
 访问官网
访问官网 Github
Github 文档
文档BW尝试的新方法!
新版本
v0.3.3 (建议更新)
- 更新到Chromium 112.0.5590.0。
- 更好地支持BW书籍页码模式,支持小说。
在发布页面下载或点击这里:Windows x64 发布版 v0.3.3
v0.3.2
此版本为BW提供了以下优秀功能:
- 可以下载封面(如果封面图片是jpeg格式,请在分享前检查或最好转换为png格式,因为jpeg文件会包含你的BW账户信息)。
- 可以使用页码自动命名图片,你可以从任意页面开始,向前或向后进行!
- 可以使用BW的uuid命名文件夹,不再使用随机命名。
- 不再跳过空白或重复页面,不再使用图像哈希检查重复页面,性能更佳。
示例截图:
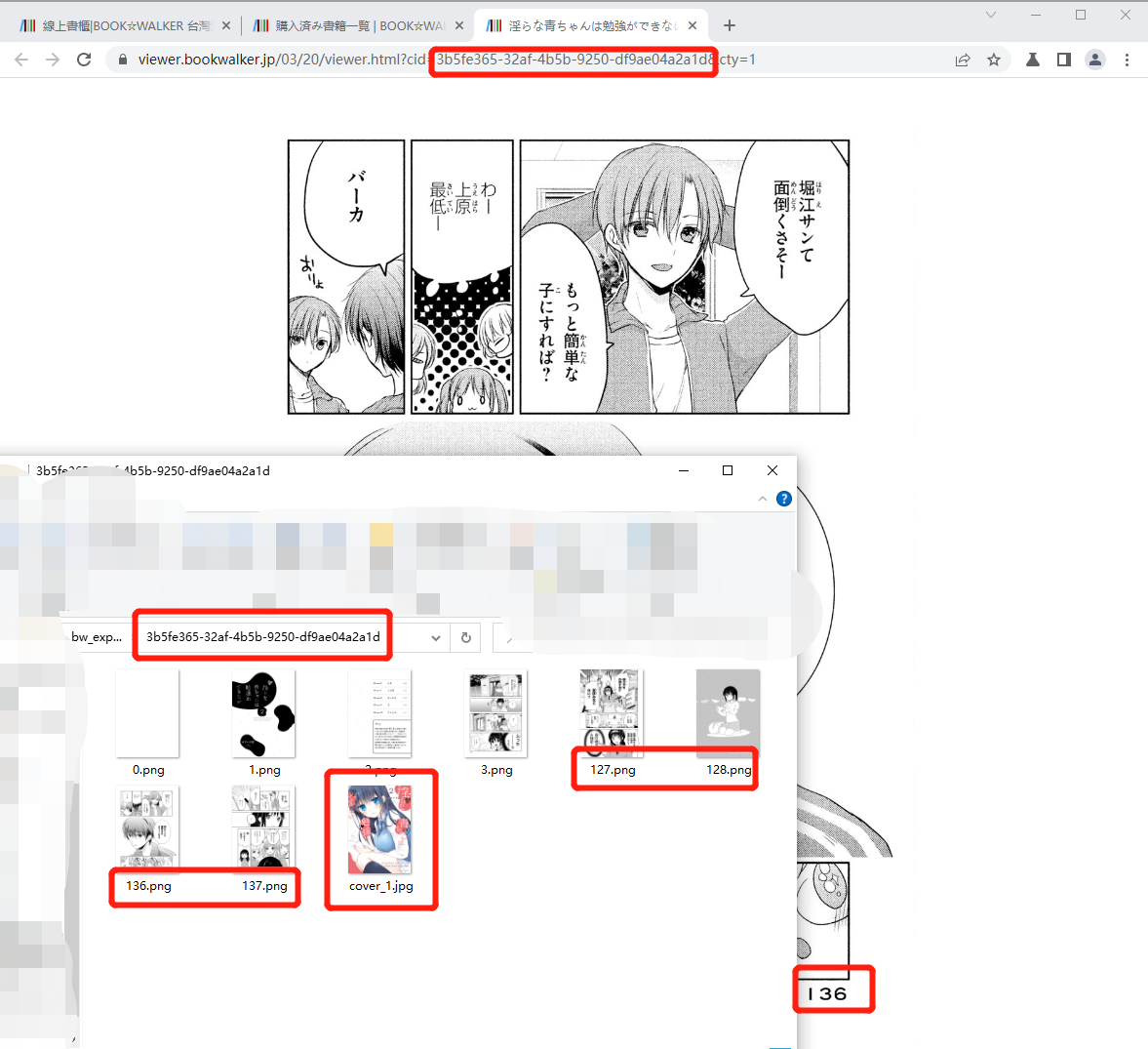
如果在下载某些漫画时发现文件名全变成了"cover_or_extra_xxx",请提交bug。可能BW存在我未见过的URL模式或他们改变了模式,应该覆盖这些情况以确保页码正常工作。
在发布页面下载或点击这里:Windows x64 发布版 v0.3.2
v0.3.1
此版本改进了保存快照的性能,如果你在下载过程中遇到浏览器变得非常慢的问题,请尝试新版本。
在发布页面下载或点击这里:Windows x64 发布版 v0.3.1
v0.3
修复了部分宽度小于800px的漫画无法下载的问题,详见#113。
在发布页面下载或点击这里:Windows x64 发布版 v0.3
v0.2.1
将Chromium更新至109.0.5393,可能修复了一些问题。
在发布页面下载或点击这里:Windows x64 发布版 v0.2.1
v0.2
此版本基于Chromium 106.0.5243.0,变更如下:
- 支持
https://ebook.tongli.com.tw,下载的图片将保存在C:\bw_export_data\TONGLI_URL_STRING - 支持
https://www.dlsite.com,但这是保存缓存图片,所以最后3~4页应该按以下方式下载(假设有10页):- 浏览第1页到第10页(确保当前页面完全加载后再进入下一页)。
