
 访问官网
访问官网 Github
Github 文档
文档 论文
论文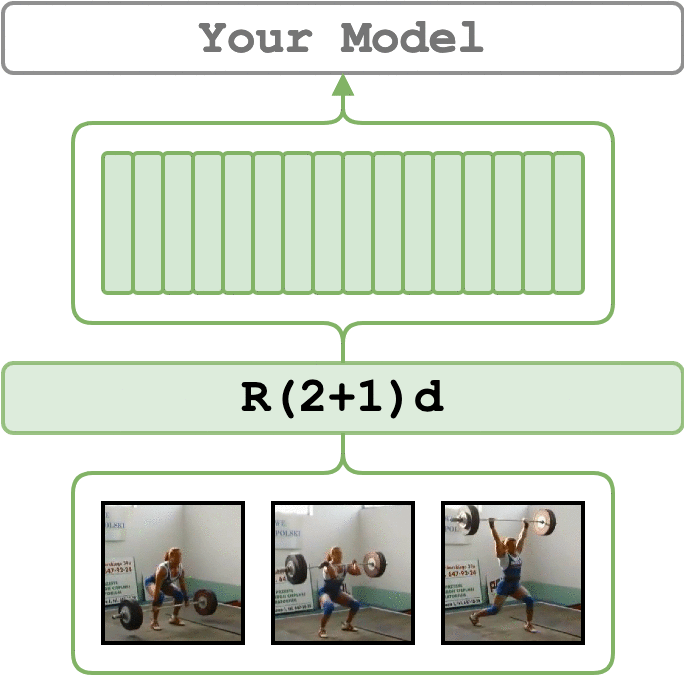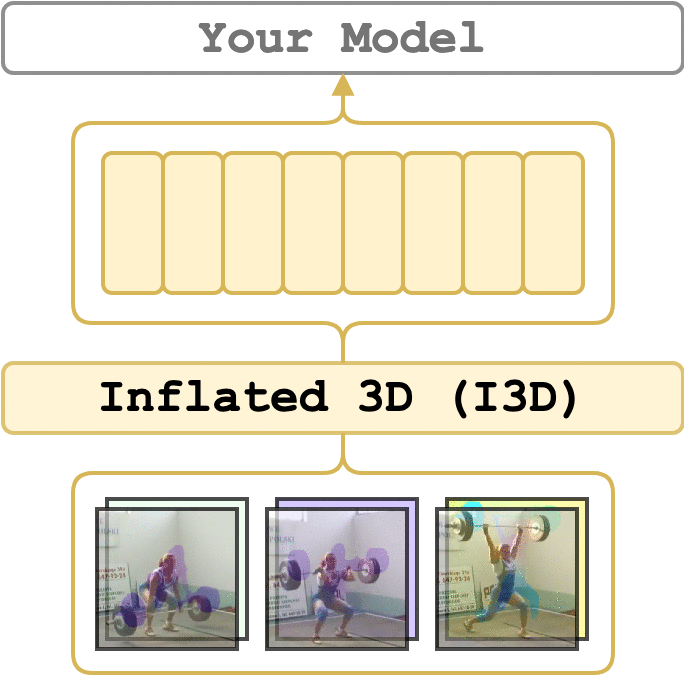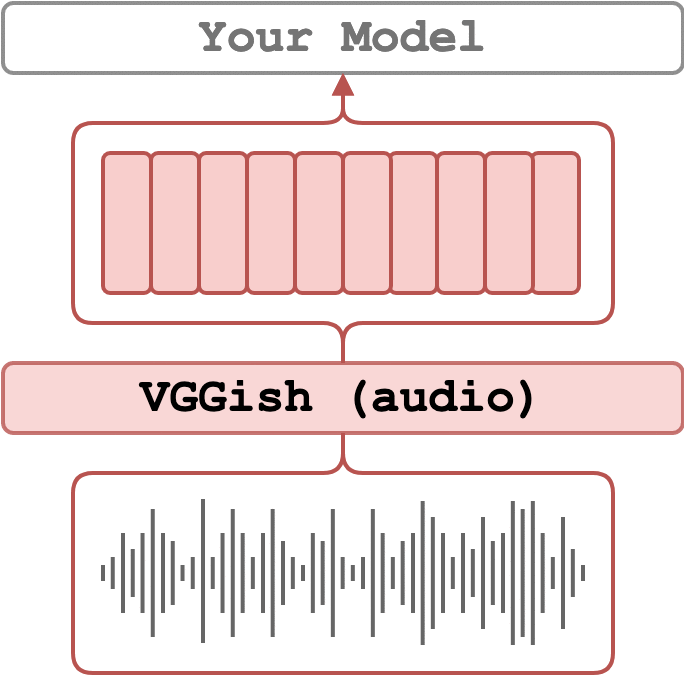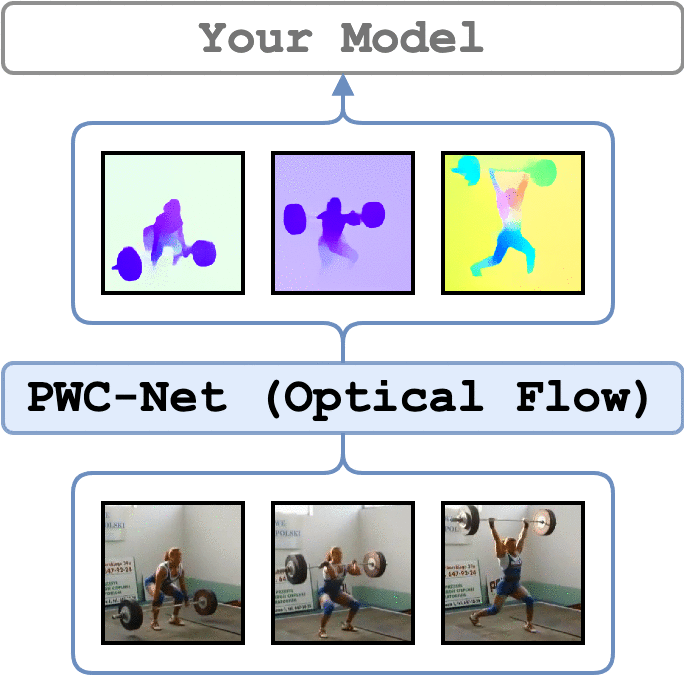
支持的模型
动作识别
声音识别
光流
逐帧特征
- TIMM 中的所有模型,如 ViT、ConvNeXt、EVA、Swin、DINO (ImageNet, LAION 等)
- CLIP
- ResNet-18,34,50,101,152 (ImageNet)
快速开始

或在本地使用 conda 运行:
# 克隆仓库并更改工作目录
git clone https://github.com/v-iashin/video_features.git
cd video_features
# 安装环境
conda env create -f conda_env.yml
# 加载环境
conda activate video_features
# 为示例视频提取 r(2+1)d 特征
python main.py \
feature_type=r21d \
device="cuda:0" \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
# 如果您有多个 GPU,只需从另一个终端使用另一个设备运行此命令
# device 也可以是 "cpu"
如果您更喜欢使用 Docker,我们提供了一个预安装环境的 Docker 镜像,支持所有模型。 查看 Docker 支持 文档页面。
多 GPU 和多节点设置
使用 video_features,可以轻松地在多个 GPU 之间并行提取特征。
只需在另一个终端中使用另一个 GPU(甚至是同一个)启动脚本,
