
 Github
Github 文档
文档 论文
论文








EnvPool 是一个基于C++的批处理环境池,使用pybind11和线程池。它具有高性能(在Atari游戏中约1M原始FPS,在DGX-A100上使用Mujoco模拟器约3M原始FPS)和兼容的API(同时支持gym和dm_env,支持同步和异步,支持单玩家和多玩家环境)。目前支持:
- Atari游戏
- Mujoco (gym)
- 经典控制强化学习环境:CartPole、MountainCar、Pendulum、Acrobot
- 玩具文本强化学习环境:Catch、FrozenLake、Taxi、NChain、CliffWalking、Blackjack
- ViZDoom单人游戏
- DeepMind控制套件
- Box2D
- Procgen
- Minigrid
以下是EnvPool的几个亮点:
- 兼容OpenAI
gymAPI、DeepMinddm_envAPI和gymnasiumAPI; - 管理一组环境,默认使用批处理API与环境交互;
- 支持同步执行和异步执行;
- 支持单人和多人环境;
- 简单的C++开发者API用于添加新环境:自定义C++环境集成;
- 仅使用单个环境就可以免费获得约2倍的加速;
- 在256个CPU核心上实现每秒100万Atari帧 / 300万Mujoco步骤的模拟,比基于Python子进程的向量环境的吞吐量高约20倍;
- 在12个CPU核心的低资源设置上,比基于Python子进程的向量环境的吞吐量高约3倍;
- 与现有的基于GPU的解决方案(Brax / Isaac-gym)相比,EnvPool是一个用于加速各种强化学习环境并行化的通用解决方案;
- 支持带有JAX jit函数的XLA:XLA接口;
- 兼容一些现有的强化学习库,例如Stable-Baselines3、Tianshou、ACME、CleanRL或rl_games。
- Stable-Baselines3
Pendulum-v1示例; - Tianshou
CartPole示例、Pendulum-v1示例、Atari示例、Mujoco示例和集成指南; - ACME
HalfCheetah示例; - CleanRL
Pong-v5示例(5分钟内解决Pong(跟踪实验)); - rl_games Atari示例(2分钟Pong和15分钟Breakout)和Mujoco示例(5分钟Ant和HalfCheetah)。
- Stable-Baselines3
查看我们的arXiv论文了解更多详情!
安装
PyPI
EnvPool目前托管在PyPI上。它需要Python >= 3.7。
你可以使用以下命令简单地安装EnvPool:
$ pip install envpool
安装后,打开Python控制台并输入
import envpool
print(envpool.__version__)
如果没有出现错误,你已成功安装EnvPool。
从源代码安装
请参考指南。
文档
教程和API文档托管在envpool.readthedocs.io上。
示例脚本位于examples/文件夹下;基准测试脚本位于benchmark/文件夹下。
基准测试结果
我们在不同的硬件设置上对ALE Atari环境PongNoFrameskip-v4(使用OpenAI Baselines中的环境包装器)和Mujoco环境Ant-v3进行基准测试,包括一个96个CPU核心和2个NUMA节点的TPUv3-8虚拟机(VM),以及一个256个CPU核心和8个NUMA节点的NVIDIA DGX-A100。基准包括1)朴素Python for循环;2)最流行的通过Python子进程进行RL环境并行化执行,例如gym.vector_env;3)据我们所知,EnvPool之前最快的RL环境执行器Sample Factory。
我们报告了EnvPool在同步模式、异步模式和NUMA + 异步模式下的性能,并与不同数量工作者(即CPU核心数量)的基准进行了比较。从结果中我们可以看到,EnvPool在所有设置下都实现了显著的改进。在高端设置上,EnvPool在256个CPU核心上实现了每秒100万帧的Atari和300万帧的Mujoco,分别是gym.vector_env基准的14.9倍和19.6倍。在具有12个CPU核心的典型PC设置上,EnvPool的吞吐量是gym.vector_env的3.1倍和2.9倍。
| Atari 最高 FPS | 笔记本电脑 (12) | 工作站 (32) | TPU-VM (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For循环 | 4,893 | 7,914 | 3,993 | 4,640 |
| 子进程 | 15,863 | 47,699 | 46,910 | 71,943 |
| Sample-Factory | 28,216 | 138,847 | 222,327 | 707,494 |
| EnvPool (同步) | 37,396 | 133,824 | 170,380 | 427,851 |
| EnvPool (异步) | 49,439 | 200,428 | 359,559 | 891,286 |
| EnvPool (numa+异步) | / | / | 373,169 | 1,069,922 |
| Mujoco 最高 FPS | 笔记本电脑 (12) | 工作站 (32) | TPU-VM (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For循环 | 12,861 | 20,298 | 10,474 | 11,569 |
| 子进程 | 36,586 | 105,432 | 87,403 | 163,656 |
| Sample-Factory | 62,510 | 309,264 | 461,515 | 1,573,262 |