- 你会发现在第10页时,可能只有1-7页的图片。
- 从第10页返回到第5页,你会发现最后几页已保存。(但可能顺序相反)
- 目前我们无法做得比这更好。
- 适用于
https://book.dmm.com,使用以下脚本移动页面:
window.i=0;setInterval(()=>{NFBR.a6G.Initializer.views_.menu.options.a6l.moveToPage(window.i);console.log(window.i);window.i++;},3000)
上述脚本适用于DMM,对于BW请使用以下脚本:
window.i=0;setInterval(()=>{NFBR.a6G.Initializer.L7v.menu.options.a6l.moveToPage(window.i);console.log(window.i);window.i++;},3000)
- BW可能稍快一些,并可能下载一些宽度大于高度的图片。
在发布页面下载或点击这里:Windows x64 发布版 v0.2
使用方法(与旧版相同):
- 解压
BW-downloader-chrome-bin.zip文件。 - 打开
powershell或cmd,cd到解压后的浏览器目录。 - 使用命令行
.\chrome.exe --user-data-dir=c:\bw-downloader-profile --no-sandbox打开浏览器。 - 浏览漫画,漫画将保存到
C:\bw_export_data
请勿将其用于其他网站,仅用作漫画下载器,它不如普通Chrome浏览器安全!
旧版本
在发布页面下载或点击这里:Windows x64 发布版 v0.1
如果你正在寻找下载BW的方法,请尝试这个方法,这真的是个值得尝试的好方法,你会喜欢的!
对于coma,请参见下文。
现在有了一个新方法,使用定制的chromium浏览器,可以非常轻松地下载BW原始图像及其原始尺寸。它可以下载漫画和小说,可能适用于所有使用canvas渲染页面的网站(目前仅在BW上测试过)。
这只是一个开发版本,可能存在漏洞和崩溃问题,但你现在可以下载定制浏览器并尝试使用。
请勿将其用于其他网站,仅作为BW下载器使用,它不如普通Chrome浏览器安全!
