
 访问官网
访问官网 Github
Github 文档
文档 论文
论文基于HiLo注意力的快速视觉Transformer👋(NeurIPS 2022 聚焦报告)

这是基于HiLo注意力的快速视觉Transformer的官方PyTorch实现。
作者:Zizheng Pan、Jianfei Cai和Bohan Zhuang。
新闻
-
2023/11/17. 使用mmdet v3.2.0更新了检测脚本。
-
2023/04/20. 使用PyTorch 2.0更新了训练脚本。支持ONNX和TensorRT模型转换,详见此处。
-
2022/12/15. 发布了使用不同alpha值的ImageNet预训练权重。
-
2022/11/11. LITv2将作为聚焦报告展示!
-
2022/10/13. 更新代码以适配更高版本的timm。兼容PyTorch 1.12.1 + CUDA 11.3 + timm 0.6.11。
-
2022/09/30. 添加了单个注意力层的基准测试结果。HiLo在CPU和GPU上都超级快!
-
2022/09/15. LITv2被NeurIPS 2022接收!🔥🔥🔥
-
2022/06/16. 我们发布了分类/检测/分割的源代码,以及预训练权重。欢迎提出任何问题!
简介
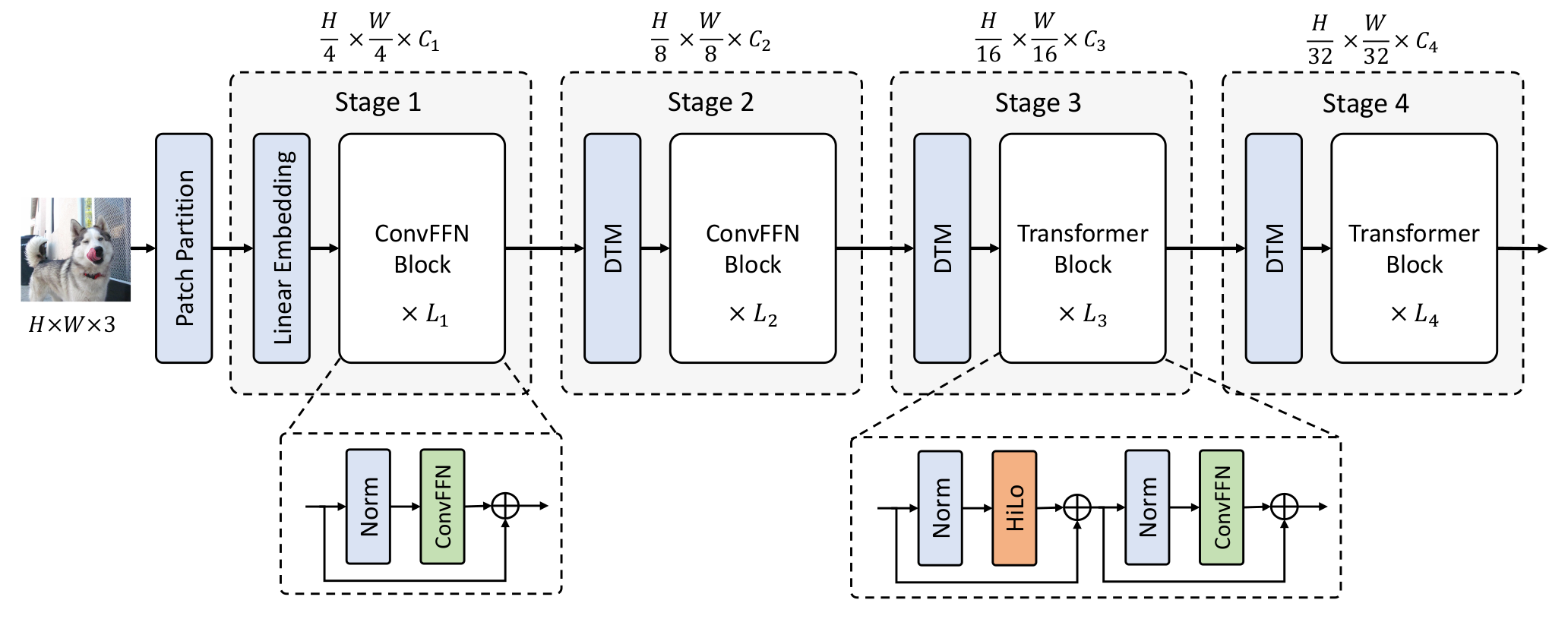
我们介绍了LITv2,这是一个简单而有效的ViT,在不同模型规模下都优于现有最先进的方法,并且速度更快。
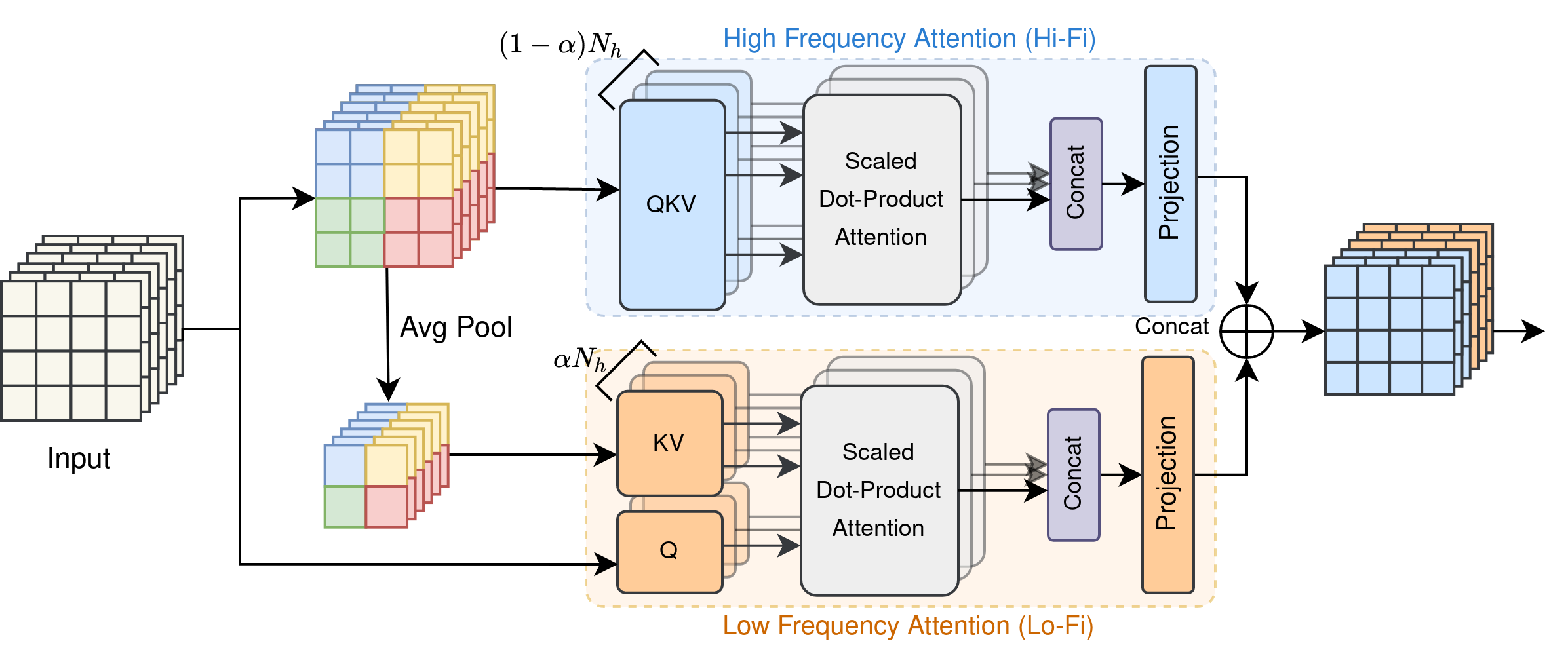
LITv2的核心:HiLo注意力 HiLo的灵感来自于这样一个洞察:图像中的高频捕捉局部细节,低频关注全局结构,而多头自注意力层忽略了不同频率的特征。因此,我们建议通过将注意力头分为两组来分离注意力层中的高/低频模式,其中一组通过每个局部窗口内的自注意力编码高频,另一组执行注意力来建模每个窗口平均池化的低频键与输入特征图中每个查询位置之间的全局关系。
简单演示
要快速理解HiLo注意力,你只需安装PyTorch并在此仓库的根目录尝试以下代码。
from hilo import HiLo
import torch
model = HiLo(dim=384, num_heads=12, window_size=2, alpha=0.5)
