
 Github
Github 论文
论文DoReMi🎶:基于极小极大优化的领域重新加权


DoReMi的PyTorch实现,这是一种用于优化语言建模数据集数据混合的算法。现代大型语言模型在多个领域(网络、书籍、arXiv等)上进行训练,但每个领域应该训练多少并不清楚,特别是考虑到这些模型将用于各种下游任务(没有特定的目标分布可供优化)。DoReMi使用分布鲁棒优化(DRO)调整数据混合,以对目标分布保持鲁棒性。DoReMi使用DRO训练一个小型代理模型,根据代理模型相对于预训练参考模型的超额损失动态上调或下调领域权重。参考模型提供了可达到的最佳损失估计,以避免对高熵/困难领域过于悲观。调整后的数据混合可以更高效地用于训练更大的模型。在论文中,280M代理模型可以改善8B参数模型(大30倍)的训练,使其能够以2.6倍的速度达到基线8B性能。下图概述了DoReMi。更多详情请查看论文。
作为一个黑盒,这个代码库输出给定文本数据集的优化领域权重。其他一些有用的组件包括:快速、可恢复的数据加载器,支持领域级加权采样,简单的下游评估工具,以及HuggingFace Trainer + FlashAttention2集成。

入门
要开始使用,请克隆仓库并安装:
git clone git@github.com:/sangmichaelxie/doremi.git
pip install -e doremi
cd doremi && bash scripts/setup_flash.sh
scripts/setup_flash.sh中的编译可能需要相当长的时间(数小时)。所有代码应在最外层的doremi目录中运行。
开始之前,请在本仓库的外层目录中的constants.sh文件中写入缓存目录、数据目录等的路径。你也可以在这里放置任何conda或virtualenv激活命令。以下是constants.sh文件内容的示例(提供了一个名为sample_constants.sh的文件):
#!/bin/bash
CACHE=/path/to/cache
DOREMI_DIR=/path/to/this/repo
PILE_DIR=/path/to/pile
PREPROCESSED_PILE_DIR=/path/to/preprocessed # 将由scripts/run_preprocess_pile.sh创建
MODEL_OUTPUT_DIR=/path/to/model_output_dir
WANDB_API_KEY=key # Weights and Biases日志记录的密钥
PARTITION=partition # 用于slurm
mkdir -p ${CACHE}
mkdir -p ${MODEL_OUTPUT_DIR}
source ${DOREMI_DIR}/venv/bin/activate # 如果你在venv中安装了doremi
以下是如何运行The Pile数据预处理的示例脚本,该脚本将Pile数据分离成不同领域并进行标记化:
bash scripts/run_preprocess_pile.sh
这是一个运行120M基线、代理和主模型(DoReMi管道中的所有3个步骤)的示例脚本,在一个具有8个A100 GPU的节点上测试。这是论文中Pile实验的小型版本。该脚本将自动运行困惑度和少样本评估:
bash scripts/run_pile.sh
这些脚本运行200k步,遵循论文。DoReMi运行在configs目录中输出域权重,文件名为<RUN_NAME>.json。
在自己的数据集上运行DoReMi
要在自己的数据集上运行DoReMi,请提供以下格式的预处理(标记化)数据:
top_level/
domain_name_1/
files...
domain_name_2/
files...
...
其中每个内部目录(例如,domain_name_1)可以通过HuggingFace的load_from_disk方法加载。如果你的数据采用不同格式,可以在doremi/dataloader.py中添加自定义数据加载函数。
