[中文版本]
我们目前收到了大量问题,我们的团队将逐一检查并解决这些问题,请保持关注。
INTERN-2.5:多模态多任务通用大模型


















 InternImage的官方实现:
InternImage的官方实现:
《InternImage: 使用可变形卷积探索大规模视觉基础模型》。
[论文] [中文博客]
亮点
- :thumbsup: 最强大的开源视觉通用骨干网络模型,参数规模高达30亿
- 🏆 在ImageNet上达到
90.1%的Top1准确率,是开源模型中最高的
- 🏆 在COCO基准数据集上的目标检测任务中达到
65.5 mAP,是唯一一个超过65.0 mAP的模型
相关项目
基础模型
自动驾驶
在挑战赛中的应用
新闻
2024年1月22日: 🚀 InternImage支持DCNv4!2023年3月14日: 🚀 "INTERN-2.5"发布!2023年2月28日: 🚀 InternImage被CVPR 2023接收!2022年11月18日: 🚀 InternImage-XL与BEVFormer v2结合,在nuScenes仅相机任务上达到63.4 NDS的最佳性能。2022年11月10日: 🚀 InternImage-H在COCO检测test-dev上达到新纪录65.4 mAP,在ADE20K上达到62.9 mIoU,大幅超越之前的模型。
历史
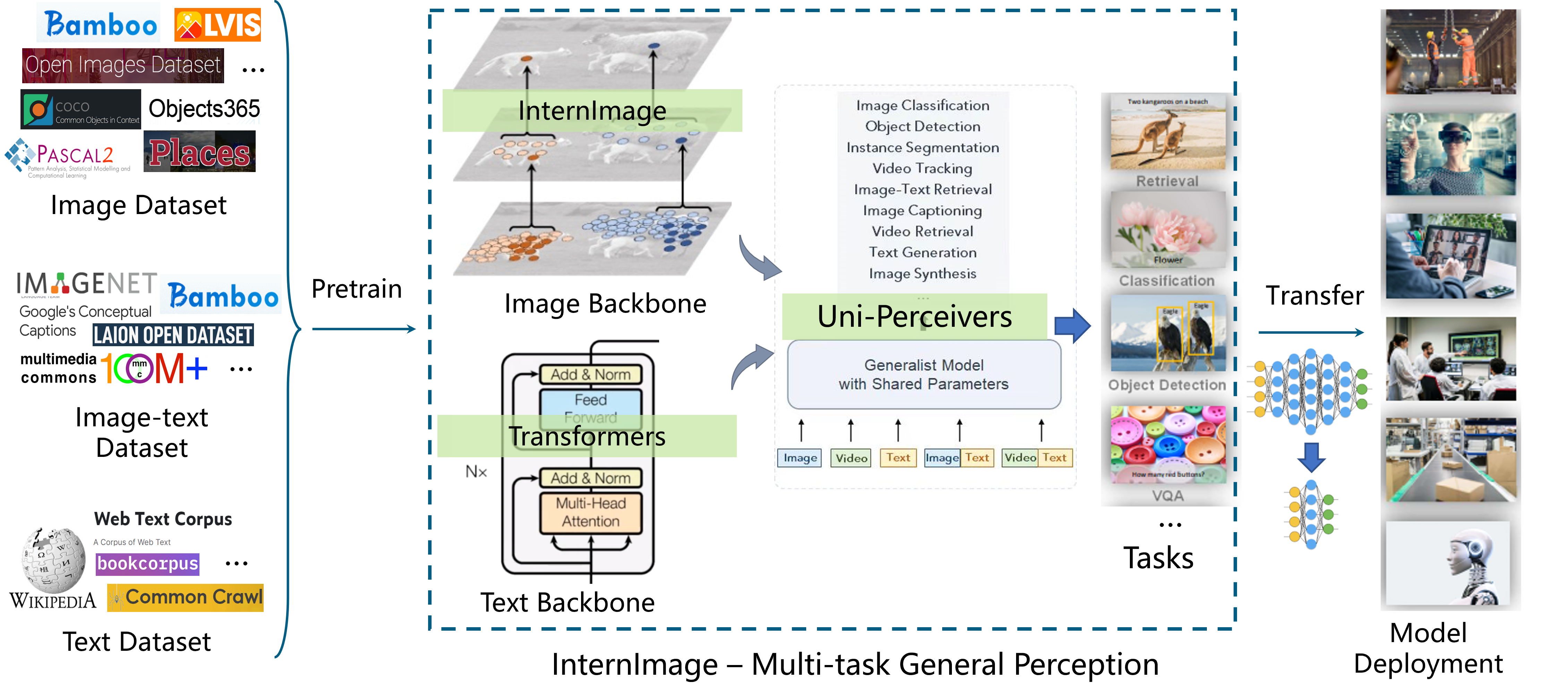
简介
"INTERN-2.5"是由商汤科技和上海人工智能实验室联合发布的强大多模态多任务通用模型。它由大规模视觉基础模型"InternImage"、预训练方法"M3I-Pretraining"、通用解码器"Uni-Perceiver"系列和用于自动驾驶感知的通用编码器"BEVFormer"系列组成。
应用
🌅 图像模态任务
"INTERN-2.5"在ImageNet基准数据集上仅使用公开可用数据就达到了90.1%的Top-1准确率。除了谷歌和微软使用额外数据集训练的两个未公开模型外,"INTERN-2.5"是唯一一个达到90.0%以上Top-1准确率的开源模型,也是世界上规模最大的模型。
"INTERN-2.5"在COCO目标检测基准数据集上以65.5的惊人mAP超越了世界上所有其他模型,是世界上唯一一个超过65 mAP的模型。
"INTERN-2.5"在其他16个重要的视觉基准数据集上也展示了世界最佳性能,涵盖了分类、检测和分割等广泛任务,成为多个领域表现最佳的模型。
性能
| 图像分类 | 场景分类 | 长尾分类 |
|---|
| ImageNet | Places365 | Places 205 | iNaturalist 2018 |
|---|
| 90.1 | 61.2 | 71.7 | 92.3 |
|---|
| 常规目标检测 | 长尾目标检测 | 自动驾驶目标检测 | 密集目标检测 |
|---|
| COCO | VOC 2007 | VOC 2012 | OpenImage | LVIS minival | LVIS val | BDD100K | nuScenes | CrowdHuman |
|---|
| 65.5 | 94.0 | 97.2 | 74.1 | 65.8 | 63.2 | 38.8 | 64.8 | 97.2 |
|---|
| 语义分割 | 街道分割 | RGBD分割 |
|---|
| ADE20K | COCO Stuff-10K | Pascal Context | CityScapes | NYU Depth V2 |
|---|
| 62.9 | 59.6 | 70.3 | 86.1 | 69.7 |
|---|
🌁 📖 图像和文本跨模态任务
图像-文本检索:"INTERN-2.5"能够根据文本内容要求快速定位和检索语义最相关的图像。这种能力可应用于视频和图像集合,并可进一步结合目标检测框,实现多种应用,帮助用户快速便捷地找到所需的图像资源。例如,它可以在相册中返回文本指定的相关图像。
图像转文本:"INTERN-2.5"在图像描述、视觉问答、视觉推理和光学字符识别等多个视觉到文本任务方面具有强大的理解能力。例如,在自动驾驶场景中,它可以增强场景感知和理解能力,协助车辆判断交通信号状态、道路标志等信息,为车辆决策和规划提供有效的感知信息支持。
性能
| 图像描述 | 微调图像-文本检索 | 零样本图像-文本检索 |
|---|
| COCO Caption | COCO Caption | Flickr30k | Flickr30k |
|---|
| 148.2 | 76.4 | 94.8 | 89.1 |
|---|
发布的模型
开源视觉预训练模型
| 名称 | 预训练 | 预训练分辨率 | 参数量 | 下载 |
|---|
| InternImage-L | ImageNet-22K | 384x384 | 223M | ckpt |
| InternImage-XL | ImageNet-22K | 384x384 | 335M | ckpt |
| InternImage-H | 联合 427M | 384x384 | 1.08B | ckpt |
| InternImage-G | - | 384x384 | 3B | ckpt |
ImageNet-1K 图像分类
| 名称 | 预训练 | 分辨率 | top-1准确率 | 参数量 | 浮点运算量 | 下载 |
| :------------: | :----------: | :--------: | :---: | :----: | :---: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| InternImage-T | ImageNet-1K | 224x224 | 83.5 | 30M | 5G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_t_1k_224.pth) \| [配置](classification/configs/without_lr_decay/internimage_t_1k_224.yaml) |