x = torch.randn(64, 196, 384) # batch_size x num_tokens x hidden_dimension
out = model(x, 14, 14)
print(out.shape)
print(model.flops(14, 14)) # FLOPs数量
输出:
torch.Size([64, 196, 384])
83467776
安装
要求
- Linux,Python ≥ 3.6
- PyTorch >= 1.8.1
- timm >= 0.3.2
- CUDA 11.1
- NVIDIA GPU
Conda环境设置
注意:你可以使用相同的环境来调试LITv1。否则,你可以通过以下脚本创建一个新的Python虚拟环境。
conda create -n lit python=3.7
conda activate lit
# 安装Pytorch和TorchVision
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
pip install timm
pip install ninja
pip install tensorboard
# 安装NVIDIA apex
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
cd ../
rm -rf apex/
# 构建可变形卷积
cd mm_modules/DCN
python setup.py build install
pip install opencv-python==4.4.0.46 termcolor==1.1.0 yacs==0.1.8
开始使用
对于ImageNet图像分类,请参考分类。
对于COCO 2017目标检测,请参考检测。
对于ADE20K语义分割,请参考分割。
结果和模型库
注意: 为了方便,你可以从Google Drive找到所有模型和日志(总共4.8G)。或者,我们也提供了github的下载链接。
ImageNet-1K图像分类
所有模型都在8张V100 GPU上以1024的总批量大小训练300轮。
| 模型 | 分辨率 | 参数量 (百万) | FLOPs (十亿) | 吞吐量 (图像/秒) | 训练内存 (GB) | 测试内存 (GB) | Top-1 准确率 (%) | 下载 |
|---|---|---|---|---|---|---|---|---|
