
Text2Video
这是ICASSP 2022论文“Text2Video: 基于文本驱动的说话人视频合成与语音词典” 的代码。 项目页面
)
介绍
随着深度学习技术的进步,从音频或文本自动生成视频已经成为一个新兴的、有前途的研究课题。在这篇论文中,我们提出了一种从文本生成视频的新方法。该方法构建了一个音素-动作字典,并训练了一个生成对抗网络(GAN)来从插值后的音素动作生成视频。与音频驱动的视频生成算法相比,我们的方法有很多优点:1)只需要音频驱动方法训练数据的一小部分;2)更灵活,不受说话者变化的影响;3)显著减少预处理、训练和推理时间。我们进行了大量实验,将所提出的方法与基准数据集和我们自己的数据集上的最新说话人脸生成方法进行比较。结果表明了我们方法的有效性和优越性。
数据 / 预处理
设置
- 克隆仓库
git clone git@github.com:sibozhang/Text2Video.git
-
下载并安装修改后的 vid2vid 仓库 vid2vid
-
下载训练模型
请在 vid2vid 文件夹中建立“checkpoints”文件夹,并将训练好的模型放入其中。
VidTIMIT fadg0(英语,女性)
Dropbox: https://www.dropbox.com/sh/lk6et49v2uyfzjx/AADAFAp02_b3FQchaYxOZ0EMa?dl=0
百度云链接: https://pan.baidu.com/s/1SSkMKOK9LhClW2JvDCSiLg?pwd=bevj 提取码: bevj
Xuesong(中文,男性)
Dropbox: https://www.dropbox.com/sh/qz3zoma5ac9mw5p/AAARiR8xKvATN4CBSyjWt_uOa?dl=0
百度云链接: 链接: https://pan.baidu.com/s/1DvuBbThYo4n5RIZsc-92rg?pwd=am7d 提取码: am7d
- 按以下顺序准备数据和文件夹
Text2Video
├── *phoneme_data
├── model
├── ...
vid2vid
├── ...
venv
├── vid2vid
- 设置环境
sudo apt-get install sox libsox-fmt-mp3
pip install zhon
pip install moviepy
pip install ffmpeg
pip install dominate
pip install pydub
对于中文,我们使用 vosk 获取每个单词的时间戳。 请从 https://alphacephei.com/vosk/install 安装 vosk 并解压至当前文件夹中的“model”下。 或者安装:
pip install vosk
pip install cn2an
pip install pypinyin
测试
- 激活 virtual 环境 vid2vid
source ../venv/vid2vid/bin/activate
- 用真实音频生成英文视频
sh text2video_audio.sh $1 $2
用TTS音频生成英文视频
sh text2video_tts.sh $1 $2 $3
用TTS音频生成中文视频
sh text2video_tts.sh $1 $2 $3
$1: "输入文本" $2: 人物 $3: 填写 f 为女性或 m 为男性(性别)
例子 1. 测试 VidTIMIT 数据和真实音频。
sh text2video_audio.sh "She had your dark suit in greasy wash water all year." fadg0 f
例子 2. 使用 TTS 音频测试 VidTIMIT 数据。
sh text2video_tts.sh "She had your dark suit in greasy wash water all year." fadg0 f
例子 3. 测试中文女性 TTS 音频。
sh text2video_tts_chinese.sh "正在为您查询合肥的天气情况。今天是2020年2月24日,合肥市今天多云,最低温度9摄氏度,最高温度15摄氏度,微风。" henan f
用您自己的数据进行训练
英语音素 / 中文拼音模型:
- 建模
1.1 视频录制:
阅读涵盖所有音素或拼音的提示,请参考 ./prompts 文件夹下的 prompts.docx 中的音素或 all_pinyin.txt 中的拼音。每个发音之间停顿0.5秒。用相机录制至少 1280x720 的视频。
1.2 音素-嘴形/ 拼音-嘴形字典:
使用 montreal-forced-aligner(谷歌 STT)获取音素/ 使用 vosk 获取拼音并生成每个单词的时间戳,并将其放入字典文件中,数据结构如下,每行保存一个 [音素/ 拼音,帧数] 对:
音素, 帧数: AA 52 AA0 52 AA1 52 AA2 52 AE 90 AE0 90 AE1 90 AE2 90 AH 127 AH0 127 AH1 127 AH2 127 AO 146 AO0 146 AO1 146 AO2 146 AW 227 AW0 227 AW1 227 AW2 227 ...
拼音, 帧数: ba 61 bo 86 bi 540 bu 110 bai 130 bao 154 ban 178 bang 202 ou 225 pa 272 po 298 ...
