
MotionGPT: 微调后的大语言模型是通用运动生成器

本文《MotionGPT: Finetuned LLMs are General-Purpose Motion Generators》的官方PyTorch实现。
请访问我们的项目页面了解更多详情。
如果您发现MotionGPT对您的工作有帮助,请引用:
@article{zhang2023motiongpt,
title={MotionGPT: Finetuned LLMs are General-Purpose Motion Generators},
author={Zhang, Yaqi and Huang, Di and Liu, Bin and Tang, Shixiang and Lu, Yan and Chen, Lu and Bai, Lei and Chu, Qi and Yu, Nenghai and Ouyang, Wanli},
journal={arXiv preprint arXiv:2306.10900},
year={2023}
}
目录
安装
1. 环境
conda env create -f environment.yml
conda activate motiongpt
2. 依赖项
用于文本到运动评估
bash prepare/download_evaluators.sh
bash prepare/download_glove.sh
用于SMPL网格渲染
bash prepare/download_smpl.sh
要使用LLaMa模型权重,请遵循pyllama下载原始LLaMA模型,然后遵循Lit-LLaMA将权重转换为Lit-LLaMA格式。完成此过程后,请将lit-llama/目录移动到checkpoints/目录下。
下载后,文件夹结构应如下所示:
MotionGPT
├── checkpoints
│ ├── kit
│ │ ├── Comp_v6_KLD005
│ │ ├── Decomp_SP001_SM001_H512
│ │ ├── length_est_bigru
│ │ ├── text_mot_match
│ │ └── VQVAEV3_CB1024_CMT_H1024_NRES3
│ ├── lit-llama
│ │ ├── 7B
│ │ │ └── lit-llama.pth
│ │ ├── 13B
│ │ └── tokenizer.model
│ └── t2m
│ ├── Comp_v6_KLD005
│ ├── M2T_EL4_DL4_NH8_PS
│ ├── T2M_Seq2Seq_NML1_Ear_SME0_N
│ ├── text_mot_match
│ └── VQVAEV3_CB1024_CMT_H1024_NRES3
├── body_models
│ └── smpl
│ ├── J_regressor_extra.npy
│ ├── kintree_table.pkl
│ ├── smplfaces.npy
│ └── SMPL_NEUTRAL.pkl
└── glove
├── our_vab_data.npy
├── our_vab_idx.pkl
└── our_vab_words.pkl
3. 预训练模型
用于预训练的VQ-VAE模型
bash prepare/download_vqvae.sh
用于微调的LLaMA模型
bash prepare/download_lora.sh
下载后,文件夹结构应如下所示:
MotionGPT/checkpoints
├── pretrained_vqvae
│ ├── kit.pth
│ └── t2m.pth
└── pretrained_lora
└── pretrained.pth
4. 数据集
请遵循HumanML3D下载HumanML3D和KIT-ML数据集,并将它们放在dataset目录下,如下所示:
MotionGPT/dataset
├── HumanML3D
└── KIT-ML
准备用于微调LLaMA的数据集,请按照以下说明进行(以HumanML3D为例)
# 通过预训练VQ-VAE将动作编码为令牌,并将令牌序列结果保存在`./dataset/HumanML3D/VQVAE/`下
# 对于预训练的VQ-VAE,您可以使用提供的模型或按照训练说明自行训练模型
python scripts/prepare_data.py --dataname t2m
# 在训练集和验证集上生成格式为{instruction, input, output}的数据集
# 结果保存在`./data/train.json`和`./data/val.json`
python scripts/generate_dataset.py --dataname t2m
