
 访问官网
访问官网 Github
Github 论文
论文

ColBERT (v2)
ColBERT 是一个快速且准确的检索模型,能够在几十毫秒内实现对大型文本集合的可扩展 BERT 搜索。

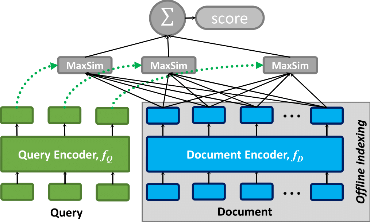
图 1: ColBERT 的后期交互,高效地评分查询和段落之间的细粒度相似度。
如图 1 所示,ColBERT 依赖于细粒度的上下文后期交互:它将每个段落编码为 token 级别嵌入的矩阵(上图中蓝色所示)。然后在搜索时,它将每个查询嵌入到另一个矩阵中(绿色所示),并使用可扩展的向量相似度(MaxSim)运算符有效地找到与查询在上下文中匹配的段落。
这些丰富的交互使 ColBERT 能够超越_单向量_表示模型的质量,同时高效地扩展到大型语料库。您可以在我们的论文中了解更多信息:
- ColBERT: 通过 BERT 上下文化后期交互实现高效和有效的段落搜索 (SIGIR'20)。
- 使用 ColBERT 进行 OpenQA 的相关性引导监督 (TACL'21)。
- Baleen: 通过压缩检索实现大规模的稳健多跳推理 (NeurIPS'21)。
- ColBERTv2: 通过轻量级后期交互实现有效和高效的检索 (NAACL'22)。
- PLAID: 高效的后期交互检索引擎 (CIKM'22)。
- 超越下游任务准确性的信息检索基准测试 (ACL'23 Findings)。
- UDAPDR: 通过 LLM 提示和重排序器蒸馏进行无监督域适应 (EMNLP'23)。
🚨 公告
- (2024/1/28) 如今在应用中使用 ColBERT 最简单的方法之一是半官方的、快速发展的 RAGatouille 库。
- (2023/1/29) 我们已合并了新的索引更新器功能并支持额外的 Hugging Face 模型!这些功能处于测试阶段,请在尝试时给我们反馈。
- (2023/1/24) 如果你在寻找DSPy框架以组合像 ColBERTv2 和 LLM 这样的检索器,它在:https://github.com/stanfordnlp/dspy
ColBERTv1
SIGIR'20 论文中的 ColBERTv1 代码位于 colbertv1 分支。有关其他分支的更多信息,请参见此处。
安装
(更新:现在您通常可以执行 pip install colbert-ai[torch,faiss-gpu] 来启动和运行,但如果遇到问题,conda 对 faiss 和 torch 总是更可靠。)
ColBERT 需要 Python 3.7+ 和 Pytorch 1.9+,并使用 Hugging Face Transformers 库。
我们强烈建议使用以下命令创建 conda 环境。(如果您没有 conda,请按照官方 conda 安装指南进行操作。)
我们还包含了一个专门用于仅 CPU 环境的新环境文件(conda_env_cpu.yml),但请注意,如果您在包含 GPU 的机器上测试 CPU 执行,可能需要将 CUDA_VISIBLE_DEVICES="" 指定为命令的一部分。请注意,训练和索引需要 GPU。
conda env create -f conda_env[_cpu].yml
conda activate colbert
如果您遇到任何问题,请开启一个新的 issue,我们会及时为您提供帮助!
概述
在数据集上使用 ColBERT 通常包括以下步骤。
步骤 0:预处理您的集合。 最简单的情况下,ColBERT 使用制表符分隔(TSV)文件:一个文件(例如,collection.tsv)将包含所有段落,另一个(例如,queries.tsv)将包含用于搜索集合的一组查询。
步骤 1:下载预训练的 ColBERTv2 检查点。 此检查点已在 MS MARCO 段落排序任务上训练。您也可以_选择性地_训练自己的 ColBERT 模型。
步骤 2:为您的集合建立索引。 一旦您有了训练好的 ColBERT 模型,您需要为您的集合建立索引以允许快速检索。此步骤将所有段落编码为矩阵,将它们存储在磁盘上,并构建用于高效搜索的数据结构。
步骤 3:使用您的查询搜索集合。 给定模型和索引,您可以对集合发出查询以检索每个查询的前 k 个段落。
下面,我们通过在 MS MARCO 段落排序任务上的示例运行来说明这些步骤。
API 使用笔记本
新增:我们在 Google Colab 上有一个实验性笔记本,您可以使用免费的 GPU。在免费的 Colab T4 GPU 上为 10,000 个样本建立索引需要六分钟。
这个 Jupyter 笔记本 docs/intro.ipynb 笔记本 展示了如何使用新的 Python API 来使用 ColBERT 的关键功能。
它包括如何下载在 MS MARCO 段落排序上训练的 ColBERTv2 模型检查点以及如何下载我们新的 LoTTE 基准测试。
数据
此存储库直接使用简单的制表符分隔文件格式来存储查询、段落和前 k 个排序列表。
- 查询:每行是
qid \t 查询文本。 - 集合:每行是
pid \t 段落文本。 - 前 k 个排序:每行是
qid \t pid \t rank。
这直接适用于 MS MARCO 段落排序 数据集的数据格式。您将需要训练三元组(triples.train.small.tar.gz),开发集查询的官方前 1000 个排序列表(top1000.dev),以及开发集相关段落(qrels.dev.small.tsv)。要为完整集合建立索引,您还需要段落列表(collection.tar.gz)。
索引
为了快速检索,索引预先计算段落的 ColBERT 表示。
示例用法:
from colbert.infra import Run, RunConfig, ColBERTConfig
from colbert import Indexer
if __name__=='__main__':
with Run().context(RunConfig(nranks=1, experiment="msmarco")):
config = ColBERTConfig(
nbits=2,
root="/path/to/experiments",
)
indexer = Indexer(checkpoint="/path/to/checkpoint", config=config)
indexer.index(name="msmarco.nbits=2", collection="/path/to/MSMARCO/collection.tsv")
检索
我们通常建议您使用 ColBERT 进行端到端检索,它直接从完整集合中找到其前 k 个段落:
from colbert.data import Queries
from colbert.infra import Run, RunConfig, ColBERTConfig
from colbert import Searcher
if __name__=='__main__':
with Run().context(RunConfig(nranks=1, experiment="msmarco")):
config = ColBERTConfig(
root="/path/to/experiments",
)
searcher = Searcher(index="msmarco.nbits=2", config=config)
queries = Queries("/path/to/MSMARCO/queries.dev.small.tsv")
ranking = searcher.search_all(queries, k=100)
ranking.save("msmarco.nbits=2.ranking.tsv")
你可以选择性地指定`ncells`、`centroid_score_threshold`和`ndocs`搜索超参数,以在速度和结果质量之间进行权衡。不同`k`值的默认设置列在colbert/searcher.py中。
我们可以使用以下命令评估MSMARCO排名:
python -m utility.evaluate.msmarco_passages --ranking "/path/to/msmarco.nbits=2.ranking.tsv" --qrels "/path/to/MSMARCO/qrels.dev.small.tsv"
基础训练(ColBERTv1风格)
我们提供了一个预训练模型检查点,但我们也在这里详细说明如何从头开始训练。
注意,这个例子演示了ColBERTv1风格的训练,但提供的检查点是用ColBERTv2训练的。
训练需要一个JSONL三元组文件,每行包含一个`[qid, pid+, pid-]`列表。查询ID和段落ID分别对应指定的`queries.tsv`和`collection.tsv`文件。
示例用法(在4个GPU上训练):
from colbert.infra import Run, RunConfig, ColBERTConfig
from colbert import Trainer
if __name__=='__main__':
with Run().context(RunConfig(nranks=4, experiment="msmarco")):
config = ColBERTConfig(
bsize=32,
root="/path/to/experiments",
)
trainer = Trainer(
triples="/path/to/MSMARCO/triples.train.small.tsv",
queries="/path/to/MSMARCO/queries.train.small.tsv",
collection="/path/to/MSMARCO/collection.tsv",
config=config,
)
checkpoint_path = trainer.train()
print(f"保存检查点到 {checkpoint_path}...")
高级训练(ColBERTv2风格)
from colbert.infra.run import Run
from colbert.infra.config import ColBERTConfig, RunConfig
from colbert import Trainer
def train():
# 使用4个GPU(例如四个A100,但你可以通过更改nway、accumsteps、bsize来使用更少的GPU)。
with Run().context(RunConfig(nranks=4)):
triples = '/path/to/examples.64.json' # `wget https://huggingface.co/colbert-ir/colbertv2.0_msmarco_64way/resolve/main/examples.json?download=true`(26GB)
queries = '/path/to/MSMARCO/queries.train.tsv'
collection = '/path/to/MSMARCO/collection.tsv'
config = ColBERTConfig(bsize=32, lr=1e-05, warmup=20_000, doc_maxlen=180, dim=128, attend_to_mask_tokens=False, nway=64, accumsteps=1, similarity='cosine', use_ib_negatives=True)
trainer = Trainer(triples=triples, queries=queries, collection=collection, config=config)
trainer.train(checkpoint='colbert-ir/colbertv1.9') # 或从头开始,如`bert-base-uncased`
if __name__ == '__main__':
train()
运行轻量级ColBERTv2服务器
我们提供了一个脚本来运行轻量级服务器,该服务器以JSON格式为给定的搜索查询提供k(最多100)个排序结果。这个脚本可以用来支持DSP程序。
要运行服务器,请更新.env文件中的环境变量`INDEX_ROOT`和`INDEX_NAME`以指向适当的ColBERT索引。然后运行以下命令:
python server.py
示例查询:
http://localhost:8893/api/search?query=Who won the 2022 FIFA world cup&k=25
分支
支持的分支
* `main`:稳定分支,包含ColBERTv2 + PLAID。
* `colbertv1`:ColBERTv1的遗留分支。
已弃用的分支
* `new_api`:基础ColBERTv2实现。
* `cpu_inference`:支持CPU搜索的ColBERTv2实现。
* `fast_search`:带有PLAID的ColBERTv2实现。
* `binarization`:使用基线二值化压缩策略的ColBERT(相对于ColBERTv2的残差压缩,我们发现后者更稳健)。
致谢
ColBERT标志由Chuyi Zhang设计。











