
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文SPPO: 自对弈偏好优化用于语言模型对齐



本代码库包含论文 自对弈偏好优化用于语言模型对齐 的官方代码和发布模型。
作者: Yue Wu*, Zhiqing Sun*, Huizhuo Yuan*, Kaixuan Ji, Yiming Yang, Quanquan Gu
[网页] [Huggingface] [论文]
🔔 新闻
- [2024年6月29日] 我们发布了 Gemma-2-9B-It-SPPO-Iter3,训练自 gemma-2-9b-it,AlpacaEval 2.0 LC-win 率达到了 53.27。
- [2024年6月25日] 我们的代码开源了!
- [2024年5月1日] 我们的论文在 arXiv 上发布:https://arxiv.org/abs/2405.00675。
内容目录
关于 SPPO
我们提出了一种新的自对弈框架 SPPO 用于语言模型对齐,并从自对弈框架中导出了一个新的学习目标(称为 SPPO 损失)来高效微调大型语言模型。
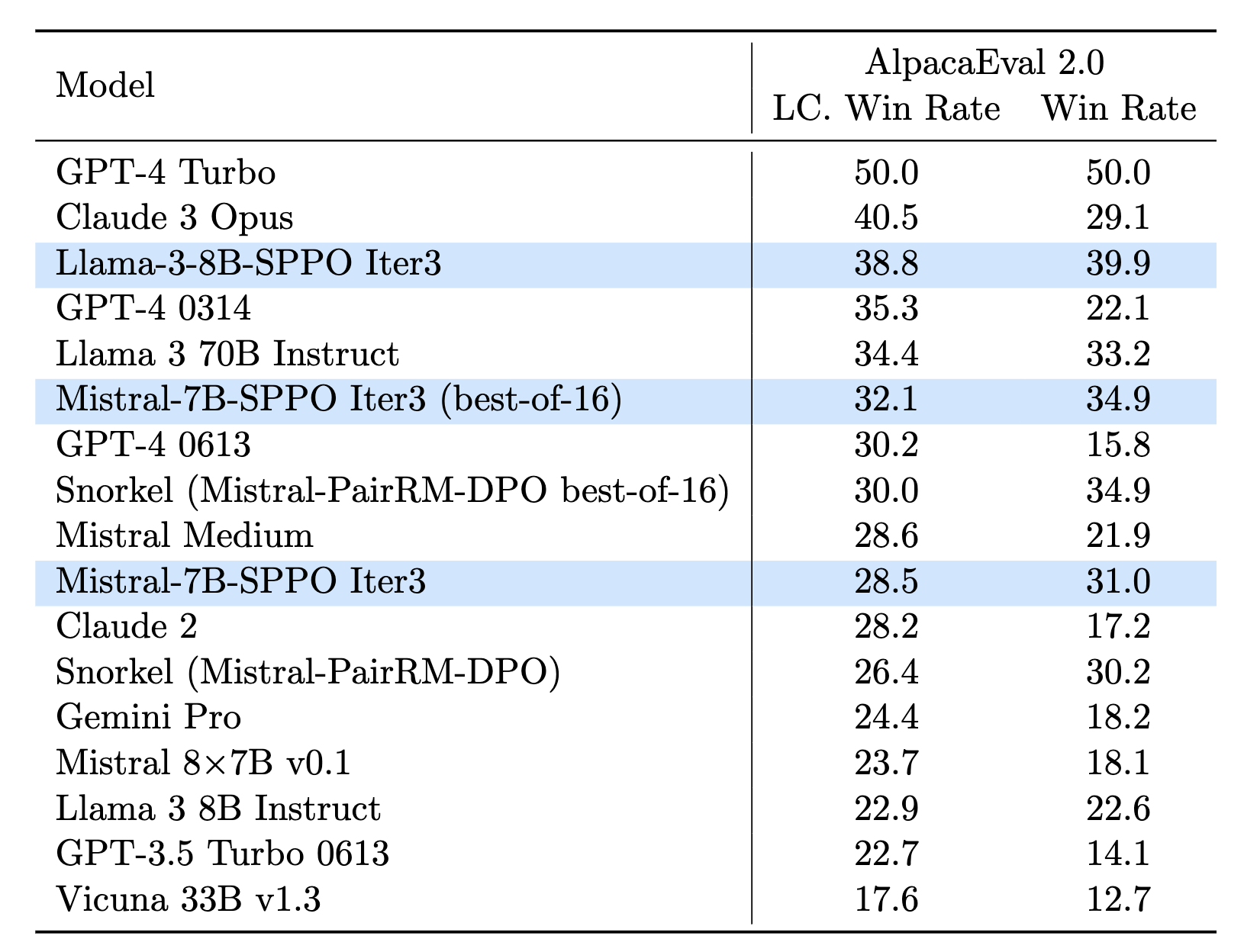
AlpacaEval 2.0 排行榜的正常和长度控制(LC)赢率百分比(%)。Mistral-7B-SPPO 能超越更大的模型,而 Mistral-7B-SPPO(best-of-16)能超越专有模型如 GPT-4(6/13)。Llama-3-8B-SPPO 表现更为出色。
SPPO 可以显著提升 LLM 的性能,而无需诸如来自 GPT-4 的响应或偏好等强外部信号。它可以超越使用直接偏好优化(DPO)等方法训练的模型。SPPO 在理论上有坚实的基础,确保 LLM 能在一般的、可能是非传递偏好下收敛到冯·诺依曼胜者(即纳什均衡),并通过多个数据集的大量评估进行实证验证。
更多详情,请查看我们的论文 这里。
基础模型和发布模型
| 模型 | AlpacaEval2.0 LC 胜率 | AlpacaEval2.0 胜率 |
|---|---|---|
| 🤗Mistral-7B-Instruct-v0.2 | 17.11 | 14.72 |
| 🤗Mistral-7B-SPPO Iter1 | 24.79 | 23.51 |
| 🤗Mistral-7B-SPPO Iter2 | 26.89 | 27.62 |
| 🤗Mistral-7B-SPPO Iter3 | 28.53 | 31.02 |
| 🤗Llama-3-8B-Instruct | 22.92 | 22.57 |
| 🤗Llama-3-8B-SPPO Iter1 | 31.73 | 31.74 |
| 🤗Llama-3-8B-SPPO Iter2 | 35.15 | 35.98 |
| 🤗Llama-3-8B-SPPO Iter3 | 38.77 | 39.85 |
| 🤗Gemma-2-9B-It | 45.08 | 35.62 |
| 🤗Gemma-2-9B-SPPO Iter1 | 48.70 | 40.76 |
| 🤗Gemma-2-9B-SPPO Iter2 | 50.93 | 44.64 |
| 🤗Gemma-2-9B-SPPO Iter3 | 53.27 | 47.74 |
环境配置
我们的训练代码基于alignment-handbook代码库。我们利用vllm进行生成,并使用pairRM进行排名。按照以下步骤设置您的环境:
-
创建虚拟环境:
conda create -n sppo python=3.10 conda activate sppo -
安装vllm生成模块:
pip install vllm -
安装PairRM:
git clone https://github.com/yuchenlin/LLM-Blender.git cd LLM-Blender pip install -e . -
下载并安装训练依赖:
git clone https://github.com/uclaml/SPPO.git cd SPPO pip install -e .
训练脚本
根据您选择的基础模型执行训练脚本:
-
对于 Mistral-7B-Instruct-v0.2:
bash run_sppo_mistral.sh -