克隆此仓库或仅下载BW-downloader-chrome-bin.zip
-
解压文件
BW-downloader-chrome-bin.zip。 -
打开
powershell或cmd,cd到解压后的浏览器目录。 -
使用命令行
.\chrome.exe --user-data-dir=c:\bw-downloader-profile --no-sandbox打开浏览器。 -
调整浏览器窗口大小,使其变小并只能显示一个漫画页面,如下例所示
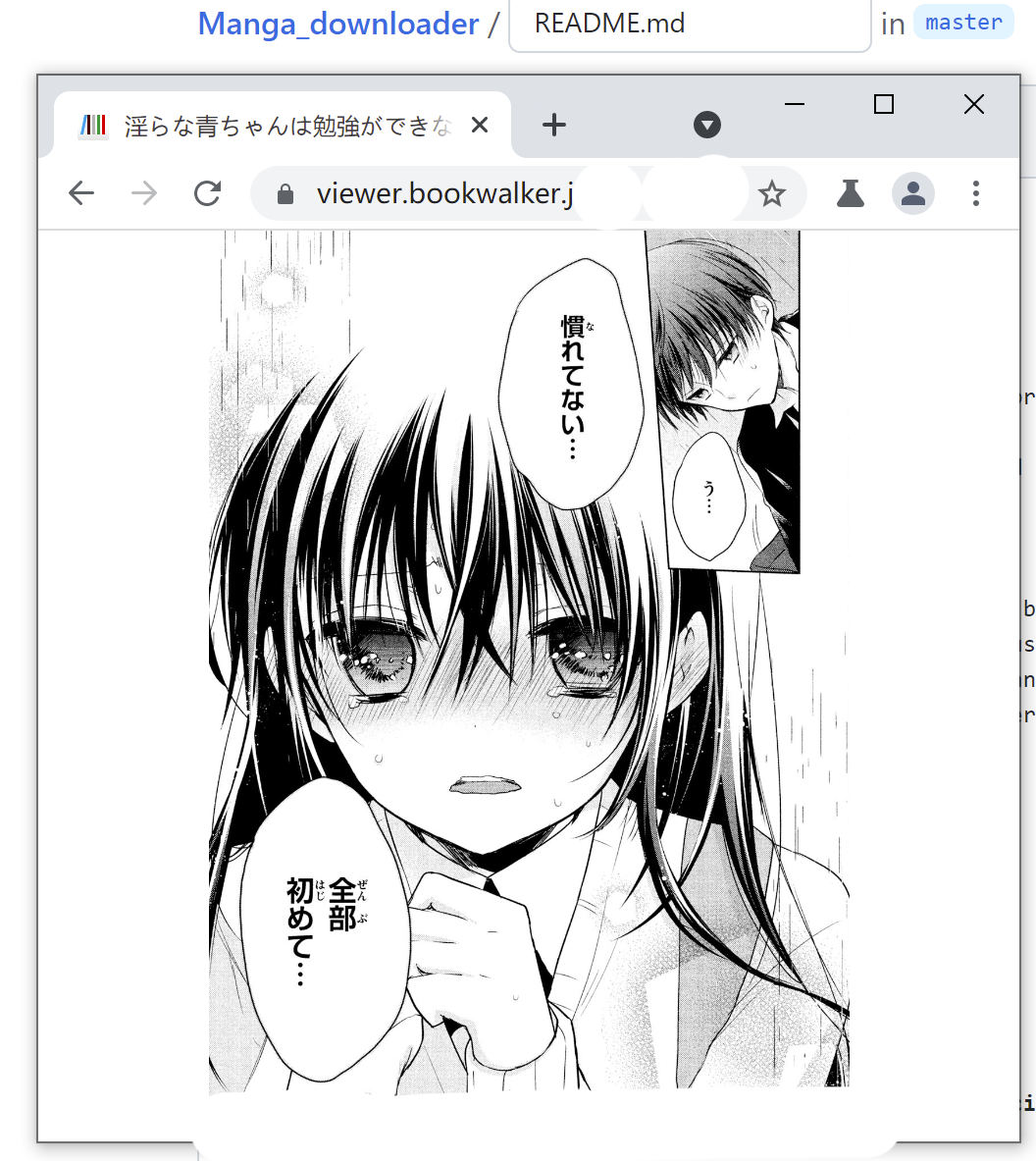
-
现在你可以访问BW网站,登录并打开想要下载的漫画,记得在打开前重置漫画的阅读状态。
-
按