| EnvPool (同步) | 66,622 | 380,950 | 296,681 | 949,787 |
| EnvPool (异步) | 105,126 | 582,446 | 887,540 | 2,363,864 |
| EnvPool (numa+异步) | / | / | 896,830 | 3,134,287 |
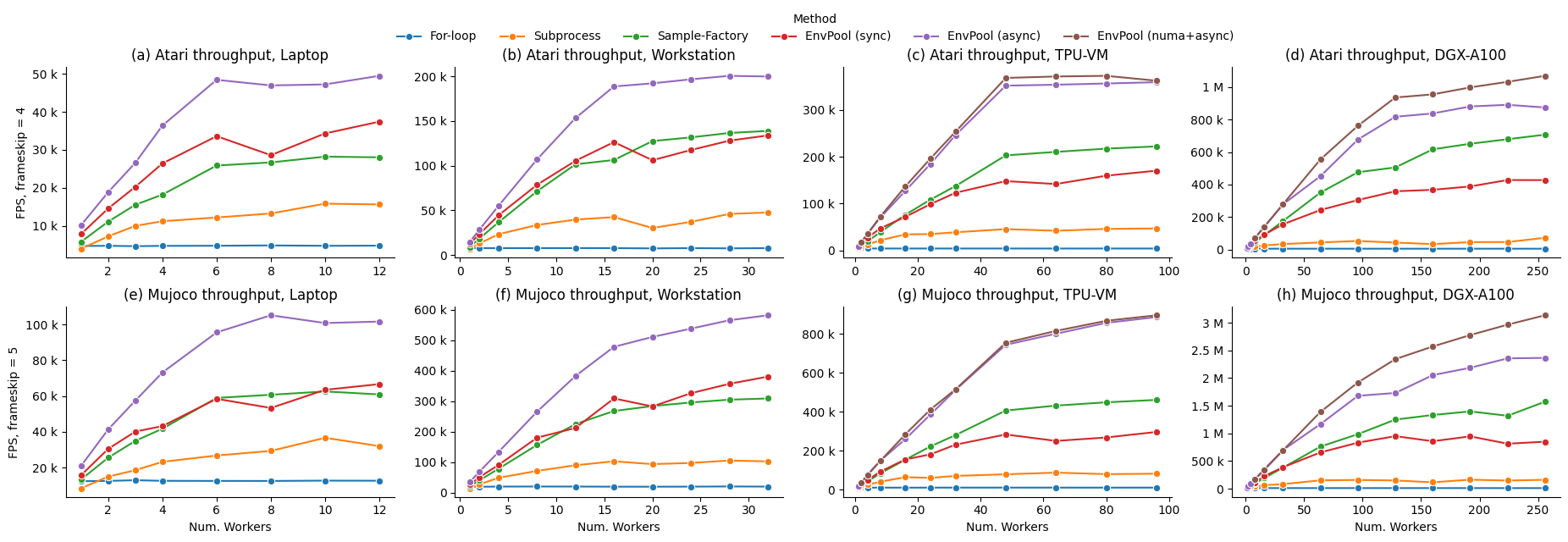
请参考基准测试页面了解更多详情。
API 使用
以下内容展示了EnvPool的同步和异步API使用。你也可以在examples/env_step.py运行完整脚本
同步API
import envpool
import numpy as np
# 创建gym环境
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)
# 或使用envpool.make_gym(...)
obs = env.reset() # 应为(100, 4, 84, 84)
act = np.zeros(100, dtype=int)
obs, rew, term, trunc, info = env.step(act)
在同步模式下,envpool与openai-gym/dm-env非常相似。它具有相同含义的reset和step函数。但是,envpool有一个例外:批量交互是默认的。因此,在创建envpool时,有一个num_envs参数,表示你想要并行运行的环境数量。
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)
传递给step函数的action的第一个维度应等于num_envs。
act = np.zeros(100, dtype=int)
当任何done为真时,你不需要手动重置一个环境;相反,envpool中的所有环境默认启用了自动重置。
异步API
import envpool
import numpy as np
# 创建异步环境
num_envs = 64
batch_size = 16
env = envpool.make("Pong-v5", env_type="gym", num_envs=num_envs, batch_size=batch_size)
action_num = env.action_space.n
env.async_reset() # 向所有环境发送初始重置信号
while True:
obs, rew, term, trunc, info = env.recv()
env_id = info["env_id"]
action = np.random.randint(action_num, size=batch_size)
env.send(action, env_id)
在异步模式下,step函数被分为两部分:send和recv函数。send接受两个参数,一批动作和对应的应该发送这些动作的env_id。与step不同,send不等待环境执行并返回下一个状态,它在动作被送入环境后立即返回。(这就是为什么它被称为异步模式)。
env.send(action, env_id)
要获取"下一个状态",我们需要调用recv函数。然而,recv不保证你会得到你刚刚调用send的环境的"下一个状态"。相反,无论哪个环境先完成执行都会被recv接收。
state = env.recv()
除了num_envs,还有一个参数batch_size。num_envs定义了envpool管理的总环境数量,而batch_size指定每次与envpool交互时涉及的环境数量。例如,envpool中有64个环境在执行,send和recv每次与16个环境的批次交互。
envpool.make("Pong-v5", env_type="gym", num_envs=64, batch_size=16)
envpool.make还有其他可配置的参数;请查看EnvPool Python接口介绍。
贡献
EnvPool仍在开发中。我们将添加更多环境,并始终欢迎贡献以使EnvPool变得更好。如果你想贡献,请查看我们的贡献指南。
许可证
EnvPool使用Apache2许可证。
其他第三方源代码和数据受其相应的许可证约束。
我们不在此仓库中包含它们的源代码和数据。
引用EnvPool
如果你发现EnvPool有用,请在你的出版物中引用它。
@inproceedings{weng2022envpool,
author = {Weng, Jiayi and Lin, Min and Huang, Shengyi and Liu, Bo and Makoviichuk, Denys and Makoviychuk, Viktor and Liu, Zichen and Song, Yufan and Luo, Ting and Jiang, Yukun and Xu, Zhongwen and Yan, Shuicheng},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {22409--22421},
publisher = {Curran Associates, Inc.},
title = {Env{P}ool: A Highly Parallel Reinforcement Learning Environment Execution Engine},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/8caaf08e49ddbad6694fae067442ee21-Paper-Datasets_and_Benchmarks.pdf},
volume = {35},
year = {2022}
}
免责声明
这不是Sea Limited或Garena Online Private Limited的官方产品。











