
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文SimplerEnv: 用于真实机器人设置的模拟操作策略评估环境

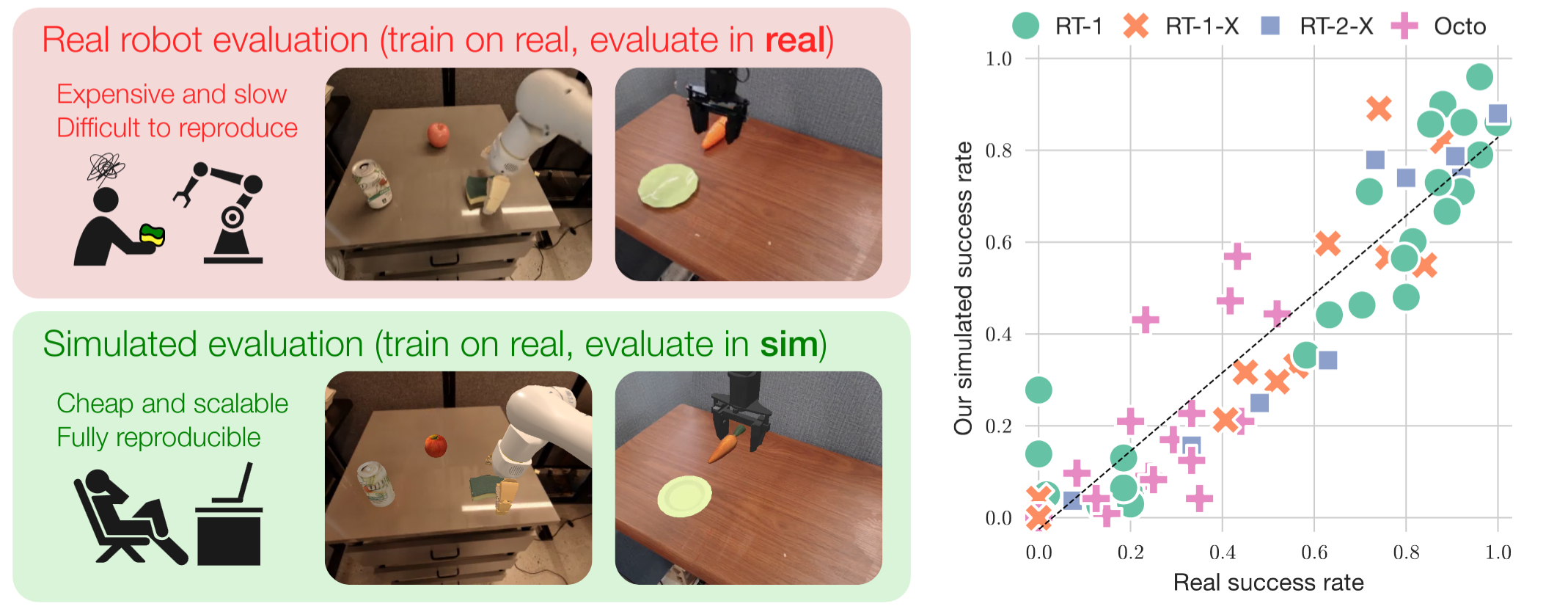
在构建通用机器人操作策略方面已取得重大进展,但其可扩展和可复现的评估仍然具有挑战性,因为真实世界的评估在操作上成本高昂且效率低下。我们建议采用物理模拟器作为真实世界评估的高效、可扩展和信息丰富的补充。这些模拟评估提供了有价值的定量指标,用于检查点选择、洞察潜在的真实世界策略行为或失败模式,以及标准化的设置以增强可复现性。
本仓库基于SAPIEN模拟器和ManiSkill2基准(我们还将在ManiSkill3完成后将评估环境集成到其中)。
本仓库包含两种真实到模拟的评估设置:
视觉匹配评估:通过将真实世界图像叠加到模拟背景上并调整模拟中前景物体和机器人纹理,匹配真实和模拟的视觉外观以进行策略评估。变体聚合评估:创建不同的模拟环境变体(例如,不同的背景、光照、干扰物、桌面纹理等)并平均其结果。
我们希望我们的工作能够指导并启发未来的真实到模拟评估工作。
入门
按照安装部分安装我们环境的最小要求。然后您可以使用交互式Python运行以下最小推理脚本。该脚本为我们的视觉匹配评估设置创建预打包的环境。
import simpler_env
from simpler_env.utils.env.observation_utils import get_image_from_maniskill2_obs_dict
env = simpler_env.make('google_robot_pick_coke_can')
obs, reset_info = env.reset()
instruction = env.get_language_instruction()
print("重置信息", reset_info)
print("指令", instruction)
done, truncated = False, False
while not (done or truncated):
# action[:3]: delta xyz; action[3:6]: 轴角表示法的delta旋转;
# action[6:7]: 夹持器(开/关的含义取决于机器人URDF)
image = get_image_from_maniskill2_obs_dict(env, obs)
action = env.action_space.sample() # 用您的策略推理替换此处
obs, reward, done, truncated, info = env.step(action) # 对于长期任务,您可以调用env.advance_to_next_subtask()来进入下一个子任务;如果env._elapsed_steps大于阈值,环境也可能自动前进
new_instruction = env.get_language_instruction()
if new_instruction != instruction:
# 对于长期任务,当机器人进入下一个子任务时,我们会获得新指令
instruction = new_instruction
print("新指令", instruction)
episode_stats = info.get('episode_stats', {})
print("回合统计", episode_stats)
此外,您可以通过ManiSkill2_real2sim/mani_skill2_real2sim/examples/demo_manual_control_custom_envs.py以交互方式体验我们的环境。有关更多详细信息和命令,请参阅该脚本。
安装
先决条件:
- CUDA版本 >=11.8(如果您想对此仓库进行完整安装并执行RT-1或Octo推理,则需要此版本)
- NVIDIA GPU(最好是RTX;对于非RTX GPU,如1080Ti和A100,涉及光线追踪的环境会很慢)。目前不支持TPU,因为SAPIEN需要GPU运行。
创建一个anaconda环境:
conda create -n simpler_env python=3.10 (任何3.10以上的版本都可以)
conda activate simpler_env
克隆此仓库:
git clone https://github.com/simpler-env/SimplerEnv --recurse-submodules
安装numpy<2.0(否则pinocchio中的IK可能会出错):
pip install numpy==1.24.4
安装ManiSkill2真实到仿真环境及其依赖项:
cd {this_repo}/ManiSkill2_real2sim
pip install -e .
