
 访问官网
访问官网 Github
Github 文档
文档PyDLM 

欢迎使用pydlm,这是一个灵活的Python时间序列建模库。该库基于贝叶斯动态线性模型(Harrison和West,1999),并针对快速模型拟合和推断进行了优化。
更新
-
当前GitHub版本的更新:
- 修复了coveralls,使所有PR合并都会报告覆盖率变化。
- 使用
sphinx更新了pydlm.github.io的文档。在类参考中公开了更完整的API。 - 简化了
longSeason组件的实现,并将longSeason和autoReg变为无状态。 - 为
dlmAccessModule添加了测试,并修复了一些测试未被coveralls运行的问题。
-
PyPI上发布了0.1.1.13版本。
- 将所有不必要的
print()迁移到默认的Python日志操作,如logging.info、logging.warning和logging.critical。 - 用户现在可以设置模型日志级别以抑制模型运行期间不必要的信息。
- 仅打印警告信息的示例:
... my_model.setLoggingLevel('WARNING') my_model.fit()- 通过
pip-compile和requirements.txt更新了包版本管理。
- 将所有不必要的
安装
你可以通过pypi获取软件包(当前版本0.1.1.11):
$ pip install pydlm
你也可以从github获取最新版本:
$ git clone git@github.com:wwrechard/pydlm.git pydlm
$ cd pydlm
$ pip install pip-tools
$ pip install -r requirements.txt
$ pip install -e . --no-deps
pydlm依赖以下模块:
numpy(核心功能)matplotlib(绘图结果)Sphinx(生成文档)unittest(测试)
谷歌数据科学博文示例
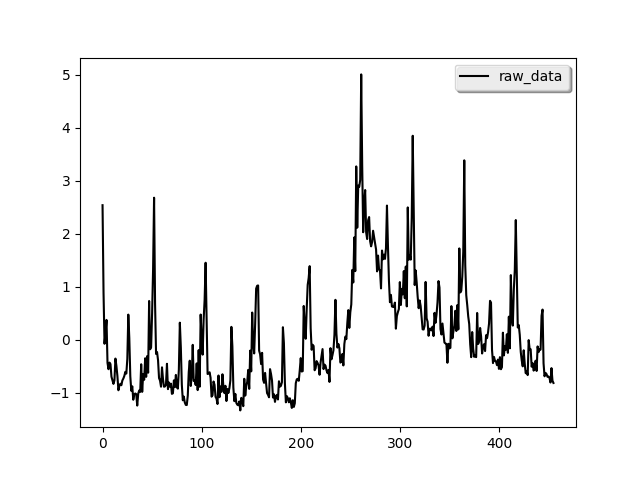
我们使用谷歌数据科学博文中的示例来展示如何使用pydlm分析真实世界数据。代码和数据位于examples/unemployment_insurance/...目录下。数据集包含2004-2012年期间每周初次申请失业保险的数量,可从R包bsts(一个流行的R时间序列建模包)获取。原始数据如下所示(左图)
一个简单模型