指向相同的输出文件夹和输入视频路径即可。
脚本将检查特征是否已存在并跳过它们。
它还会尝试加载特征文件以检查是否损坏(即无法打开)。
这种方法允许您在上一个脚本因某种原因失败时继续提取特征。
如果您可以访问具有共享磁盘空间的 GPU 集群,您可以通过创建多个单 GPU 作业来扩展提取,使用相同的命令。
由于每次运行脚本时输入文件列表都会被打乱,因此您无需担心工作进程会处理相同的视频。 在罕见的冲突情况下,脚本将重写先前提取的特征。
输入
输入是视频文件的路径。 路径可以作为视频路径列表传递,也可以作为每行一个路径的文本文件传递。
输出
输出由 on_extraction 参数定义;默认情况下,它将特征打印到命令行。
可能的输出值为 ['print', 'save_numpy', 'save_pickle']。save_* 选项将特征保存在 output_path 文件夹中,文件名与输入视频文件相同,但扩展名为 .npy 或 .pkl。
使用于
如果您发现这个仓库对您的项目或论文有用,请告诉我。
致谢
- @Kamino666:添加了 CLIP 模型以及 Windows 和 CPU 支持(还有许多其他有用的功能)。
- @ohjho:添加了对 37 层 R(2+1)d 的支持。
- @borijang:解决了文件名的错误,改进了 I3D 检查点加载,并改进了代码风格。
- @bjuncek:帮助处理 timm 模型并进行离线讨论。
引用
如果您发现这个项目对您的研究有用,请考虑引用:
@misc{videofeatures2020,
title = {Video Features},
author = {Vladimir Iashin and other contributors},
year = {2020},
howpublished = {\url{https://github.com/v-iashin/video_features}},
}











