的仪表板:
观看2022年Prometheus日的5分钟闪电演讲:
特性
- 支持Kubernetes、Docker和从文件系统读取
- 告警:生成4个不同严重程度的多重燃烧率告警
- 列出所有服务水平目标的页面
- 通过名称和标签搜索
- 按剩余错误预算排序,快速查看最糟糕的情况
- 所有列可排序
- 查看和隐藏单个列
- 点击标签以筛选包含该标签的SLO
- 悬停时显示工具提示以获取额外上下文
- 服务水平目标详情页面
- 突出显示目标、可用性、错误预算这三个最重要的数字
- 图表显示错误预算随时间的变化
- 时间范围选择器以更改图表
- 在绝对和相对图表比例之间切换
- 底层服务的请求、错误、持续时间(RED)图表
- 多重燃烧率告警概览表
- 缓存Prometheus查询结果
- Thanos:禁用部分响应,降采样至5分钟和1小时
- connect-go和connect-web生成protobuf API
- 通过
--generic-rules生成Grafana仪表板
反馈与支持
如果您有任何反馈,请在本项目的GitHub讨论中开启一个讨论。 我们很乐意了解您的想法!
演示
查看我们在demo.pyrra.dev上的在线演示! Grafana仪表板演示可在demo.pyrra.dev/grafana上查看!
欢迎在那里尝试!
工作原理
Pyrra有三个组件,它们都通过一个二进制文件工作:
- UI显示SLO、错误预算、燃烧率等。
- API从后端(如Kubernetes)向UI传递SLO信息。
- 后端监视新的SLO对象,然后为每个对象创建Prometheus记录规则。
- 对于Kubernetes,有一个Kubernetes操作器可用
- 对于其他情况,有一个基于文件系统的操作器可用
为了让后端/操作器工作,需要以YAML格式提供SLO对象:
apiVersion: pyrra.dev/v1alpha1
kind: ServiceLevelObjective
metadata:
name: pyrra-api-errors
namespace: monitoring
labels:
prometheus: k8s
role: alert-rules
pyrra.dev/team: operations # 任何以'pyrra.dev/'为前缀的标签都将作为Prometheus标签传播,同时去掉前缀。
spec:
target: "99"
window: 2w
description: Pyrra的API请求和响应错误随时间变化,按路由分组。
indicator:
ratio:
errors:
metric: http_requests_total{job="pyrra",code=~"5.."}
total:
metric: http_requests_total{job="pyrra"}
grouping:
- route
根据您的操作模式,这些信息通过Kubernetes中的对象提供,或从静态文件中读取。
为了计算错误预算燃烧率,Pyrra随后会为每个SLO创建Prometheus记录规则。
对于上面的例子,将创建以下规则:
http_requests:increase2w
http_requests:burnrate3m
http_requests:burnrate15m
http_requests:burnrate30m
http_requests:burnrate1h
http_requests:burnrate3h
http_requests:burnrate12h
http_requests:burnrate2d
记录规则名称基于最初提供的指标。 记录规则包含必要的标签,以便在有多个可用规则时唯一标识记录规则。
在Kubernetes集群内运行
这种操作模式的示例可以在examples/kubernetes中找到。
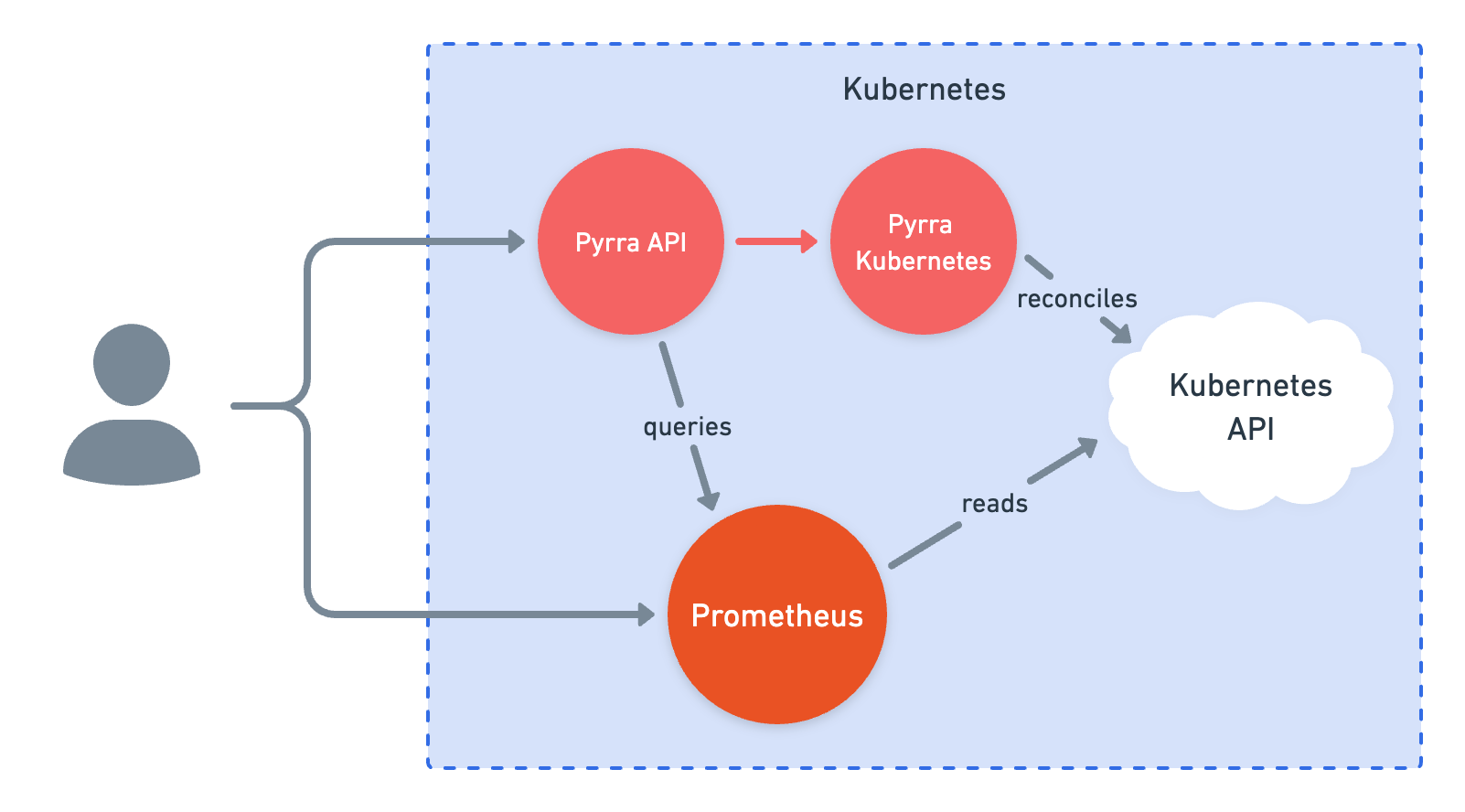
这里需要两个部署:一个用于API / UI,另一个用于操作器。对于第一个部署,使用api参数启动二进制文件。
当使用kubernetes参数启动二进制文件时,服务将监视apiserver的ServiceLevelObjectives。一旦检测到新的SLO,Pyrra将创建PrometheusRule对象,这些对象会被Prometheus Operator自动拾取。
如果您无法在集群内运行Prometheus Operator,可以在kubernetes参数后添加--config-map-mode=true标志。这将把每个记录规则保存在单独的ConfigMap中。
应用YAML
本仓库在examples/kubernetes/manifests文件夹中包含生成的YAML文件。 您可以使用以下命令立即将它们部署到集群中。
kubectl apply --server-side -f ./example/kubernetes/manifests/setup
kubectl apply --server-side -f ./example/kubernetes/manifests
kubectl apply --server-side -f ./example/kubernetes/manifests/slos
应用YAML并通过cert-manager验证webhook