F12,将其设为单独窗口(见下图),然后运行以下脚本(只需进入console复制粘贴代码,按回车)以自动翻页。如果你的网络良好,可以将3000改为更小的数值,3000表示3000毫秒即3秒,每3秒翻到下一页。你也可以手动点击鼠标左键/使用键盘方向键/使用键盘模拟软件来翻页,选择你喜欢的方式,只要确保页面在移动即可。
window.i=0;setInterval(()=>{NFBR.a6G.Initializer.L7v.menu.options.a6l.moveToPage(window.i);console.log(window.i);window.i++;},3000)如果这不起作用并显示'Uncaught TypeError: Cannot read properties of undefined (reading 'menu') at
:1:54',说明BW已更新了js,你可以尝试在控制台中寻找,只需尝试 NFBR.a6G.Initializer.*.menu不为undefined,其中*是新的对象名;或者你可以提交一个bug。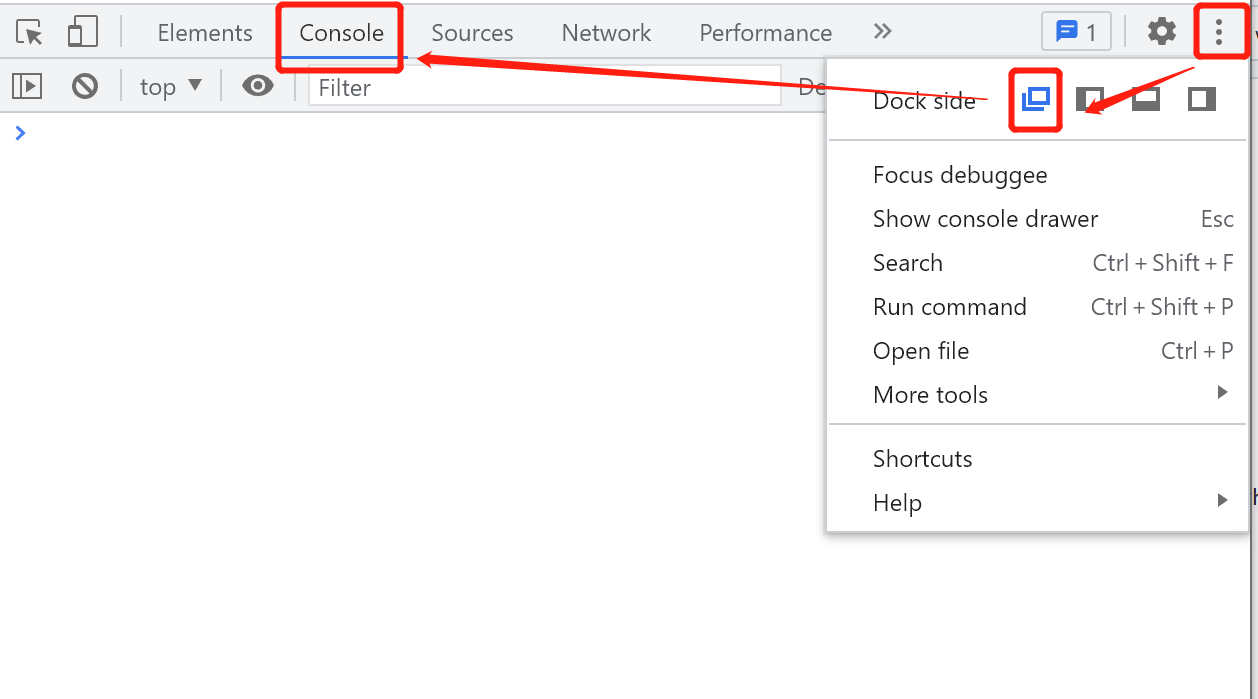
-
现在你可以查看
C:\bw_export_data,你会发现一个随机UUID文件夹,里面包含了所有的漫画图片。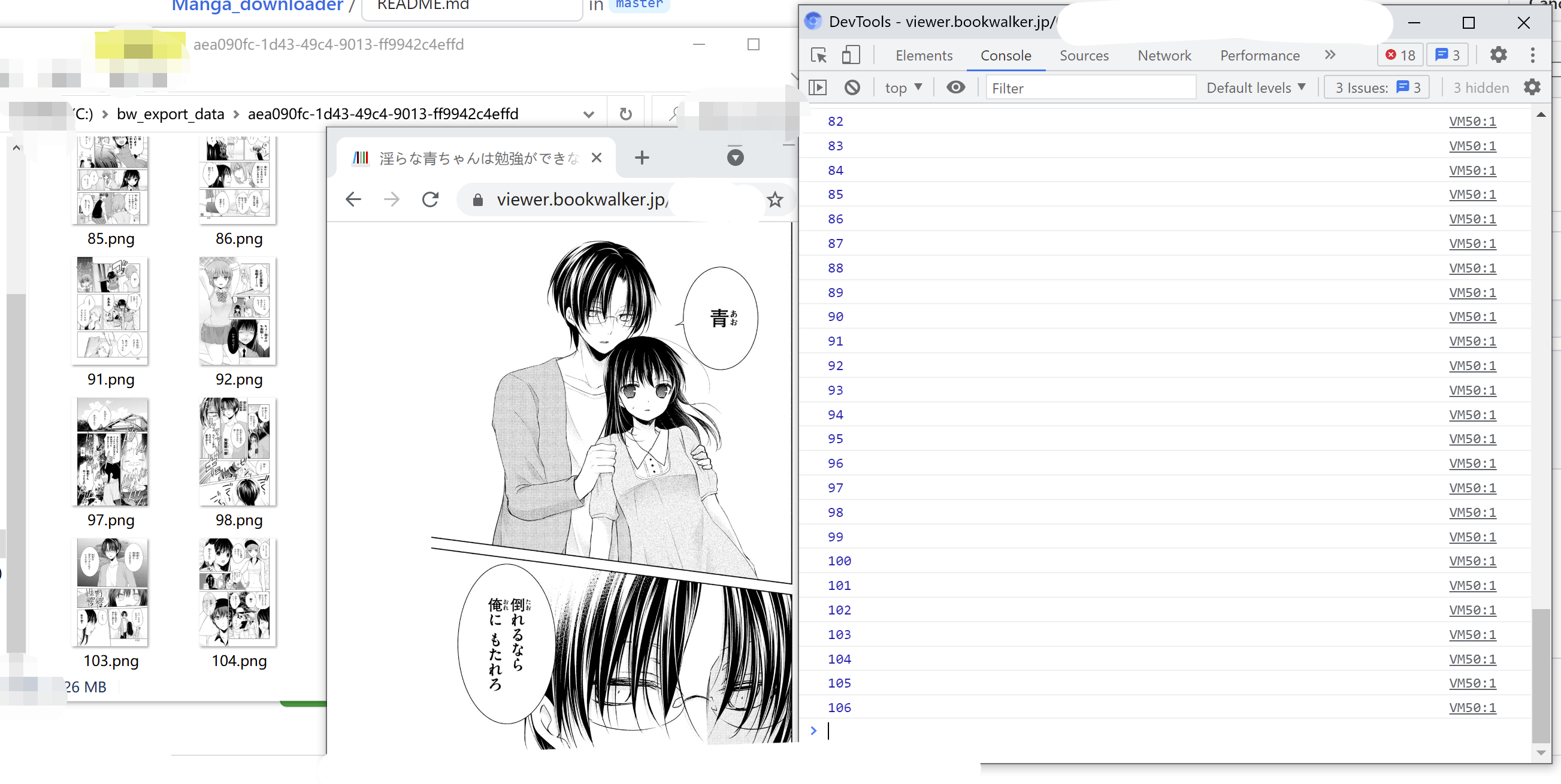
如果你想同时下载多部漫画,只需打开你想要的多个漫画,并执行步骤5到6。
这种方法非常易用、稳定,无需寻找任何分辨率或cookies,而且可以下载没有条形码的真正原始图像。
也许将来会为其添加新的浏览器界面,可以点击下载。
现在可能无法下载封面页。
仅在Windows上构建,目前没有其他平台的程序。
如果你发现任何问题,请提交bug,谢谢!
