
 访问官网
访问官网 Github
Github




Similarity
similarity,相似度计算工具包,可用于文本相似度计算、情感倾向分析等,Java编写。
similarity是由一系列算法组成的Java版相似度计算工具包,目标是传播自然语言处理中相似度计算方法。similarity具备工具实用、性能高效、架构清晰、语料时新、可自定义的特点。
Feature
similarity提供下列功能:
-
词语相似度计算
- 词林编码法相似度[推荐]
- 汉语语义法相似度
- 知网词语相似度
- 字面编辑距离法
-
短语相似度计算
- 简单短语相似度[推荐]
-
句子相似度计算
- 词性和词序结合法[推荐]
- 编辑距离算法
- Gregor编辑距离法
- 优化编辑距离法
-
段落相似度计算
- 余弦相似度[推荐]
- 编辑距离
- 欧几里得距离
- Jaccard相似性系数
- Jaro距离
- Jaro–Winkler距离
- 曼哈顿距离
- SimHash + 汉明距离
- Sørensen–Dice系数
-
知网义原
- 词语义原树
-
情感分析
- 正面倾向程度
- 负面倾向程度
- 情感倾向性
-
近似词
- word2vec
在提供丰富功能的同时,similarity内部模块坚持低耦合、模型坚持惰性加载、词典坚持明文发布,使用方便,帮助用户训练自己的语料。
Usage
引入Jar包
Maven
<repositories>
<repository>
<id>jitpack.io</id>
<url>https://jitpack.io</url>
</repository>
</repositories>
<dependency>
<groupId>com.github.shibing624</groupId>
<artifactId>similarity</artifactId>
<version>1.1.6</version>
</dependency>
Gradle
gradle的引入:
使用示例
import org.xm.Similarity;
import org.xm.tendency.word.HownetWordTendency;
public class demo {
public static void main(String[] args) {
double result = Similarity.cilinSimilarity("电动车", "自行车");
System.out.println(result);
String word = "混蛋";
HownetWordTendency hownetWordTendency = new HownetWordTendency();
result = hownetWordTendency.getTendency(word);
System.out.println(word + " 词语情感趋势值:" + result);
}
}
功能演示
1. 词语相似度计算
文本长度:词语粒度
推荐使用词林相似度:org.xm.Similarity.cilinSimilarity,是基于同义词词林的相似度计算方法
example: src/test/java/org.xm/WordSimilarityDemo.java
package org.xm;
public class WordSimilarityDemo {
public static void main(String[] args) {
String word1 = "教师";
String word2 = "教授";
double cilinSimilarityResult = Similarity.cilinSimilarity(word1, word2);
double pinyinSimilarityResult = Similarity.pinyinSimilarity(word1, word2);
double conceptSimilarityResult = Similarity.conceptSimilarity(word1, word2);
double charBasedSimilarityResult = Similarity.charBasedSimilarity(word1, word2);
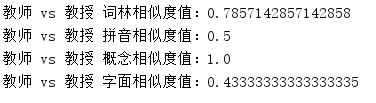
System.out.println(word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult);
System.out.println(word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult);
System.out.println(word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult);
System.out.println(word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult);
}
}
- result:
2. 短语相似度计算
文本长度:短语粒度
推荐使用短语相似度:org.xm.Similarity.phraseSimilarity,本质是通过两个短语具有的相同字符,和相同字符的位置计算其相似度的方法
example: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main(String[] args) {
String phrase1 = "继续努力";
String phrase2 = "持续发展";
double result = Similarity.phraseSimilarity(phrase1, phrase2);
System.out.println(phrase1 + " vs " + phrase2 + " 短语相似度值:" + result);
}
- result:

3. 句子相似度计算
文本长度:句子粒度
推荐使用词形词序句子相似度:org.xm.similarity.morphoSimilarity,一种既考虑两个句子相同文本字面,也考虑相同文本出现的前后顺序的相似度方法
example: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main(String[] args) {
String sentence1 = "中国人爱吃鱼";
String sentence2 = "湖北佬最喜吃鱼";
double morphoSimilarityResult = Similarity.morphoSimilarity(sentence1, sentence2);
double editDistanceResult = Similarity.editDistanceSimilarity(sentence1, sentence2);
double standEditDistanceResult = Similarity.standardEditDistanceSimilarity(sentence1,sentence2);
double gregeorEditDistanceResult = Similarity.gregorEditDistanceSimilarity(sentence1,sentence2);
System.out.println(sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult);
System.out.println(sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult);
System.out.println(sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult);
System.out.println(sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult);
}
- result:

4. 段落文本相似度计算
文本长度:段落粒度(一段话,25字符 < length(text) < 500字符)
推荐使用词形词序句子相似度:org.xm.similarity.text.CosineSimilarity,一种考虑两个段落中相同的文本,经过切词,词频和词性权重加权,并用余弦计算相似度的方法
example: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java <SOURCE_TEXT>
@Test
public void getSimilarityScore() throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。";
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。";
TextSimilarity cosSimilarity = new CosineSimilarity();
double score1 = cosSimilarity.getSimilarity(text1, text2);
System.out.println("cos相似度分值:" + score1);
TextSimilarity editSimilarity = new EditDistanceSimilarity();
double score2 = editSimilarity.getSimilarity(text1, text2);
System.out.println("edit相似度分值:" + score2);
}
- result:
cos相似度分值:0.399143
edit相似度分值:0.0875
5. 基于义原树的情感分析
example: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@Test
public void getTendency() throws Exception {
HownetWordTendency hownet = new HownetWordTendency();
String word = "美好";
double sim = hownet.getTendency(word);
System.out.println(word + ":" + sim);
System.out.println("混蛋:" + hownet.getTendency("混蛋"));
}
- result:
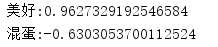
本例是基于义原树的词语粒度情感极性分析,关于文本情感分析有pytextclassifier,利用深度神经网络模型、SVM分类算法实现的效果更好。
6. 近义词推荐
example: src/test/java/org/xm/word2vec/Word2vecTest.java
@Test
public void testHomoionym() throws Exception {
List<String> result = Word2vec.getHomoionym(RAW_CORPUS_SPLIT_MODEL, "武功", 10);
System.out.println("武功 近似词:" + result);
}
@Test
public void testHomoionymName() throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL;
List<String> result = Word2vec.getHomoionym(model, "乔帮主", 10);
System.out.println("乔帮主 近似词:" + result);
List<String> result2 = Word2vec.getHomoionym(model, "阿朱", 10);
System.out.println("阿朱 近似词:" + result2);
List<String> result3 = Word2vec.getHomoionym(model, "少林寺", 10);
System.out.println("少林寺 近似词:" + result3);
}
- 训练过程:

- result:

Word2vec词向量训练用的java版word2vec训练工具Word2VEC_java,训练语料是小说天龙八部,通过词向量实现得到近义词。 用户可以训练自定义语料,也可以用中文维基百科训练通用词向量。
Todo
文本相似性度量
- 关键词匹配(TF-IDF、BM25)
- 浅层语义匹配(WordEmbed隐语义模型,用word2vec或glove词向量直接累加构造的句向量)
- 深度语义匹配模型(DSSM、CLSM、DeepMatch、MatchingFeatures、ARC-II、DeepMind见MatchZoo),BERT类语义匹配模型SentenceBERT、CoSENT见text2vec
Contact
- Issue(建议):
- 邮件我:xuming: xuming624@qq.com
- 微信我: 加我微信号:xuming624, 备注:姓名-公司-NLP 进NLP交流群。

License
授权协议为 The Apache License 2.0,可免费用做商业用途。请在产品说明中附加similarity的链接和授权协议。
Contribute
项目代码还很粗糙,如果大家对代码有所改进,欢迎提交回本项目,在提交之前,注意以下两点:
- 在
test添加相应的单元测试 - 运行所有单元测试,确保所有单测都是通过的
之后即可提交PR。
Reference
- [DSSM] Po-Sen Huang, et al., 2013, Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
- [CLSM] Yelong Shen, et al, 2014, A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
- [DeepMatch] Zhengdong Lu & Hang Li, 2013, A Deep Architecture for Matching Short Texts
- [MatchingFeatures] Zongcheng Ji, et al., 2014, An Information Retrieval Approach to Short Text Conversation
- [ARC-II] Baotian Hu, et al., 2015, Convolutional Neural Network Architectures for Matching Natural Language Sentences
- [DeepMind] Aliaksei Severyn, et al., 2015, Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks </SOURCE_TEXT>