本仓库在examples/kubernetes/manifests-webhook文件夹中包含更多生成的YAML文件。
这个示例部署还应用并自签名Issuer,并通过cert-manager请求证书, 以便Kubernetes APIServer可以连接到Pyrra,在将任何配置对象应用到集群之前对其进行验证。
kubectl apply --server-side -f ./example/kubernetes/manifests-webhook/setup
kubectl apply --server-side -f ./example/kubernetes/manifests-webhook
kubectl apply --server-side -f ./example/kubernetes/manifests-webhook/slos
kube-prometheus
底层的jsonnet代码被kube-prometheus项目导入。 如果您想安装包括Pyrra在内的完整监控堆栈,我们强烈推荐使用kube-prometheus。
使用Helm安装
感谢@rlex,还有一个用于部署Pyrra的Helm chart。
在Docker / 文件系统中运行
这种操作模式的示例可以在examples/docker-compose中找到。
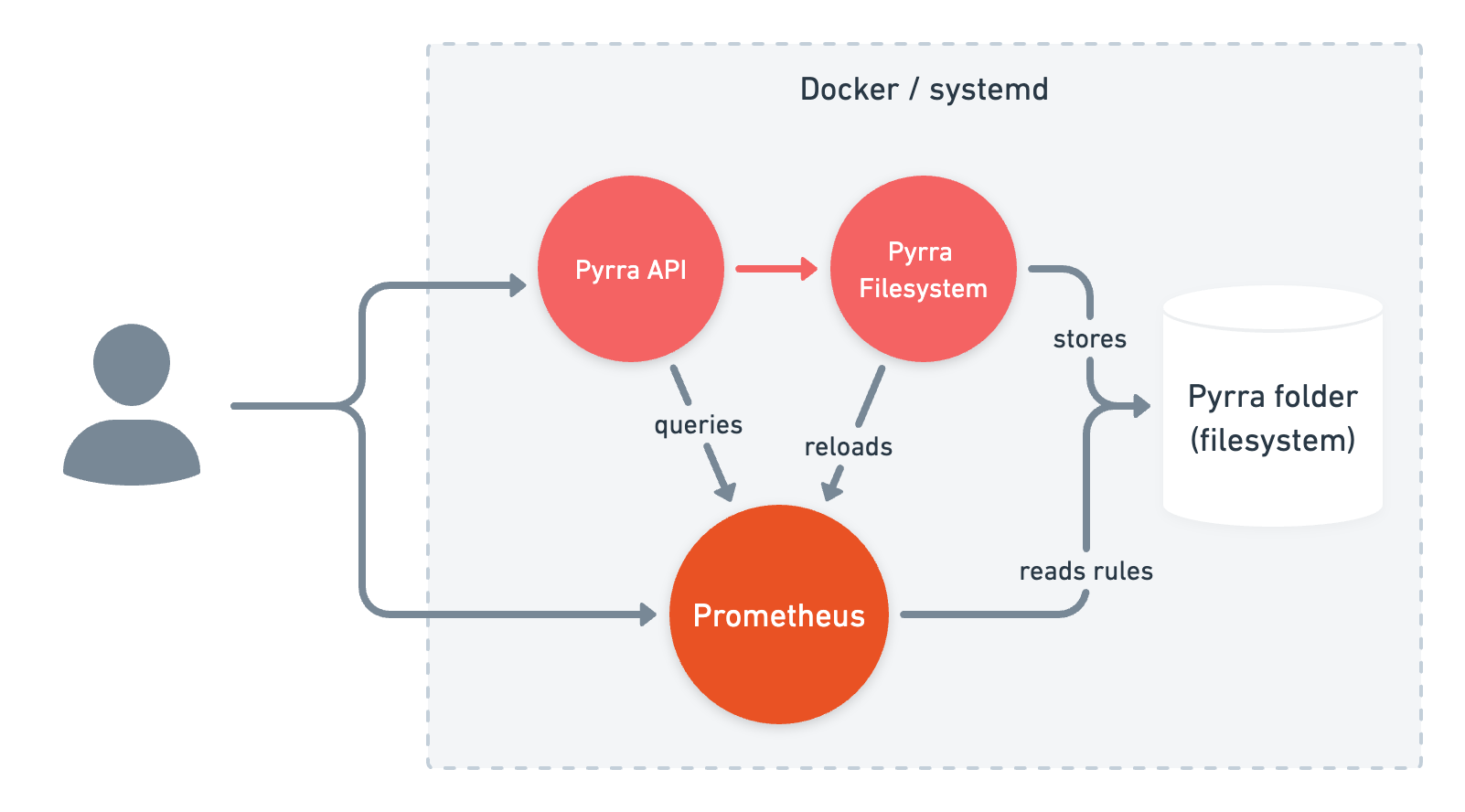
您可以通过提供的Docker镜像轻松单独启动Pyrra:
docker pull ghcr.io/pyrra-dev/pyrra:v0.7.0
在Kubernetes之外运行Pyrra时,可以通过从文件系统读取的YAML文件提供SLO对象。为此,需要以api参数启动一个容器或二进制文件,并以filesystem参数启动调解器。
在这里,Pyrra将生成的记录规则保存到磁盘,Prometheus实例可以从中获取这些规则。虽然单独运行Pyrra是可行的,但不会配置任何SLO,也不会有来自Prometheus的任何数据可供使用。它被设计为与Prometheus一起工作。
技术栈
客户端: 使用React、Bootstrap和uPlot的TypeScript。
服务器: Go语言,使用以下库:chi、ristretto、xxhash、client-go。
使用connect-go(Go语言)和connect-web(TypeScript)生成protobuf API。
路线图
最好查看项目看板,如果找不到您要找的内容,随时可以提出问题!
贡献
我们随时欢迎贡献!
请参阅CONTRIBUTING.md了解如何开始。
请遵守本项目的行为准则。
维护者