漫画下载器
一个使用selenium的漫画下载框架。
现在支持以下网站:
程序会自动检查给定URL的网站
如果你给定的网站不受支持,程序将抛出错误。
现在支持只登录一次就可以下载多部漫画
你需要准备以下信息:
- 漫画URL
- Cookies
- 图片目录(存放图片的位置,文件夹名)
- 对于某些网站,你需要查看图片大小并在
res中设置。Cmoa.jp不需要这个。
如何使用
所有设置
所有设置都在main.py中。
settings = {
# 漫画URL,应该是同一个网站
'manga_url': [
'URL_1',
'URL_2'
],
# 你的cookies
'cookies': '在此处填入你的COOKIES',
# 存储漫画的文件夹名,顺序与manga_url相同
'imgdir': [
'URL_1的IMGDIR',
'URL_2的IMGDIR'
],
# 分辨率,(宽度,高度),对于cmoa.jp这不重要。
'res': (1393, 2048),
# 每页的睡眠时间(秒),通常不需要更改。
'sleep_time': 2,
# 页面加载等待时间(秒),如果你的网络良好,可以减少这个参数。
'loading_wait_time': 20,
# 裁剪图片,(左,上,右,下)单位为像素,None表示不裁剪图片。这通常用于裁剪边缘。
# 比如(0, 0, 0, 3)表示从图片底部裁剪3个像素。
'cut_image': None,
# 文件名前缀,如果你想要文件名像'klk_v1_001.jpg',在这里写'klk_v1'。
'file_name_prefix': '',
# 文件名数字位数,如果你想要文件名像'001.jpg',在这里写3。
'number_of_digits': 3,
# 起始页,如果你想从第3页开始下载,将此设置为3,None表示从0开始
'start_page': None,
# 结束页,如果你想下载到第10页,将此设置为10,None表示直到结束
'end_page': None,
}
安装环境 & 如何获取URL/Cookies
这个程序现在适用于Chrome,如果你使用其他浏览器,请查看此页面
-
安装python包_selenium_和_pillow_,并获取_Google chrome驱动程序_。
- 对于_selenium_和_pillow_:
pip install selenium pip install Pillow # 这个undetected_chromedriver是为了防止我们被BW检测到 pip install undetected_chromedriver -
在main.py中更改
IMGDIR以指定存放漫画的位置。 -
在程序中添加你的cookies。
记得使用F12查看cookies!
因为某些http only cookies无法通过javascript看到!
记得访问以下链接获取cookies!
-
对于[Bookwalker.jp]的cookies,请访问这里。
-
对于[Bookwalker.com.tw]的cookies,请访问这里。
-
对于[www.cmoa.jp]的cookies,请访问这里,并且必须使用插件EditThisCookie获取cookies,可以在这里下载Chrome版本。
-
对于
EditThisCookie,可以用于上述任何网站,但对于cmoa,你必须使用以下方法:- 进入
EditThisCookie的用户偏好设置(chrome-extension://fngmhnnpilhplaeedifhccceomclgfbg/options_pages/user_preferences.html) - 将cookie导出格式设置为
分号分隔的name=value对 - 访问cmoa,点击
EditThisCookie图标,然后点击导出按钮 - 将文件中的cookies(在
// Example: http://www.tutorialspoint.com/javascript/javascript_cookies.htm之后)复制到程序中
- 进入
-
对于传统方式:
- 打开页面。
- 按F12。
- 点击"网络"。
- 刷新页面。
- 找到第一个"profile"请求,点击它。
- 在右侧,会有"请求头",前往那里。
- 找到"cookie:...",复制"cookie:"后面的字符串,粘贴到main.py的YOUR_COOKIES_HERE处。
-
-
在main.py中更改manga_url。
-
对于[Bookwalker.jp]
首先前往購入済み書籍一覧,你可以在这里找到所有你的漫画。
这次的URL是你的漫画**"この本を読む"**按钮的URL。
右键点击这个按钮,然后点击**"复制链接地址"**。
URL应以member.bookwalker.jp开头,而不是viewer.bookwalker.jp。这里我们以漫画【期間限定 無料お試し版】あつまれ!ふしぎ研究部 1为例。
这是あつまれ!ふしぎ研究部 1的URL:https://member.bookwalker.jp/app/03/webstore/cooperation?r=BROWSER_VIEWER/640c0ddd-896c-4881-945f-ad5ce9a070a6/https%3A%2F%2Fbookwalker.jp%2FholdBooks%2F
-
对于[Bookwalker.com.tw]
请前往线上阅读。
漫画URL类似这样:https://www.bookwalker.com.tw/browserViewer/56994/read
-
对于[Cmoa.jp]
打开漫画,直接复制浏览器上的URL。
将这个URL复制到main.py中的
MANGA_URL。 -
-
编辑完程序后,运行
python main.py来执行。
注意事项
-
SLEEP_TIME默认为2秒,你可以根据自己的网络情况调整,如果下载时出现重复图片,可以将其改为5或更多。如果你觉得太慢,可以尝试改为1甚至0.5。 -
LOADING_WAIT_TIME = 20,这是等待漫画浏览器页面加载的时间,如果你的网络不好,可以将其设置为30或50秒。 -