1.3 Openpose:
使用 openpose 处理视频的每一帧,获取人体骨架结果,并将其保存到单独的文件夹中。openpose 的代码可以在以下网址下载: https://github.com/CMU-Perceptual-Computing-Lab/openpose 编译成功后,运行:
./build/examples/openpose/openpose.bin --image_dir ./images --face --hand --write_json ./keypoints
1.4 使用生成的人体骨架模型和对应的视频训练 vid2vid 模型,该模型用于生成逼真的人体骨架模型人像视频。vid2vid 的代码可以在这里下载:https://github.com/NVIDIA/vid2vid
训练:
python train.py --name xx --dataroot datasets/xx --dataset_mode pose --input_nc 3
--openpose_only --num_D 2 --resize_or_crop randomScaleHeight_and_scaledCrop
--loadSize 544 --fineSize 512 --gpu_ids 0,1,2,3,4,5,6,7 --batchSize 8
--max_frames_per_gpu 2 --niter 500 --niter_decay 5 --no_first_img --n_frames_total 12
--max_t_step 4 --niter_step 100 --save_epoch_freq 100 --add_face_disc
--random_drop_prob 0
- 视频生成
2.1 从文本生成音频文件:
使用百度 TTS 云服务生成所需的语音。百度语音云服务地址: http://wiki.baidu.com/pages/viewpage.action?pageId=342334101。请参考具体调用 tts_request.py
2.2 分析音频,找出每个文本的时间戳:
使用中文版本的 VOSK 语音识别来处理生成的 TTS 语音,生成如下 <帧数,拼音> 文件。VOSK 代码可以在这里下载:https://github.com/alphacep/vosk-api。具体调用请参考 pinyin_timestamping.py
25 xu 29 yao 38 zuo 46 Geng 53 jia 60 chong 65 fen 70 de 75 zun 80 bei 100 yin 105 ci 111 ne 116 wei 118 le
2.3 对音频中的每个文本,使用其拼音找到对应的二维骨架模型,并将其拼接成一个动态的二维骨架模型。对于视频,通过插值获得中间帧。详见 interp_landmarks_motion.py。
2.4 使用 vid2vid 模型从二维骨架视频生成最终的人像视频。示例如下:
CUDA_VISIBLE_DEVICES=1 python test.py --name xx --dataroot datasets/xx
--dataset_mode pose --input_nc 3 --resize_or_crop scaleHeight --loadSize 512
--openpose_only --how_many 1200 --no_first_img --random_drop_prob 0
引用
请在您的出版物中引用我们的论文。
Sibo Zhang, Jiahong Yuan, Miao Liao, Liangjun Zhang. PDF 结果视频
@INPROCEEDINGS{9747380,
author={Zhang, Sibo and Yuan, Jiahong and Liao, Miao and Zhang, Liangjun},
booktitle={ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Text2video: Text-Driven Talking-Head Video Synthesis with Personalized Phoneme - Pose Dictionary},
year={2022},
volume={},
number={},
pages={2659-2663},
doi={10.1109/ICASSP43922.2022.9747380}
}
@article{zhang2021text2video,
title={Text2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary},
author={Zhang, Sibo and Yuan, Jiahong and Liao, Miao and Zhang, Liangjun},
journal={arXiv preprint arXiv:2104.14631},
year={2021}
}
附录
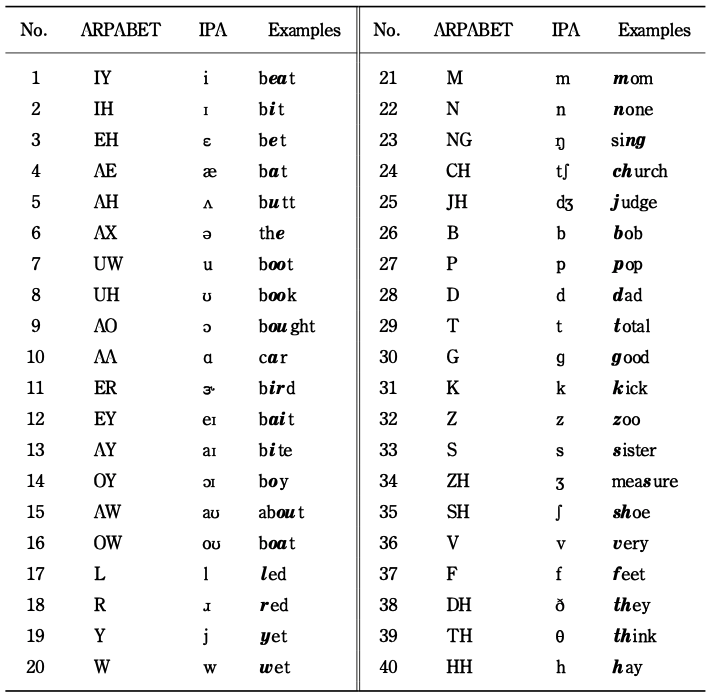
ARPABET
致谢
此代码基于 vid2vid 框架。