对于 Llama-3-8B-Instruct:
bash run_sppo_llama-3.sh
这些脚本管理训练迭代、生成和PairRM排名过程。请注意某些脚本可能会尝试将数据集推送到Hugging Face Hub的UCLA-AGI组织下。确保您有写入权限,或相应地修改组织名称,或如有必要注释掉任何push_to_hub命令。各组件的详细脚本如下:
脚本细分:
- 生成:
python scripts/generate.py --model $MODEL --maxlen 2048 --output_dir $OUTPUT_DIR --prompts $PROMPTS
主要参数:
model: 指定用于生成的模型。在第一次迭代中,模型应该是mistralai/Mistral-7B-Instruct-v0.2或meta-llama/Meta-Llama-3-8B-Instruct。maxlen: 设置生成的最大令牌数。pairs: 确定每个提示生成的样本数量,默认设置为5。请注意,更改此数量不受整体管道支持。output_dir: 指定保存中间结果的目录路径。prompts: 定义用于生成的一组提示集。frac_len: 通过将提示划分为不同的部分,使vllm在多个GPU上运行。frac_len定义每个部分中的提示数量。使用示例参见generate.sh。data_frac: 与frac_len结合使用用于多GPU设置,data_frac表示当前GPU正在处理的数据部分。详细参见generate.sh。
- 排名:
python scripts/rank.py --output_dir $OUTPUT_DIR --prompts $PROMPTS
主要参数:
output_dir: 指定保存中间结果的目录路径。请注意,默认脚本尝试将数据集推送到 UCLA-AGI 组织的 Hugging Face 上。如果需要,您可能需要将其调整为您的组织,获得 UCLA-AGI 的写权限,或禁用push_to_hub命令。pairs: 设置每个提示生成的样本数量,默认值为 5。请注意,流水线中不支持其他数量。frac_len: 用于通过将提示分成不同的部分在多个 GPU 上启用 PairRM。frac_len决定每个部分中的提示数量。使用示例请参见generate.sh。data_frac: 类似于frac_len,此选项用于在多个 GPU 上运行 PairRM。它指定当前 GPU 处理的数据部分。示例请参见generate.sh。prompts: 定义用于生成的提示集。gpu: 指定用于排序的 GPU 索引,应与data_frac参数匹配。
- 训练:
bash scripts/pipeline.sh --model $MODEL --iter $ITER --dataset $DATASET --output_dir $OUTPUT_DIR --num 1
主要参数:
- model: 基础训练模型。
- dataset: 用于训练的数据集。
- output_dir: 输出模型的名称。
- num: 训练周期的数量。
评估
我们遵循既定的评估指南,并利用以下库:
我们在 models_configs 目录中提供了 AlpacaEval 2 中使用的模型配置。请注意,在我们发布模型后的初始阶段,我们使用略微修改的提示重新训练了模型。重新训练后的胜率与原始结果相当。
故障排除
如有与论文相关的问题,请通过电子邮件联系作者。如果您在使用代码时遇到问题或希望报告漏洞,请随时在我们的 GitHub 仓库中打开一个 issue。
引用
@article{wu2024self,
title={Self-play preference optimization for language model alignment},
author={Wu, Yue and Sun, Zhiqing and Yuan, Huizhuo and Ji, Kaixuan and Yang, Yiming and Gu, Quanquan},
year={2024}
}
致谢
我们感谢 The Alignment Handbook 作者对训练代码的基础贡献。我们还感谢 PairRM 在排序方面的使用以及 vllm 在生成方面的使用。