你还需要编写一个配置文件并将其保存到configs/,并编写类似于scripts/runs/run_pile_baseline120M.sh和scripts/runs/run_pile_doremi120M.sh的运行脚本,这些脚本引用配置文件。配置文件指定了从域名到混合权重的映射。名称不必按顺序(DoReMi总是首先对域名进行排序以确定固定顺序),权重也不必归一化。
提示和细节
-
参考领域权重的选择:一般来说,参考领域权重是表达对领域重要性先验的一种方式。一个合理的默认设置是根据每个领域的大小来设置参考模型的领域权重,这确保了小领域不会被过度表示(并被过拟合)。如果某些领域特别重要,你当然可以增加其相应的参考领域权重。均匀领域权重可以用作参考领域权重,以避免对领域权重施加任何先验,但可能需要迭代DoReMi(见下文)。
-
迭代DoReMi:在某些情况下,你可能需要运行多轮DoReMi。要运行迭代DoReMi,我们使用上一轮优化后的领域权重来训练新的参考模型。这在你从次优参考领域权重(如均匀权重)开始时特别有帮助,因为使用这些权重训练的参考模型也会是次优的。
-
领域权重的更新率(
--reweight_eps):论文中使用的默认设置是1,尽管这可能需要针对不同的数据集进行调整。通常,我们预期训练过程中的领域权重会有些噪声,而平均领域权重则大多平滑。 -
分词器的选择:我们发现较新的分词器(如NeoX)在较小规模上往往能提供更好的模型性能,因此我们建议使用这些而不是像GPT2这样的旧分词器。
-
在领域子集上运行:默认的数据集加载代码只会加载配置文件中列出的领域。通过从配置文件中删除领域,可以实现在领域子集上运行。
-
梯度累积:梯度累积应该可以工作,初步测试中,其行为与无累积场景类似。然而,目前在这个实现中使用累积与无累积并不完全等价。如果我们累积
k步的梯度,将有k-1个梯度是根据上一迭代的旧领域权重计算的(这个问题在k=1时不存在)。 -
多节点训练:我们目前不支持多节点训练,主要关注单节点、多GPU设置。
请注意,此仓库与在谷歌开发的论文之间存在一些差异,即:
- PyTorch vs JAX
- 模型架构的细微差异
- 使用的分词器(论文中使用256k词汇量,而标准开源分词器约为50k词汇量)。这可能会显著影响按令牌数计算的数据混合。 为获得最佳结果,你应该在自己的特定训练设置中运行DoReMi。
样本运行结果
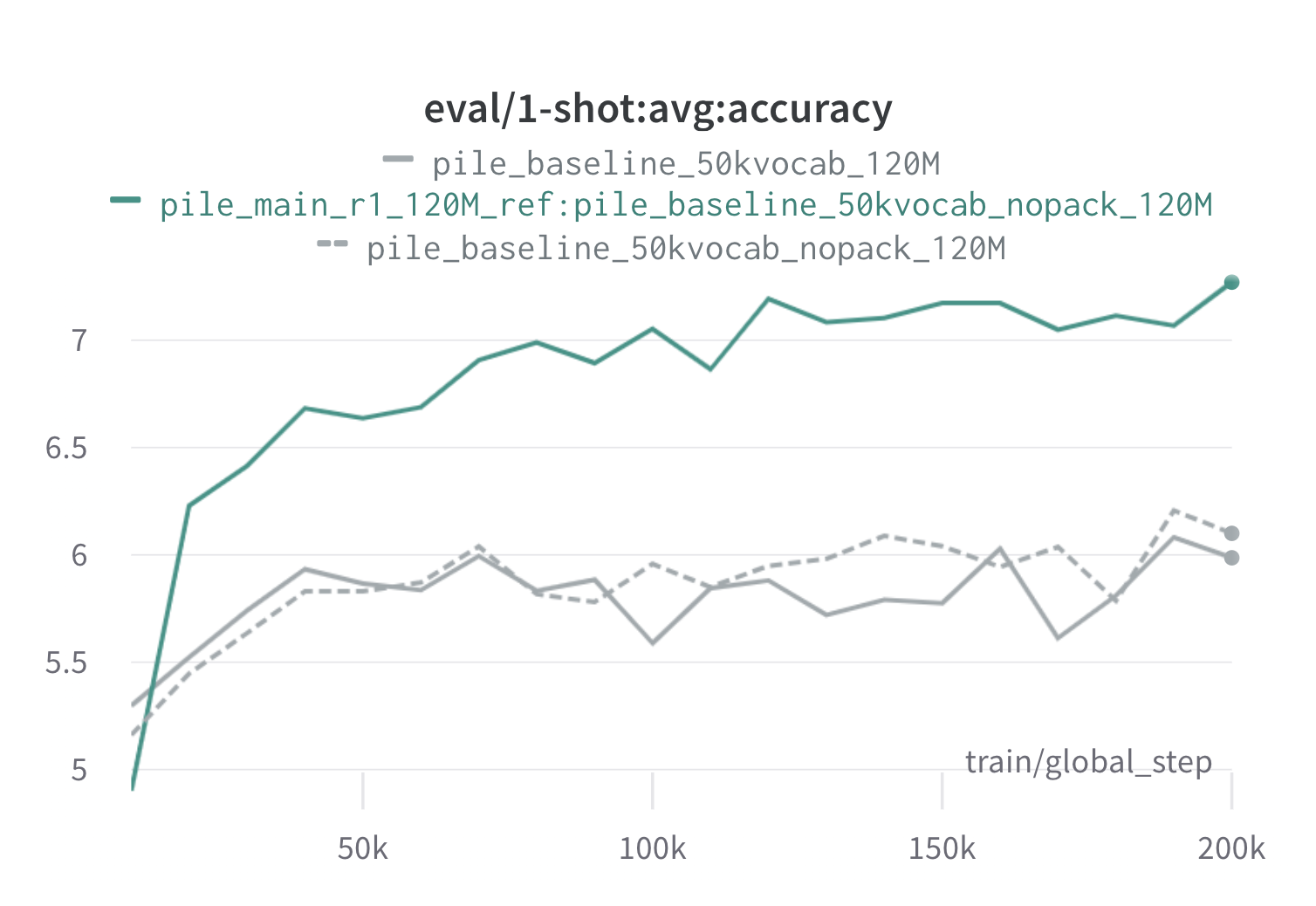
以下是在The Pile上使用120M代理和参考模型进行一轮DoReMi的结果(使用scripts/run_pile.sh)。我们使用优化后的权重(configs/pile_doremi_r1_120M_ref:pile_baseline_50kvocab_nopack_120M.json)训练一个120M模型,并将其与基线(灰色)进行比较。两个基线代表在Pile中计算基线领域权重的两种略有不同的方法(nopack在将每个文档填充到上下文窗口长度后计算每个领域的示例数,而pack首先在一个领域内连接文档),这两种方法产生的模型性能相似。使用DoReMi领域权重训练的模型在训练早期,在所有任务中都很快超过了基线的一次性性能,仅在70k步内(快3倍)。DoReMi模型在20k步内就超过了平均基线一次性性能,在22个领域中有15个领域的困惑度得到改善或相当,并改善了跨领域的均匀平均和最差情况困惑度。
引用
如果这对你有用,请引用论文:
@article{xie2023doremi,
author = {Sang Michael Xie and Hieu Pham and Xuanyi Dong and Nan Du and Hanxiao Liu and Yifeng Lu and Percy Liang and Quoc V. Le and Tengyu Ma and Adams Wei Yu},
journal = {arXiv preprint arXiv:2305.10429},
title = {DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining},
year = {2023},
}