| InternImage-S | ImageNet-1K | 224x224 | 84.2 | 50M | 8G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_s_1k_224.pth) \| [配置](classification/configs/without_lr_decay/internimage_s_1k_224.yaml) |
| InternImage-B | ImageNet-1K | 224x224 | 84.9 | 97M | 16G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_b_1k_224.pth) \| [配置](classification/configs/without_lr_decay/internimage_b_1k_224.yaml) |
| InternImage-L | ImageNet-22K | 384x384 | 87.7 | 223M | 108G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_l_22kto1k_384.pth) \| [配置](classification/configs/without_lr_decay/internimage_l_22kto1k_384.yaml) |
| InternImage-XL | ImageNet-22K | 384x384 | 88.0 | 335M | 163G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_xl_22kto1k_384.pth) \| [配置](classification/configs/without_lr_decay/internimage_xl_22kto1k_384.yaml) |
| InternImage-H | 联合 427M | 640x640 | 89.6 | 1.08B | 1478G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_h_22kto1k_640.pth) \| [配置](classification/configs/without_lr_decay/internimage_h_22kto1k_640.yaml) |
| InternImage-G | - | 512x512 | 90.1 | 3B | 2700G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_g_22kto1k_512.pth) \| [配置](classification/configs/without_lr_decay/internimage_g_22kto1k_512.yaml) |
COCO目标检测和实例分割
| 主干网络 | 方法 | 调度 | 边界框mAP | 掩码mAP | 参数量 | FLOPs | 下载 |
| :------------: | :--------: | :---: | :-----: | :------: | :----: | :---: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| InternImage-T | Mask R-CNN | 1x | 47.2 | 42.5 | 49M | 270G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_t_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_t_fpn_1x_coco.py) |
| InternImage-T | Mask R-CNN | 3x | 49.1 | 43.7 | 49M | 270G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_t_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_t_fpn_3x_coco.py) |
| InternImage-S | Mask R-CNN | 1x | 47.8 | 43.3 | 69M | 340G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_s_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_s_fpn_1x_coco.py) |
| InternImage-S | Mask R-CNN | 3x | 49.7 | 44.5 | 69M | 340G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_s_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_s_fpn_3x_coco.py) |
| InternImage-B | Mask R-CNN | 1x | 48.8 | 44.0 | 115M | 501G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_b_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_b_fpn_1x_coco.py) |
| InternImage-B | Mask R-CNN | 3x | 50.3 | 44.8 | 115M | 501G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_b_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_b_fpn_3x_coco.py) |
| InternImage-L | Cascade | 1x | 54.9 | 47.7 | 277M | 1399G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_l_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_l_fpn_1x_coco.py) |
| InternImage-L | Cascade | 3x | 56.1 | 48.5 | 277M | 1399G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_l_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_l_fpn_3x_coco.py) |
| InternImage-XL | Cascade | 1x | 55.3 | 48.1 | 387M | 1782G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_xl_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_xl_fpn_1x_coco.py) |
| InternImage-XL | Cascade | 3x | 56.2 | 48.8 | 387M | 1782G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_xl_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_xl_fpn_3x_coco.py) |
| 主干网络 | 方法 | 边界框mAP (验证集/测试集) | 参数量 | FLOPs | 下载 |
|---|
| InternImage-H | DINO (TTA) | 65.0 / 65.4 | 2.18B | 待定 | 待定 |
| InternImage-G | DINO (TTA) | 65.3 / 65.5 | 3B | 待定 | 待定 |
ADE20K语义分割
| 骨干网络 | 方法 | 分辨率 | mIoU (单尺度/多尺度) | 参数量 | 计算量 | 下载链接 |
| :------------: | :---------: | :--------: | :----------: | :----: | :---: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| InternImage-T | UperNet | 512x512 | 47.9 / 48.1 | 59M | 944G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_t_512_160k_ade20k.pth) \| [配置](segmentation/configs/ade20k/upernet_internimage_t_512_160k_ade20k.py) |
| InternImage-S | UperNet | 512x512 | 50.1 / 50.9 | 80M | 1017G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_s_512_160k_ade20k.pth) \| [配置](segmentation/configs/ade20k/upernet_internimage_s_512_160k_ade20k.py) |
| InternImage-B | UperNet | 512x512 | 50.8 / 51.3 | 128M | 1185G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_b_512_160k_ade20k.pth) \| [配置](segmentation/configs/ade20k/upernet_internimage_b_512_160k_ade20k.py) |
| InternImage-L | UperNet | 640x640 | 53.9 / 54.1 | 256M | 2526G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_l_640_160k_ade20k.pth) \| [配置](segmentation/configs/ade20k/upernet_internimage_l_640_160k_ade20k.py) |
| InternImage-XL | UperNet | 640x640 | 55.0 / 55.3 | 368M | 3142G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_xl_640_160k_ade20k.pth) \| [配置](segmentation/configs/ade20k/upernet_internimage_xl_640_160k_ade20k.py) |
| InternImage-H | UperNet | 896x896 | 59.9 / 60.3 | 1.12B | 3566G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_h_896_160k_ade20k.pth) \| [配置](segmentation/configs/ade20k/upernet_internimage_h_896_160k_ade20k.py) |
| InternImage-H | Mask2Former | 896x896 | 62.5 / 62.9 | 1.31B | 4635G | [模型](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask2former_internimage_h_896_80k_cocostuff2ade20k.pth) \| [配置](segmentation/configs/ade20k/mask2former_internimage_h_896_80k_cocostuff2ade20k_ss.py) |
FPS主要结果
将分类模型从PyTorch导出到TensorRT
将检测模型从PyTorch导出到TensorRT
将分割模型从PyTorch导出到TensorRT
| 名称 | 分辨率 | 参数量 | 计算量 | 批次大小为1的FPS (TensorRT) |
|---|
| InternImage-T | 224x224 | 30M | 5G | 156 |
| InternImage-S | 224x224 | 50M | 8G | 129 |
| InternImage-B | 224x224 | 97M | 16G | 116 |
| InternImage-L | 384x384 | 223M | 108G | 56 |
| InternImage-XL | 384x384 | 335M | 163G | 47 |
在使用mmdeploy将我们的PyTorch模型转换为TensorRT之前,请确保您已正确构建DCNv3自定义算子。您可以使用以下命令进行构建:
export MMDEPLOY_DIR=/the/root/path/of/MMDeploy
# 准备我们的自定义算子,您可以在InternImage/tensorrt/modulated_deform_conv_v3找到它
cp -r modulated_deform_conv_v3 ${MMDEPLOY_DIR}/csrc/mmdeploy/backend_ops/tensorrt
# 构建自定义算子
cd ${MMDEPLOY_DIR}
mkdir -p build && cd build
cmake -DCMAKE_CXX_COMPILER=g++-7 -DMMDEPLOY_TARGET_BACKENDS=trt -DTENSORRT_DIR=${TENSORRT_DIR} -DCUDNN_DIR=${CUDNN_DIR} ..
make -j$(nproc) && make install
# 构建自定义算子后安装mmdeploy
cd ${MMDEPLOY_DIR}
pip install -e .
有关构建自定义算子的更多详细信息,请参阅此文档。
引用
如果本工作对您的研究有帮助,请考虑引用以下BibTeX条目。
@article{wang2022internimage,
title={InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions},
author={Wang, Wenhai and Dai, Jifeng and Chen, Zhe and Huang, Zhenhang and Li, Zhiqi and Zhu, Xizhou and Hu, Xiaowei and Lu, Tong and Lu, Lewei and Li, Hongsheng and others},
journal={arXiv preprint arXiv:2211.05778},
year={2022}
}
@inproceedings{zhu2022uni,
title={Uni-perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks},
author={Zhu, Xizhou and Zhu, Jinguo and Li, Hao and Wu, Xiaoshi and Li, Hongsheng and Wang, Xiaohua and Dai, Jifeng},
booktitle={CVPR},
pages={16804--16815},
year={2022}
}
@article{zhu2022uni,
标题={Uni-perceiver-moe: 使用条件型专家混合系统学习稀疏通用模型},
作者={朱靖国 and 朱西州 and 王文海 and 王小华 and 李弘盛 and 王晓刚 and 戴继峰},
期刊={arXiv预印本 arXiv:2206.04674},
年份={2022}
}
@article{li2022uni,
标题={Uni-Perceiver v2: 用于大规模视觉和视觉语言任务的通用模型},
作者={李昊 and 朱靖国 and 蒋晓虎 and 朱西州 and 李弘盛 and 袁春 and 王小华 and 乔宇 and 王晓刚 and 王文海 and 其他},
期刊={arXiv预印本 arXiv:2211.09808},
年份={2022}
}
@article{yang2022bevformer,
标题={BEVFormer v2: 通过透视监督将现代图像骨干网络适配到鸟瞰视角识别},
作者={杨晨宇 and 陈云涛 and 田浩 and 陶晨鑫 and 朱西州 and 张兆翔 and 黄高 and 李弘扬 and 乔宇 and 卢乐为 and 其他},
期刊={arXiv预印本 arXiv:2211.10439},
年份={2022}
}
@article{su2022towards,
标题={迈向全面预训练:通过最大化多模态互信息},
作者={苏伟杰 and 朱西州 and 陶晨鑫 and 卢乐为 and 李斌 and 黄高 and 乔宇 and 王晓刚 and 周杰 and 戴继峰},
期刊={arXiv预印本 arXiv:2211.09807},
年份={2022}
}
@inproceedings{li2022bevformer,
标题={BEVFormer: 通过时空变换器从多相机图像学习鸟瞰视角表示},
作者={李志琦 and 王文海 and 李弘扬 and 谢恩泽 and 司马重豪 and 陆通 and 乔宇 and 戴继峰},
会议={ECCV},
页码={1--18},
年份={2022},
}

 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文