分辨率,你可以根据需要更改,但请先检查原始图片的分辨率。
RES = (784, 1200)如果原始图片有更高的分辨率,你可以这样更改(分辨率仅作示例)。
RES = (1568, 2400)对于[Cmoa.jp]不需要这个,分辨率由[Cmoa.jp]固定。
-
有时我们需要登出并重新登录,这个网站非常严格,采取了很多方法防止滥用。
-
现在你可以通过设置
CUT_IMAGE为(左, 上, 右, 下)来裁剪图片。例如,如果你想从图片底部裁剪3像素,可以这样设置:
CUT_IMAGE = (0, 0, 0, 3)这个功能使用
Pillow,如果你想使用它,需要通过以下命令安装:pip install Pillow默认为
None,表示不裁剪图片。 -
你现在可以通过更改
file_name_prefix和number_of_digits来改变文件名前缀和数字位数。例如,如果你正在下载《斩服少女》漫画第一卷,你想要文件名像这样:
KLK_V1 │--KLK_V1_001.jpg │--KLK_V1_002.jpg │--KLK_V1_003.jpg那么你可以这样设置参数:
settings = { ..., 'file_name_prefix': 'KLK_V1', # 文件名数字位数,如果你想要文件名像'001.jpg',这里写3。 'number_of_digits': 3 }
开发
-
概念
要下载漫画,通常我们会这样做:
+------------+ +-----------+ +------------+ +-------------------+ +--------------+
| | | | | | | | 结束 | |
| 登录 +-----+ 加载页面 +----->+ 保存图片 +----->+ 移至下一页 +----->+ 完成 |
| | | | | | | | | |
+------------+ +-----------+ +-----+------+ +---------+---------+ +--------------+
^ |
| |
| 还有更多页面 |
+-----------------------+
因此,我们可以创建一个框架来重复使用代码。对于新网站,通常我们只需要编写一些方法。
- 文件结构
|--main.py
│--downloader.py
│--README.MD
└─website_actions
│--abstract_website_actions.py
│--bookwalker_jp_actions.py
│--bookwalker_tw_actions.py
│--cmoa_jp_actions.py
│--__init__.py
- 抽象
WebsiteActions类介绍
对于每个网站,该类应具有以下方法/属性,这里我们以bookwalker.jp为例:
class BookwalkerJP(WebsiteActions):
'''
bookwalker.jp
'''
# login_url是我们首先加载并放置cookie的页面。
login_url = 'https://member.bookwalker.jp/app/03/login'
@staticmethod
def check_url(manga_url):
'''
此方法返回一个布尔值,检查给定的漫画URL是否属于此类。
'''
return manga_url.find('bookwalker.jp') != -1
def get_sum_page_count(self, driver):
'''
此方法返回一个整数,获取总页数。
'''
return int(str(driver.find_element_by_id('pageSliderCounter').text).split('/')[1])
def move_to_page(self, driver, page):
'''
此方法不返回任何内容,移动到给定的页码。
'''
driver.execute_script(
'NFBR.a6G.Initializer.B0U.menu.a6l.moveToPage(%d)' % page)
def wait_loading(self, driver):
'''
此方法不返回任何内容,等待漫画加载。
'''
WebDriverWait(driver, 30).until_not(lambda x: self.check_is_loading(
x.find_elements_by_css_selector(".loading")))
def get_imgdata(self, driver, now_page):
'''
此方法返回可以写入文件或转换为BytesIO的字符串/内容,获取图像数据。
'''
canvas = driver.find_element_by_css_selector(".currentScreen canvas")
img_base64 = driver.execute_script(
"return arguments[0].toDataURL('image/jpeg').substring(22);", canvas)
return base64.b64decode(img_base64)
def get_now_page(self, driver):
'''
此方法返回一个整数,当前页面上的页码
'''
return int(str(driver.find_element_by_id('pageSliderCounter').text).split('/')[0])
我们还有一个before_download方法,这个方法在开始下载之前运行,因为某些网站需要在开始下载之前关闭一些弹出组件。
def before_download(self, driver):
'''
此方法不返回任何内容,在下载之前运行。
'''
driver.execute_script('parent.closeTips()')