遵循谷歌的博文,我们首先构建一个仅包含局部线性趋势和季节性组件的简单模型。from pydlm import dlm, trend, seasonality
# 线性趋势
linear_trend = trend(degree=1, discount=0.95, name='linear_trend', w=10)
# 季节性
seasonal52 = seasonality(period=52, discount=0.99, name='seasonal52', w=10)
# 构建简单dlm
simple_dlm = dlm(time_series) + linear_trend + seasonal52
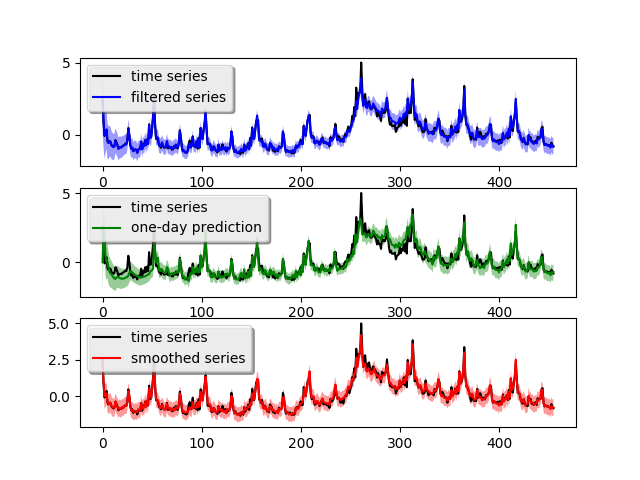
在实际代码中,时间序列数据存储在变量time_series中。degree=1表示趋势是线性的(2表示二次),period=52表示季节性周期为52。由于季节性通常更稳定,我们将其折扣因子设为0.99。对于局部线性趋势,我们使用0.95以允许一些灵活性。w=10是对每个组件方差的先验猜测,数字越大表示不确定性越高。关于这些参数的实际含义,请参阅用户手册。构建模型后,我们可以拟合模型并绘制结果(如上图右图所示)
# 拟合模型
simple_dlm.fit()
# 绘制拟合结果
simple_dlm.turnOff('data points')
simple_dlm.plot()
蓝色曲线是前向滤波结果,绿色曲线是一天ahead预测,红色曲线是后向平滑结果。曲线周围的浅色区域是置信区间(你可能需要放大才能看到)。一天ahead预测显示这个简单模型在某种程度上捕捉到了时间序列的特征,但在第280周左右(2008-2009年之间)的危机高峰期失去准确性。一天ahead均方预测误差为0.173,可以通过以下调用获得:
simple_dlm.getMSE()
我们可以将时间序列分解为其各个组成部分:
# 绘制每个组件(将时间序列归因于每个组件)
simple_dlm.turnOff('predict plot')
simple_dlm.turnOff('filtered plot')
simple_dlm.plot('linear_trend')
simple_dlm.plot('seasonal52')


# 绘制使用前351周数据预测接下来200周的结果
simple_dlm.plotPredictN(date=350, N=200)
# 绘制使用前251周数据预测接下来200周的结果
simple_dlm.plotPredictN(date=250, N=200)
