
 Huggingface
Huggingface项目介绍
项目背景
hubert-base-ch-speech-emotion-recognition 是一个专注于语音情感识别的模型。该模型使用 TencentGameMate/chinese-hubert-base 作为预训练模型,并在 CASIA 数据集上进行训练。该数据集包含 1200 个样本,这些样本由演员用中文表达六种不同的情感进行录制。这些情感包括:
- 愤怒(anger)
- 恐惧(fear)
- 开心(happy)
- 中立(neutral)
- 悲伤(sad)
- 惊讶(surprise)
使用方法
模型主要通过以下步骤使用:
- 使用 librosa 库加载音频文件。
- 使用预训练好的模型提取音频特征。
- 通过自定义分类层处理特征,并输出情感预测类别。
以下是模型的一个简单使用示例:
import os
import random
import librosa
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoConfig, Wav2Vec2FeatureExtractor, HubertPreTrainedModel, HubertModel
model_name_or_path = "xmj2002/hubert-base-ch-speech-emotion-recognition"
duration = 6
sample_rate = 16000
config = AutoConfig.from_pretrained(
pretrained_model_name_or_path=model_name_or_path,
)
# 省略一些代码...
file_path = [f"test_data/{path}" for path in os.listdir("test_data")]
path = random.sample(file_path, 1)[0]
predict(path, processor, model)
模型训练设置
- 数据集的分割比例为:训练集60%,验证集20%,测试集20%。
- 使用的随机种子为34。
- 批量大小设置为36。
- 学习率设置为2e-4。
- 优化器采用 AdamW,参数 beta=(0.93, 0.98),权重衰减为0.2。
- 学习率调度器为 Step_LR,步长为10,衰减率为0.3。
- 分类器的 dropout 比例为0.1。
模型的优化器参数实现如下:
for name, param in model.named_parameters():
if "hubert" in name:
parameter.append({'params': param, 'lr': 0.2 * lr})
else:
parameter.append({'params': param, "lr": lr})
评估指标
模型在测试集上的损失为 0.1165,准确率为 97.2%。以下图像显示了训练集和验证集的损失曲线和准确率曲线:
-
准确率曲线
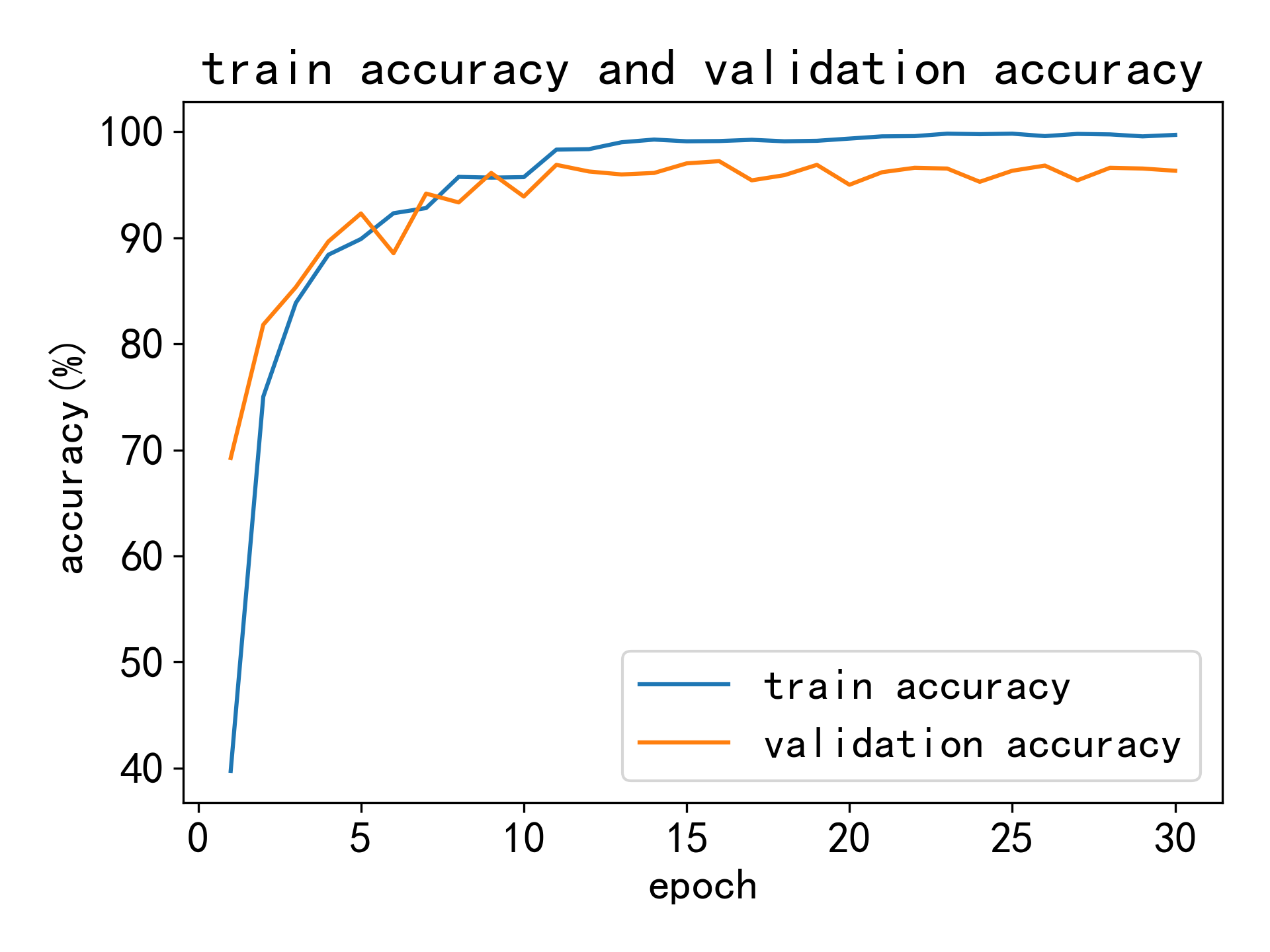
-
损失曲线
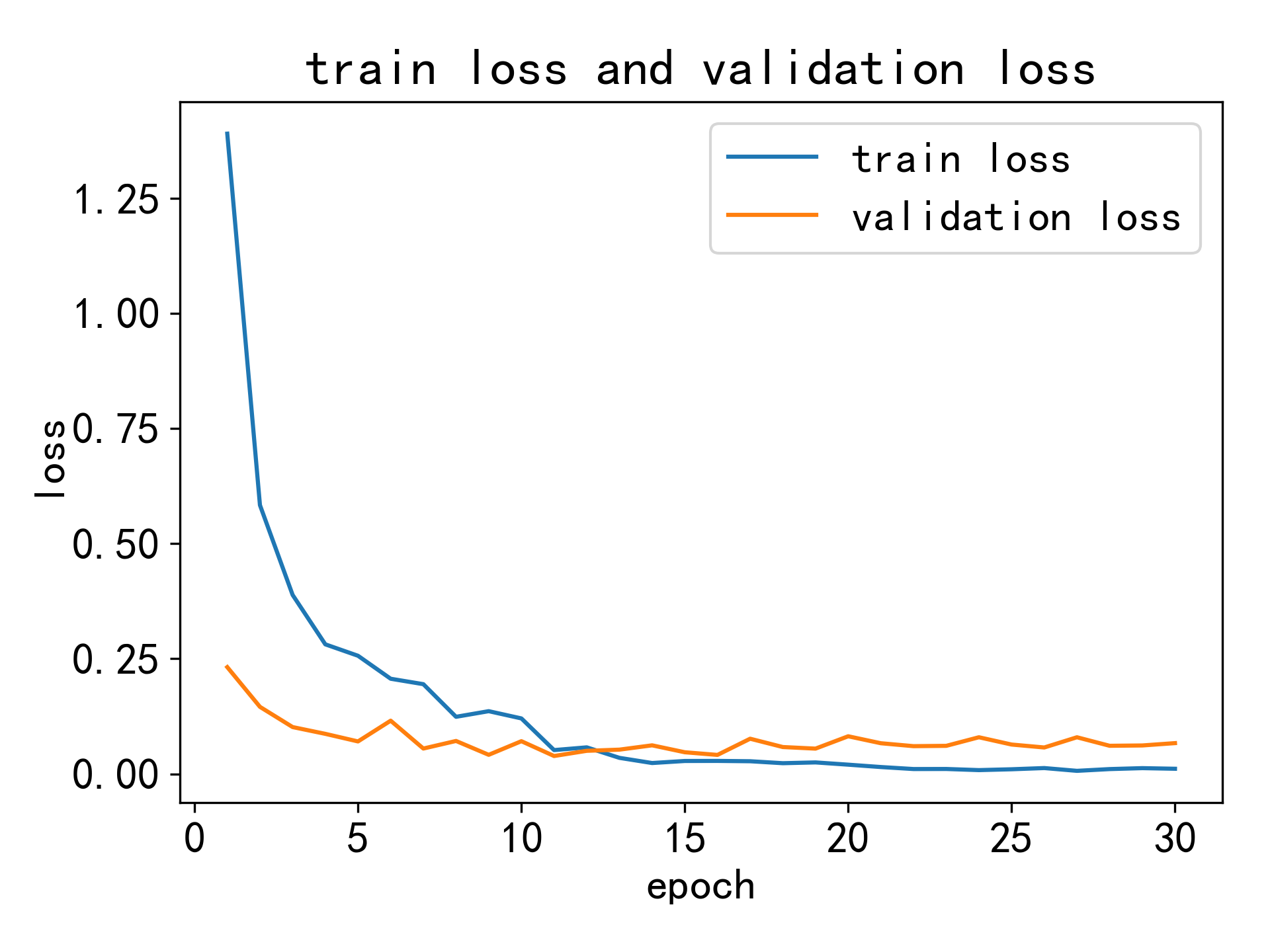
通过这些评估指标可以看出,该模型在语音情感识别任务上表现优异,能够准确地识别多种情感状态。










