
 Github
Github Huggingface
Huggingface 论文
论文LVM:顺序建模实现大规模视觉模型的可扩展学习
LVM是一种视觉预训练模型,它将各种视觉数据转换为视觉句子,并自回归地执行下一个标记预测。它兼容GPU和TPU。
LVM建立在OpenLLaMA(一个自回归模型)和OpenMuse(一个将图像转换为视觉标记的VQGAN)之上。
这项工作是与HuggingFace合作完成的。感谢Victor Sanh在这个项目中的支持。
摘要:
我们提出了一种新颖的顺序建模方法,使得在不使用任何语言数据的情况下学习大规模视觉模型(LVM)成为可能。 为此,我们定义了一种通用格式"视觉句子",可以在不需要像素之外的任何元知识的情况下,将原始图像和视频以及语义分割和深度重建等带注释的数据源表示出来。一旦这种多样化的视觉数据(包含4200亿个标记)被表示为序列,模型就可以通过最小化下一个标记预测的交叉熵损失来进行训练。通过在不同规模的模型架构和数据多样性上进行训练,我们提供了经验证据,证明我们的模型可以有效扩展。通过在测试时设计合适的视觉提示,可以解决许多不同的视觉任务。
视觉句子
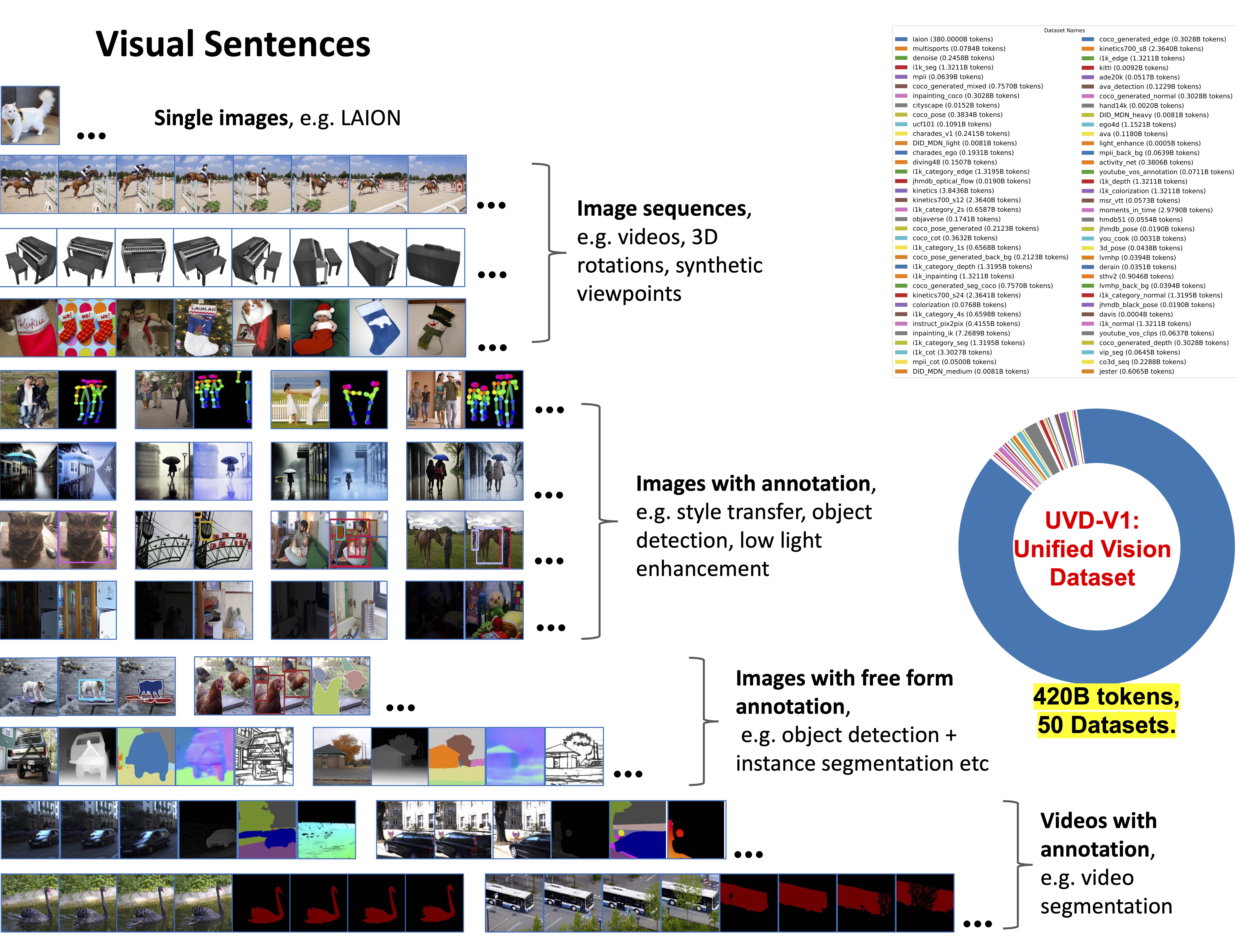
与原始论文版本的主要区别
- 我们目前发布的是7B模型(之前是3B)。其他模型规模的变体将在稍后提供。
- 对LAION数据集进行了深度过滤(包括质量过滤、去重和已知CSAM内容移除),将数据集规模从15亿张图像减少到12亿张。
- 改进了分词器以获得更好的性能。
许可证
LVM采用Apache 2.0许可证。
安装
git clone https://github.com/ytongbai/LVM
cd LVM
export PYTHONPATH="${PWD}:$PYTHONPATH"
环境设置
conda env create -f scripts/gpu_environment.yml
conda activate LVM
数据集准备
请参阅DATASET.md获取准备数据集的详细说明。
准备好数据集后,你将得到一个预分词文件dataset.jsonl。
训练脚本
我们提供了一个7B模型的示例训练脚本,关于分布式训练设置的更多细节,请参考EasyLM。
对于其他模型大小,我们在'./EasyLM/models/llama/llama_model.py'中提供了从100M、300M、600M、1B、3B、7B、13B、20B到30B的模型定义。
python -u -m EasyLM.models.llama.llama_train \
--jax_distributed.initialize_jax_distributed=True \
--jax_distributed.coordinator_address='$MASTER_ADDR:$MASTER_PORT' \
--jax_distributed.local_device_ids='0,1,2,3,4,5,6,7' \
--mesh_dim='$SLURM_NNODES,-1,1' \
--dtype='bf16' \
--total_steps=400000 \ # 根据数据数量进行调整
--log_freq=10 \
--save_model_freq=1000 \
--save_milestone_freq=2000 \
--load_llama_config='vqlm_7b' \
--optimizer.type='adamw' \
--optimizer.adamw_optimizer.weight_decay=0.1 \
--optimizer.adamw_optimizer.lr=1.5e-4 \
--optimizer.adamw_optimizer.end_lr=3e-5 \
--optimizer.adamw_optimizer.lr_warmup_steps=8000 \
--optimizer.adamw_optimizer.lr_decay_steps=288000 \
--optimizer.accumulate_gradient_steps=4 \
--train_dataset.type='json' \
--train_dataset.text_processor.fields=',{tokens},' \
--train_dataset.json_dataset.path='/path/to/dataset.jsonl' \
--train_dataset.json_dataset.seq_length=4096 \
--train_dataset.json_dataset.batch_size=32 \
--train_dataset.json_dataset.tokenizer_processes=16 \
--checkpointer.save_optimizer_state=True \
--logger.online=True \
--logger.output_dir='/path/to/checkpoint/$RUN_NAME' \
--logger.wandb_dir='/path/to/wandb' \
--logger.notes='' \
--logger.experiment_id=$EXPERIMENT_ID
转换为Huggingface检查点
python -m EasyLM.models.llama.convert_easylm_to_hf --load_checkpoint='trainstate_params::/path/to/checkpoint/streaming_train_state' --model_size='vqlm_7b' --output_dir='/path/to/output/checkpoint/'
演示和推理
下载少样本示例数据集。
主要有两种视觉提示方式:顺序提示和类比提示。
类比提示:
用少样本示例描述任务,这些示例是(x, y)输入对,其中x是输入图像,y是"注释"图像。最后添加一个查询图像。我们在此链接提供了更多少样本示例,你可以简单地更改最后的查询图像进行测试。
顺序提示:
输入一系列连续帧,让模型生成下一帧。
查看我们在HuggingFace Spaces上的演示和额外推理代码:LVM演示
评估
查看evaluation/EVAL.md
模型
微调
LVM是一个预训练模型,没有指令调整或其他类型的后训练。如果你想要一个特定任务,我们建议将数据组织成视觉句子格式,然后使用我们提供的训练脚本,以较小的学习率进行微调。
引用
如果你在研究或应用中发现LVM有用,请使用以下BibTeX引用我们的工作:
@article{bai2023sequential,
title={Sequential modeling enables scalable learning for large vision models},
author={Bai, Yutong and Geng, Xinyang and Mangalam, Karttikeya and Bar, Amir and Yuille, Alan and Darrell, Trevor and Malik, Jitendra and Efros, Alexei A},
journal={arXiv preprint arXiv:2312.00785},
year={2023}
}