# 生成相应的指令微调数据集
# 结果保存在`./data/train.pt`和`./data/val.pt`
python scripts/prepare_motion.py --dataname t2m
演示
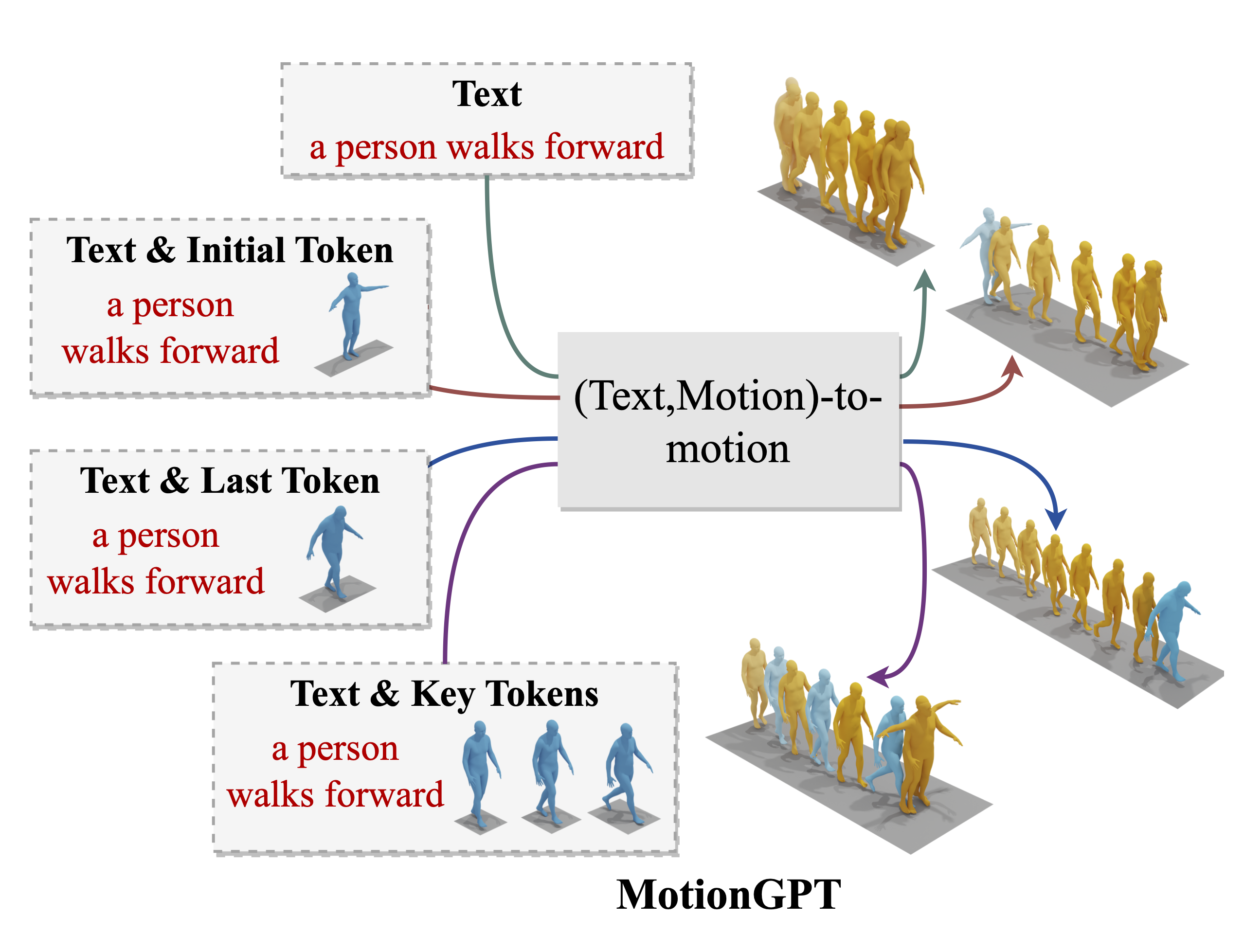
给定任务描述(--prompt)和条件(--input)以生成相应的运动。将运动保存为npy格式(demo.npy)和骨架可视化结果(demo.gif),并保存在{output_dir}下。
如果你想渲染SMPL网格,请设置--render。
# 文本到运动
python generate_motion.py --prompt "生成与以下人体运动描述相匹配的运动令牌序列。" --input "一个人向前走。" --lora_path ./checkpoints/pretrained_lora/pretrained.pth --out_dir {output_dir} --render
# (文本,初始姿态)到运动
python generate_motion.py --prompt "生成与以下人体运动描述相匹配的运动令牌序列,给定初始令牌。" --input "一个人向前走。<Motion Token>315</Motion Token>" --lora_path ./checkpoints/pretrained_lora/pretrained.pth --out_dir {output_dir} --render
# (文本,最终姿态)到运动
python generate_motion.py --prompt "生成与以下人体运动描述相匹配的运动令牌序列,给定最终令牌。" --input "一个人向前走。<Motion Token>406</Motion Token>" --lora_path ./checkpoints/pretrained_lora/pretrained.pth --out_dir {output_dir} --render
# (文本,关键姿态)到运动
python generate_motion.py --prompt "生成与以下人体运动描述相匹配的运动令牌序列,给定几个关键令牌。" --input "一个人向前走。<Motion Token>315,91,406</Motion Token>" --lora_path ./checkpoints/pretrained_lora/pretrained.pth --out_dir {output_dir} --render
训练
对于VQ-VAE训练
python train_vqvae.py --out_dir {output_dir} --dataname t2m
对于使用LoRA微调LLaMA
python finetune_motion.py --out_dir {output_dir} --dataname t2m
评估
对于VQ-VAE
python eval_vqvae.py --out_dir {output_dir} --resume_pth {vqvae_model_path} --dataname t2m
对于LLaMA
python eval.py --vqvae_pth {vqvae_model_path} --lora_path {fintuned_model_path} --out_dir {output_dir} --dataname t2m
可视化
生成的姿态都保存在形状为[seq_len, joint_num, 3]的npy格式中。
输出结果以gif格式保存在相同目录中,并具有相应的文件名。
对于骨架格式的可视化
# 可视化保存在{saved_pose_dir}中的所有姿态
python visualization/plot_3d_global.py --dir {saved_pose_dir}
# 可视化保存在{saved_pose_dir}中的选定姿态
python visualization/plot_3d_global.py --dir {saved_pose_dir} --motion-list {fname1} {fname2} ...
对于SMPL网格渲染
# 可视化保存在{saved_pose_dir}中的所有姿态
python visualization/render.py --dir {saved_pose_dir}
# 可视化保存在{saved_pose_dir}中的选定姿态
python visualization/render.py --dir {saved_pose_dir} --motion-list {fname1} {fname2} ...