| 姓名 | 领域 | GitHub | 公司 | |
|---|---|---|---|---|
| Nadine Vehling | 用户体验/界面 | @nadinevehling | @nadinevehling | Grafana Labs |
| Matthias Loibl | 工程 | @metalmatze | @metalmatze | Polar Signals |
我们主要在业余时间维护Pyrra。
致谢
@aditya-konarde、 @brancz、 @cbrgm、 @codesome、 @ekeih、 @guusvw、 @jzelinskie、 @kakkoyun、 @lilic、 @markusressel、 @morremeyer、 @mxinden、 @numbleroot、 @paulfantom、 @RiRa12621、 @tboerger 以及Maria Franke。
在我们私下开发Pyrra期间,这些了不起的人给予了我们大量反馈,有些人甚至额外花了一个小时进行深入测试!非常感谢你们所有人!
此外,@metalmatze想要感谢Polar Signals允许我们在他20%的工作时间内开发这个项目。
常见问题
为什么在这个特定用例中不使用Grafana?
目前我们确实可以使用Grafana。在即将发布的版本中,我们计划添加更多交互功能,以便在提出新的SLO时为您提供更好的上下文。这是我们无法用Grafana实现的功能。
我还需要Grafana吗?
是的,Grafana是一个很棒的Prometheus指标数据可视化工具。您可以创建自己的自定义仪表板,并在调试时更深入地研究每个组件。
它也适用于Thanos吗?
是的,实际上我大部分时间都在我的小型Thanos集群上开发这个项目。 查询甚至会动态添加降采样的标头并禁用部分响应。
我应该部署多少个实例?
这取决于您的基础设施拓扑,但我们认为警报仍应在每个单独的Prometheus内进行,因此为每个Prometheus(对)运行一个实例是最合理的。Pyrra本身只需要每个Prometheus(对)一个实例。
为什么不支持更复杂的SLO?
目前,我们尝试为最常见的SLO实现一个易于设置的工作流程。 仍然可以手动编写这些更复杂的SLO并将其与生成的SLO一起部署到Prometheus。 您可以基于此工具生成的一个SLO的输出来构建更复杂的SLO。
为什么目标值是字符串而不是浮点数?
Kubebuilder不支持CRD中的浮点数... 因此,我们需要将其作为字符串传递,并在内部将其从字符串转换为float64。
相关项目
以下是一些相关项目:











