
 Github
Github 论文
论文RankGPT:作为重排序代理的大型语言模型


论文"ChatGPT在搜索方面表现如何?调查大型语言模型作为重排序代理"的代码
本项目旨在探索像ChatGPT和GPT-4这样的生成式大型语言模型在信息检索(IR)中的相关性排序应用。
新闻
- [2023.12.10] 我们的RankGPT论文荣获EMNLP2023杰出论文奖!🎉🎉🎉
- [2023.11.06] 引入指令蒸馏:简化复杂的排序指令以提高大型语言模型的效率。仅使用开源大型语言模型就达到了最先进的排序性能!
- [2023.10.08] 我们的论文已被接受在EMNLP 2023主会议上展示。查看更新版本:https://arxiv.org/pdf/2304.09542.pdf!
- [2023.08.05] 现在通过LiteLLM支持Azure、Claude、Cohere、Llama2!
- [2023.07.11] 发布新的测试集NovelEval,包含未被最新大型语言模型(如GPT-4)污染的新颖搜索问题和段落。详情见NovelEval。
- [2023.04.23] 在这里分享10万个ChatGPT在MS MARCO训练集上预测的排列。
- [2023.04.19] 我们的论文现已发布:https://arxiv.org/abs/2304.09542
快速示例
以下定义了一个查询和三个候选段落:
item = {
'query': '口罩对预防COVID-19传播有多大影响?',
'hits': [
{'content': '标题:COVID-19大流行中普及戴口罩刻不容缓:SEIR和基于代理的模型、实证验证、政策建议 内容:我们提出两个模型预测普及戴口罩对SARS-CoV-2病毒传播的影响——一个采用随机动态网络的SEIR(易感-暴露-感染-康复)分区模型方法,另一个采用个体ABM(基于代理建模)蒙特卡罗模拟——表明(1)当至少80%的人口戴口罩时,(几乎)普及戴口罩有显著影响,而当只有50%或更少人口戴口罩时,影响微乎其微,(2)当在地区疫情爆发的第50天前采取普及戴口罩措施时,影响显著,而晚期采取则影响微小。即使是过滤率较低的自制口罩也存在这些效果。为验证这些理论模型,我们将其预测与我们收集的新实证数据集进行比较'},
{'content': '标题:大众戴口罩可能减轻COVID-19疫情 内容:使用两种最先进的基于网络的软件,其中一种针对SARS-CoV-2病毒进行了校准,通过计算机模拟估计了大众戴口罩对COVID-19疫情的影响。所解决的问题如下:1. 大众戴口罩能否限制SARS-CoV-2在一个国家的传播?2. 存在哪些类型的口罩,对抗COVID-19需要多么精良的口罩才有效?3. 口罩是否必须在疫情早期使用?4. 简要讨论口罩及一些可能的未来研究问题。结果如下:(1)结果表明,任何类型的口罩,即使是简单的自制口罩,都可能有效。即使每个口罩的防护效果(这里称为"单个口罩防护")很低,戴口罩似乎也能降低新患者数量'},
{'content': '标题:戴还是不戴:模拟大众使用口罩遏制COVID-19大流行的潜力 内容:大众使用口罩遏制COVID-19大流行的传播存在争议,尽管越来越多地被推荐,但这种干预措施的潜力尚未得到充分理解。我们开发了一个分区模型,用于评估无症状公众广泛使用口罩的社区影响,其中一部分人可能是无症状感染者。使用与美国纽约州和华盛顿州COVID-19动态相关的数据进行模型模拟表明,即使是相对低效的口罩,如果得到广泛采用,也可能显著减少COVID-19的社区传播,并降低住院高峰和死亡人数。此外,口罩使用降低有效传播率的程度与口罩效果(作为阻止潜在传染接触的比例)和覆盖率(作为'}
]
}
我们可以使用ChatGPT通过指令排列生成来重新排序段落:
from rank_gpt import permutation_pipeline
new_item = permutation_pipeline(item, rank_start=0, rank_end=3, model_name='gpt-3.5-turbo', api_key='您的OPENAI密钥!')
print(new_item)
我们得到以下结果:
{
'query': '口罩对预防新冠病毒传播的影响有多大?',
'hits': [
{'content': '标题:新冠疫情中普及戴口罩的紧迫性:SEIR和基于代理的模型、实证验证、政策建议 内容:我们提出两个预测普及戴口罩对SARS-CoV-2病毒传播影响的新冠疫情模型——一个采用随机动态网络基于SEIR(易感-暴露-感染-康复)的分区模型,另一个采用个体ABM(基于代理建模)蒙特卡罗模拟——表明(1)当至少80%的人口戴口罩时,(接近)普及戴口罩有显著影响,而当只有50%或更少的人口戴口罩时,影响微乎其微,(2)在地区疫情爆发的第50天前采取普及戴口罩时影响显著,而晚期采取则影响微小。即使是过滤率较低的自制口罩,这些效果也成立。为验证这些理论模型,我们将其预测与我们收集的新实证数据集进行比较'},
{'content': '标题:戴还是不戴:为遏制新冠疫情普及公众戴口罩的潜力建模 内容:公众普及戴口罩以限制新冠疫情传播虽然存在争议,但越来越多地被推荐,这种干预措施的潜力尚不清楚。我们开发了一个分区模型,用于评估普通无症状公众戴口罩的社区范围影响,其中一部分可能是无症状感染者。使用与美国纽约州和华盛顿州新冠动态相关的数据进行模型模拟表明,即使是相对低效的口罩,如果得到广泛采用,也可能显著减少新冠病毒在社区的传播,并降低住院和死亡高峰。此外,口罩使用几乎与口罩效果(作为阻断潜在传染接触的比例)和覆盖率(作为'},
{'content': '标题:普及公众戴口罩可能会减轻新冠疫情 内容:使用两种独立的最先进网络软件,其中一种针对SARS-CoV-2病毒校准,通过计算机模拟估算了普及公众戴口罩对新冠疫情的影响。解决的问题包括:1. 普及公众戴口罩能否限制SARS-CoV-2在一个国家的传播?2. 存在哪些类型的口罩,口罩需要多复杂才能对抗新冠病毒有效?3. 口罩是否需要在疫情早期使用?4. 简要讨论口罩及一些关于口罩和SARS-CoV-2的可能未来研究问题。结果如下:(1) 结果表明任何类型的口罩,甚至简单的自制口罩,都可能有效。即使每个口罩的防护效果(这里称为"单口罩防护")很低,口罩使用似乎也能降低新患者数量'}
]
}
步骤示例
from rank_gpt import create_permutation_instruction, run_llm, receive_permutation
# (1) 创建排列生成指令
messages = create_permutation_instruction(item=item, rank_start=0, rank_end=3, model_name='gpt-3.5-turbo')
# (2) 获取ChatGPT预测的排列
permutation = run_llm(messages, api_key="你的OPENAI密钥!", model_name='gpt-3.5-turbo')
# (3) 使用排列重新排序段落
item = receive_permutation(item, permutation, rank_start=0, rank_end=3)
滑动窗口策略
我们引入了一种用于指令排列生成的滑动窗口策略,使大语言模型能够对超过其最大令牌限制的段落进行排序。
其思想是使用滑动窗口从后向前进行排序,每次只对窗口内的段落进行重新排序。
以下是使用窗口大小为2和步长为1重新排序3个段落的示例:
from rank_gpt import sliding_windows
api_key = "你的OPENAI密钥"
new_item = sliding_windows(item, rank_start=0, rank_end=3, window_size=2, step=1, model_name='gpt-3.5-turbo', api_key=api_key)
print(new_item)
基准测试评估
我们使用pyserini为每个查询检索100个段落,并使用指令排列生成对它们进行重新排序。
TREC-DL19评估示例:
from pyserini.search import LuceneSearcher, get_topics, get_qrels
from rank_gpt import run_retriever, sliding_windows
import tempfile
openai_key = None # 你的openai密钥
# 使用pyserini BM25检索段落。
searcher = LuceneSearcher.from_prebuilt_index('msmarco-v1-passage')
topics = get_topics('dl19-passage')
qrels = get_qrels('dl19-passage')
rank_results = run_retriever(topics, searcher, qrels, k=100)
# 运行滑动窗口排列生成
new_results = []
for item in tqdm(rank_results):
new_item = sliding_windows(item, rank_start=0, rank_end=100, window_size=20, step=10, model_name='gpt-3.5-turbo', api_key=openai_key)
new_results.append(new_item)
# 评估nDCG@10
from trec_eval import EvalFunction
temp_file = tempfile.NamedTemporaryFile(delete=False).name
EvalFunction.write_file(new_results, temp_file)
EvalFunction.main('dl19-passage', temp_file)
运行所有基准测试的评估
python run_evaluation.py
以下是我们在TREC、BEIR和Mr. TyDi上进行初步实验的结果(平均nDCG@10)。
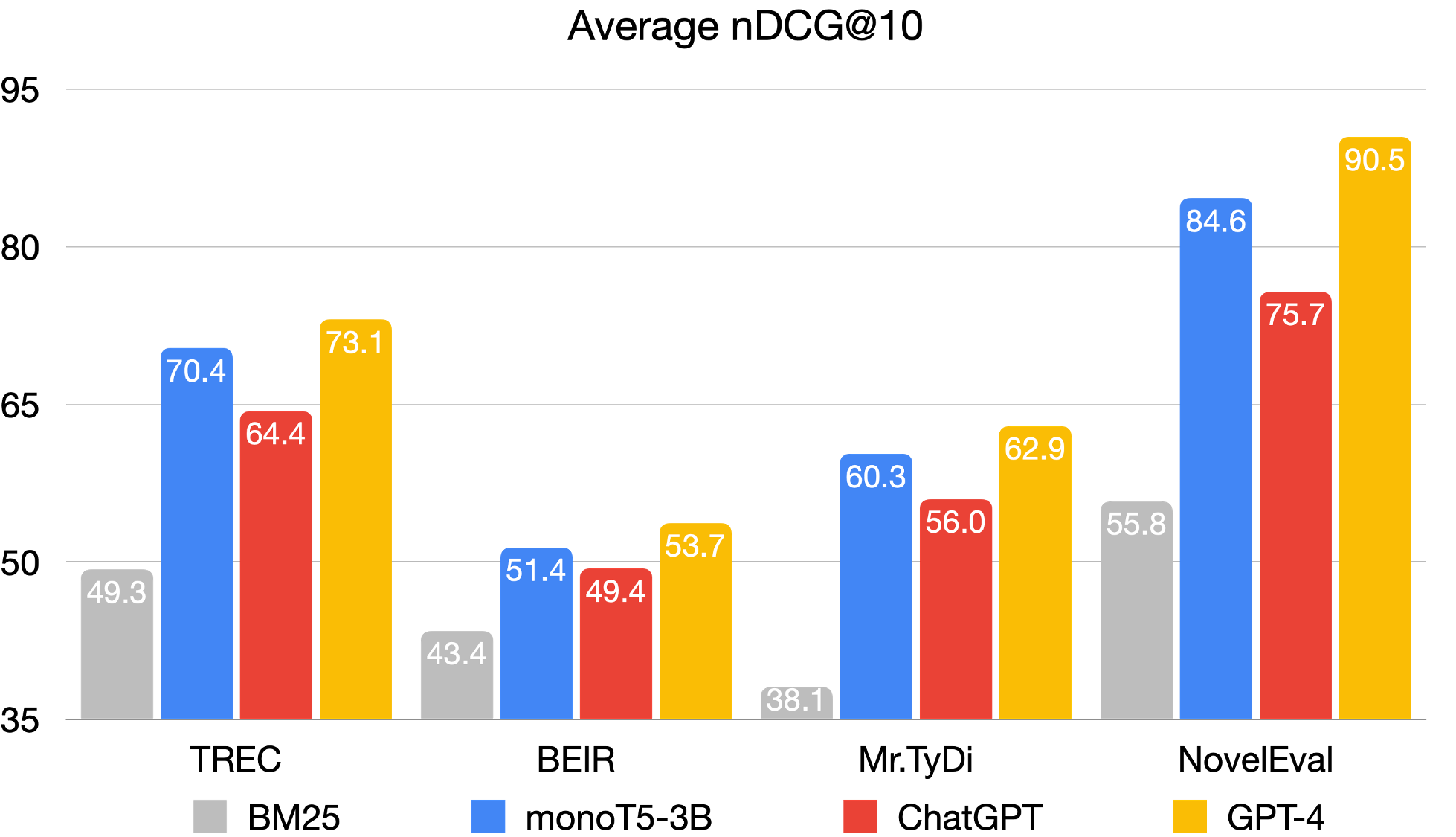
训练专业模型
下载数据和模型
| 文件 | 说明 | 链接 |
|---|---|---|
| marco-train-10k.jsonl | 从MS MARCO中抽样的10K个查询 | Google云端硬盘 |
| marco-train-10k-gpt3.5.json | ChatGPT预测的排列组合 | Google云端硬盘 |
| deberta-10k-rank_net | 使用RankNet损失函数训练的专业Deberta模型 | Google云端硬盘 |
| marco-train-100k.jsonl | 来自MS MARCO的100K个查询 | Google云端硬盘 |
| marco-train-100k-gpt3.5.json | ChatGPT对100K个查询的排列组合 | Google云端硬盘 |
将大语言模型蒸馏为小型专业模型
python specialization.py \
--model microsoft/deberta-v3-base \
--loss rank_net \
--data data/marco-train-10k.jsonl \
--permutation marco-train-10k-gpt3.5.json \
--save_path out/deberta-10k-rank_net \
--do_train true \
--do_eval true
或者使用accelerate在多个GPU上运行:
accelerate launch --num_processes 4 specialization.py \
--model microsoft/deberta-v3-base \
--loss rank_net \
--data data/marco-train-10k.jsonl \
--permutation marco-train-10k-gpt3.5.json \
--save_path out/deberta-10k-rank_net \
--do_train true \
--do_eval true
在基准测试上评估蒸馏模型
python specialization.py \
--model out/deberta-10k-rank_net \
--do_train false \
--do_eval true
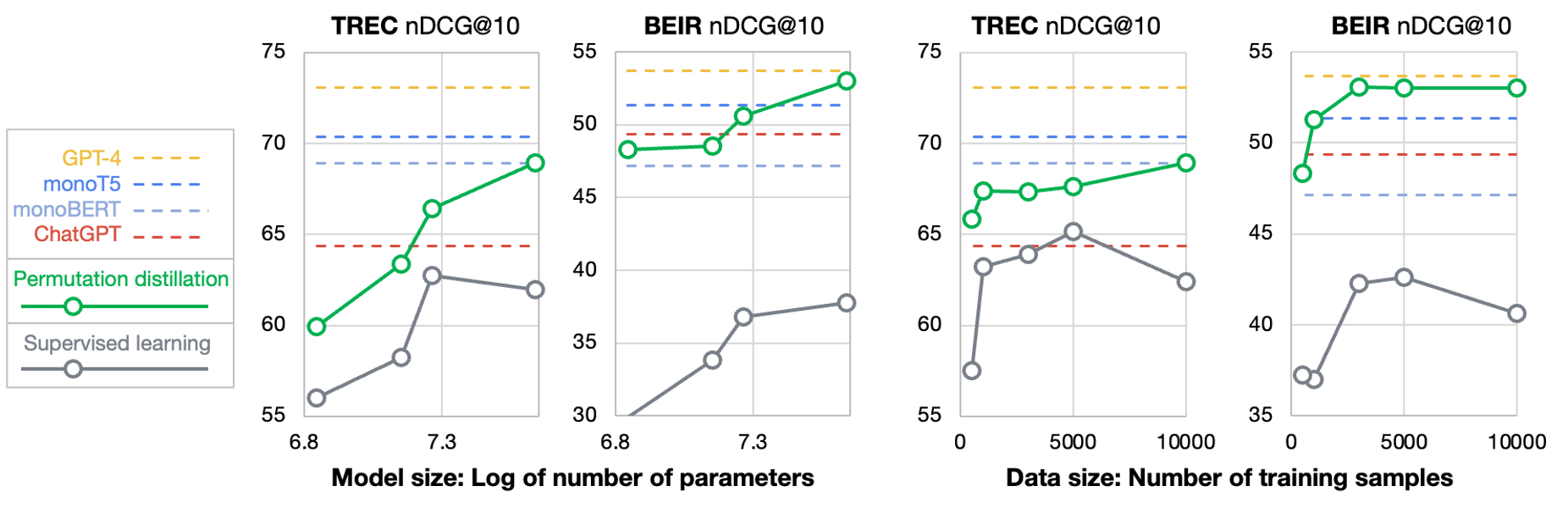
下图显示了不同模型大小和训练查询数量的蒸馏专业模型的结果。
引用
@article{Sun2023IsCG,
title={Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent},
author={Weiwei Sun and Lingyong Yan and Xinyu Ma and Pengjie Ren and Dawei Yin and Zhaochun Ren},
journal={ArXiv},
year={2023},
volume={abs/2304.09542}
}
@article{Sun2023InstructionDM,
title={Instruction Distillation Makes Large Language Models Efficient Zero-shot Rankers},
author={Weiwei Sun and Zheng Chen and Xinyu Ma and Lingyong Yan and Shuaiqiang Wang and Pengjie Ren and Zhumin Chen and Dawei Yin and Zhaochun Ren},
journal={ArXiv},
year={2023},
volume={abs/2311.01555},
}