安装此软件包:
cd {this_repo}
pip install -e .
如果您想对我们提供的智能体(例如RT-1、Octo)进行评估,或添加新的机器人和环境,请另外遵循此处的完整安装说明。
示例
- 在预打包环境中使用视觉匹配评估设置的简单RT-1和Octo评估脚本:请参见
simpler_env/simple_inference_visual_matching_prepackaged_envs.py。 - RT-1和Octo推理的Colab笔记本:请参见此链接。
- 环境交互式可视化和手动控制:请参见
ManiSkill2_real2sim/mani_skill2_real2sim/examples/demo_manual_control_custom_envs.py - 策略推理脚本,用于重现我们的Google Robot和WidowX真实到仿真评估结果,包括对物体/机器人姿态的扫描和高级日志记录。这些包含视觉匹配和变体聚合评估设置,以及RT-1、RT-1-X和Octo策略。请参见
scripts/。 - 运行
scripts/*.sh的真实到仿真评估视频:请参见此链接。
当前环境
要获取所有可用环境的列表,请运行:
import simpler_env
print(simpler_env.ENVIRONMENTS)
| 任务名称 | ManiSkill2 环境名称 | 图像(视觉匹配) |
|---|---|---|
| google_robot_pick_coke_can | GraspSingleOpenedCokeCanInScene-v0 |  |
| google_robot_pick_object | GraspSingleRandomObjectInScene-v0 |  |
| google_robot_move_near | MoveNearGoogleBakedTexInScene-v1 |  |
| google_robot_open_drawer | OpenDrawerCustomInScene-v0 |  |
| google_robot_close_drawer | CloseDrawerCustomInScene-v0 |  |
| google_robot_place_in_closed_drawer | PlaceIntoClosedDrawerCustomInScene-v0 |  |
| widowx_spoon_on_towel | PutSpoonOnTableClothInScene-v0 |  |
| widowx_carrot_on_plate | PutCarrotOnPlateInScene-v0 |  |
| widowx_stack_cube | StackGreenCubeOnYellowCubeBakedTexInScene-v0 |  |
| widowx_put_eggplant_in_basket | PutEggplantInBasketScene-v0 |  |
我们还支持创建子任务变体,如google_robot_pick_{horizontal/vertical/standing}_coke_can、google_robot_open_{top/middle/bottom}_drawer和google_robot_close_{top/middle/bottom}_drawer。对于google_robot_place_in_closed_drawer任务,我们在论文评估中使用google_robot_place_apple_in_closed_top_drawer子任务。
默认情况下,Google Robot环境使用3Hz的控制频率,Bridge环境使用5Hz的控制频率。模拟频率约为500Hz。
将您的策略评估方法与SIMPLER进行比较
我们提供了一种简单的方法来将您的离线机器人策略评估方法与SIMPLER进行比较。在我们的论文中,我们使用两个指标来衡量模拟评估流程的质量:平均最大排名违反(MMRV)和皮尔逊相关系数。这两个指标都能反映离线评估如何体现策略在真实世界机器人执行过程中的性能和行为。
为了便于比较,我们提供了所有任务上所有策略的真实和SIMPLER评估性能。我们还提供了计算论文中提到的上述指标的相应函数。
要计算您的离线策略评估方法your_sim_eval(task, policy)的相应指标,您可以使用以下代码片段:
from simpler_env.utils.metrics import mean_maximum_rank_violation, pearson_correlation, REAL_PERF
sim_eval_perf = [
对任务"google_robot_move_near"使用策略p进行你的模拟评估
for p in ["rt-1-x", "octo", ...]
]
real_eval_perf = [
REAL_PERF["google_robot_move_near"][p] for p in ["rt-1-x", "octo", ...]
]
mmrv = 计算真实评估性能和模拟评估性能的平均最大排名违规
pearson = 计算真实评估性能和模拟评估性能的皮尔逊相关系数
要重现我们论文中SIMPLER的关键数据,你可以运行`tools/calc_metrics.py`脚本:
python3 tools/calc_metrics.py
代码结构
ManiSkill2_real2sim/: ManiSkill2真实到模拟环境的代码库,包含用于真实到模拟评估的环境、机器人和物体。
data/
custom/: 自定义物体资产(如可乐罐、橱柜)及其信息
hab2_bench_assets/: 自定义场景资产
real_inpainting/: 用于视觉匹配评估的真实世界修复图像
debug/: 调试资产
mani_skill2_real2sim/
agents/: 机器人代理、配置和控制器实现
assets/: 机器人资产,如URDF和网格
envs/: 环境
examples/demo_manual_control_custom_envs.py: 环境可视化和手动控制的交互式脚本
utils/
...
simpler_env/
evaluation/: 具有高级环境构建和日志记录功能的真实到模拟评估器
argparse.py: 支持自定义策略和环境构建的参数解析器
maniskill2_evaluator.py: 支持环境参数扫描和高级日志记录的评估器
policies/: 策略实现
rt1/: RT-1策略实现
octo/: Octo策略实现
utils/:
env/: 环境构建和观察工具
debug/: 策略和机器人的调试工具
...
main_inference.py: 主推理脚本,从evaluation.argparse接收参数并调用evaluation.maniskill2_evaluator
simple_inference_visual_matching_prepackaged_envs.py: 对预打包环境进行独立简单推理的脚本,不依赖evaluation/*
tools/
robot_object_visualization/: 创建新环境时用于可视化机器人和物体的工具
sysid/: 添加新机器人时用于系统识别的工具
calc_metrics.py: 用于总结评估结果和计算指标的工具,如平均最大排名违规(MMRV)和皮尔逊相关系数
coacd_process_mesh.py: 添加新资产时通过CoACD生成凸碰撞网格的工具
merge_videos.py: 合并视频的工具
...
scripts/: 在我们的变体聚合/视觉匹配评估设置下进行策略推理的示例bash脚本,
具有自定义环境构建和高级日志记录功能;也可用于重现我们的评估结果
...
添加新策略
如果你想使用现有环境评估新策略,可以保持`./ManiSkill2_real2sim`不变。
1. 在`simpler_env/policies/{your_new_policy}`中实现新的策略推理脚本,参照RT-1(`simpler_env/policies/rt1`)和Octo(`simpler_env/policies/octo`)策略的示例。
2. 现在你可以使用`simpler_env/simple_inference_visual_matching_prepackaged_envs.py`在模拟中进行策略评估。
- 如果策略行为与真实世界有很大偏差,你可以编写类似于`simpler_env/utils/debug/{policy_name}_inference_real_video.py`的脚本来调试策略行为。调试脚本通过将真实评估视频帧输入策略来执行策略推理。如果策略行为仍然与真实情况有显著偏差,这可能表明策略动作在模拟环境中处理不正确。请仔细检查动作顺序和动作空间。
3. 如果你想进行自定义评估,
- 修改`simpler_env/main_inference.py`中的几行以支持你的新策略。
- 在`scripts/`中添加带有自定义配置的策略推理脚本。
- 可选地,修改`tools/calc_metrics.py`中的脚本,为你的新策略计算真实到模拟的评估指标。
添加新的真实到模拟评估环境和机器人
我们在[这个README](https://github.com/simpler-env/SimplerEnv/blob/main/ADDING_NEW_ENVS_ROBOTS.md)中提供了添加新的真实到模拟评估环境和机器人的分步指南。
完整安装(RT-1和Octo推理,环境构建)
如果你想对我们提供的代理(如RT-1、Octo)进行评估,或添加新的机器人和环境,请按照以下完整安装说明进行操作。
sudo apt install ffmpeg
pip install tensorflow==2.15.0
pip install -r requirements_full_install.txt
pip install tensorflow[and-cuda]==2.15.1 # tensorflow gpu支持
安装用于系统识别的模拟退火工具:
pip install git+https://github.com/nathanrooy/simulated-annealing
RT-1推理设置
下载RT-1检查点:
# 首先,按照https://cloud.google.com/storage/docs/gsutil_install安装gsutil
# 创建一个检查点目录:
mkdir {this_repo}/checkpoints
# RT-1-X
cd {this_repo}
gsutil -m cp -r gs://gdm-robotics-open-x-embodiment/open_x_embodiment_and_rt_x_oss/rt_1_x_tf_trained_for_002272480_step.zip .