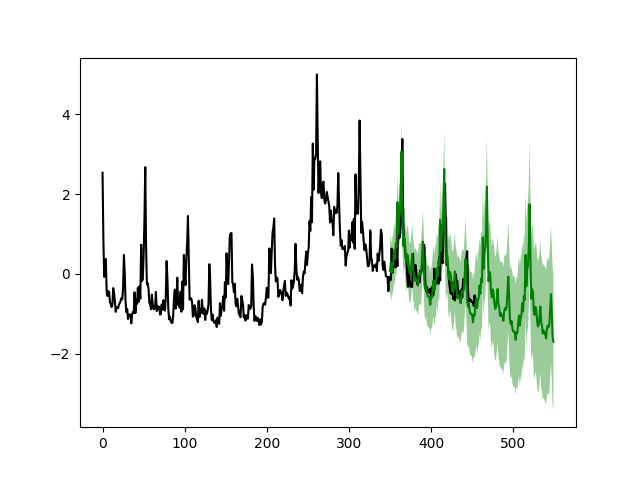

从图中我们可以看到,在2008-2009年左右(第280周)的危机高峰之后,简单模型能够准确预测接下来的200周(左图),前提是给定前351周的数据。然而,如果预测开始于第280周之前,模型就无法捕捉到接近高峰时的变化(右图)。
动态线性回归
现在我们利用数据文件中的额外变量构建一个更复杂的模型。这些额外变量在实际代码中存储在`features`变量中。要构建动态线性回归模型,我们只需添加一个新组件:# 构建动态回归模型
from pydlm import dynamic
regressor10 = dynamic(features=features, discount=1.0, name='regressor10', w=10)
drm = dlm(time_series) + linear_trend + seasonal52 + regressor10
drm.fit()
drm.getMSE()
# 绘制拟合结果
drm.turnOff('data points')
drm.plot()
dynamic是用于建模动态变化预测因子的组件,它接受features作为参数。上述代码绘制了拟合结果(左上图)。
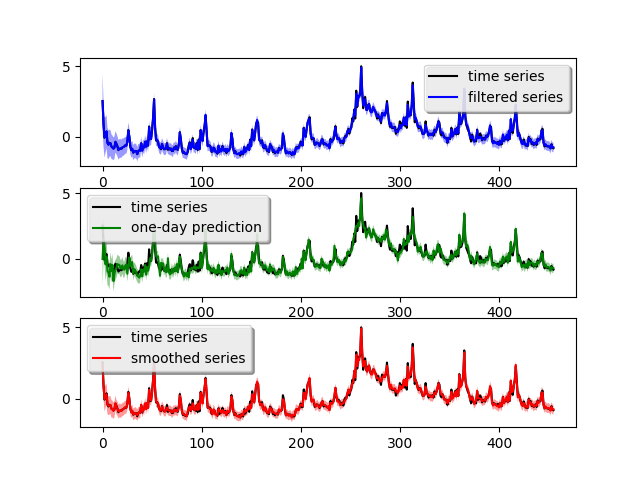


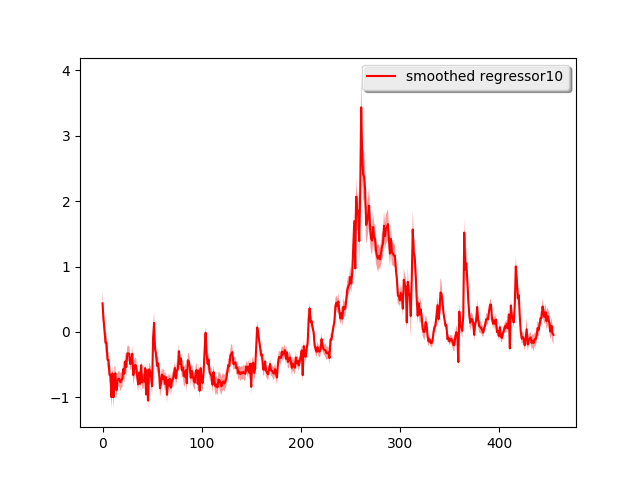
一天ahead预测的结果比简单模型要好得多,特别是在危机高峰附近。平均预测误差为0.099,比简单模型提高了100%。同样,我们也将时间序列分解为三个组成部分:
drm.turnOff('predict plot')
drm.turnOff('filtered plot')
drm.plot('linear_trend')
drm.plot('seasonal52')
drm.plot('regressor10')
这次,时间序列的形状主要归因于回归器,而线性趋势看起来更加线性。如果我们再次进行长期预测,即使用前301周的数据预测接下来的150周,以及使用前251周的数据预测接下来的200周:
drm.plotPredictN(date=300, N=150)
drm.plotPredictN(date=250, N=200)
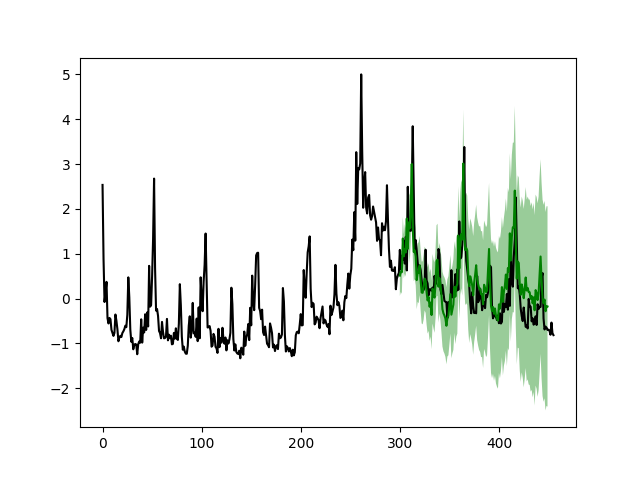
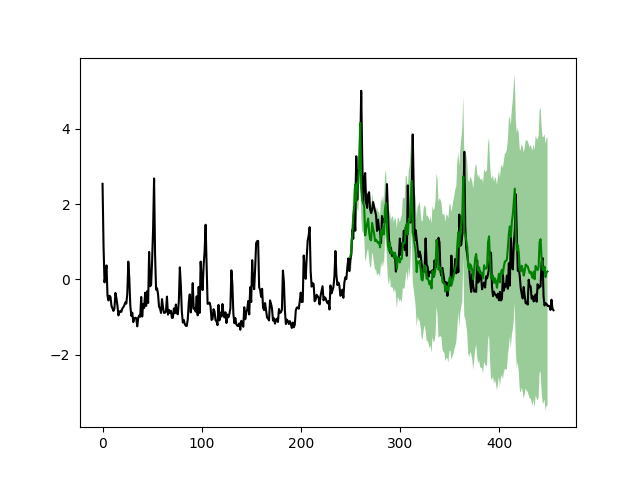
与简单模型相比,结果看起来好多了。