unzip rt_1_x_tf_trained_for_002272480_step.zip
mv rt_1_x_tf_trained_for_002272480_step checkpoints
rm rt_1_x_tf_trained_for_002272480_step.zip
# RT-1-收敛
cd {this_repo}
gsutil -m cp -r gs://gdm-robotics-open-x-embodiment/open_x_embodiment_and_rt_x_oss/rt_1_tf_trained_for_000400120 .
mv rt_1_tf_trained_for_000400120 checkpoints
# RT-1-15%
cd {this_repo}
gsutil -m cp -r gs://gdm-robotics-open-x-embodiment/open_x_embodiment_and_rt_x_oss/rt_1_tf_trained_for_000058240 .
mv rt_1_tf_trained_for_000058240 checkpoints
# RT-1-开始
cd {this_repo}
gsutil -m cp -r gs://gdm-robotics-open-x-embodiment/open_x_embodiment_and_rt_x_oss/rt_1_tf_trained_for_000001120 .
mv rt_1_tf_trained_for_000001120 checkpoints
Octo推理设置
安装Octo:
pip install --upgrade "jax[cuda11_pip]==0.4.20" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html # 如果您使用CUDA 12,则改为jax[cuda12_pip]
cd {this_repo}
git clone https://github.com/octo-models/octo/
cd octo
git checkout 653c54acde686fde619855f2eac0dd6edad7116b # 我们使用octo-1.0
pip install -e .
# 您不需要在octo仓库内运行"pip install -r requirements.txt";simpler_env仓库中已经处理了包依赖
# Octo检查点由huggingface管理,所以您不需要手动下载它们。
如果您使用CUDA 12,那么要使用GPU进行Octo推理,您需要CUDA版本 >= 12.2以满足Jax的要求;在这种情况下,您可以执行相应CUDA(例如12.3版本)的运行文件安装,然后在运行Octo推理脚本时设置环境变量:
PATH=/usr/local/cuda-12.3/bin:$PATH LD_LIBRARY_PATH=/usr/local/cuda-12.3/lib64:$LD_LIBRARY_PATH bash scripts/octo_xxx_script.sh
故障排除
- 如果您遇到以下问题:
RuntimeError: vk::Instance::enumeratePhysicalDevices: ErrorInitializationFailed
Some required Vulkan extension is not present. You may not use the renderer to render, however, CPU resources will be still available.
Segmentation fault (core dumped)
请按照此链接解决问题。(尽管文档指向SAPIEN 3和ManiSkill3,但故障排除部分仍适用于当前使用SAPIEN 2.2和ManiSkill2的环境)。
- 如果以下错误是由tensorflow的内部代码引起的,您可以忽略它。有时在运行推理或调试脚本时会出现此错误。
TypeError: 'NoneType' object is not subscriptable
引用
如果您发现我们的想法/环境有帮助,请引用我们的工作:
@article{li24simpler,
title={Evaluating Real-World Robot Manipulation Policies in Simulation},
author={Xuanlin Li and Kyle Hsu and Jiayuan Gu and Karl Pertsch and Oier Mees and Homer Rich Walke and Chuyuan Fu and Ishikaa Lunawat and Isabel Sieh and Sean Kirmani and Sergey Levine and Jiajun Wu and Chelsea Finn and Hao Su and Quan Vuong and Ted Xiao},
journal = {arXiv preprint arXiv:2405.05941},
year={2024}
}