| LITv2-S | 224 | 28 | 3.7 | 1,471 | 5.1 | 1.2 | 82.0 | 模型 和 日志 |
| LITv2-M | 224 | 49 | 7.5 | 812 | 8.8 | 1.4 | 83.3 | 模型 和 日志 |
| LITv2-B | 224 | 87 | 13.2 | 602 | 12.2 | 2.1 | 83.6 | 模型 和 日志 |
| LITv2-B | 384 | 87 | 39.7 | 198 | 35.8 | 4.6 | 84.7 | 模型 |
默认情况下,吞吐量和内存占用是在一块RTX 3090上基于批量大小为64进行测试的。内存是通过
torch.cuda.max_memory_allocated()测量峰值内存使用量。吞吐量是30次运行的平均值。
不同Alpha值的预训练LITv2-S
| Alpha值 | 参数量 (百万) | 低保真头数 | 高保真头数 | FLOPs (十亿) | ImageNet Top1准确率 (%) | 下载 |
|---|---|---|---|---|---|---|
| 0.0 | 28 | 0 | 12 | 3.97 | 81.16 | GitHub |
| 0.2 | 28 | 2 | 10 | 3.88 | 81.89 | GitHub |
| 0.4 | 28 | 4 | 8 | 3.82 | 81.81 | GitHub |
| 0.5 | 28 | 6 | 6 | 3.77 | 81.88 | GitHub |
| 0.7 | 28 | 8 | 4 | 3.74 | 81.94 | GitHub |
| 0.9 | 28 | 10 | 2 | 3.73 | 82.03 | GitHub |
| 1.0 | 28 | 12 | 0 | 3.70 | 81.89 | GitHub |
图4中基于LITv2-S的α效果实验的预训练权重。
COCO 2017目标检测
所有模型都在8块V100 GPU上使用1x调度(12个epoch)和总批量大小为16进行训练。
RetinaNet
| 主干网络 | 窗口大小 | 参数量 (百万) | FLOPs (十亿) | FPS | 边界框AP | 配置文件 | 下载链接 |
|---|---|---|---|---|---|---|---|
| LITv2-S | 2 | 38 | 242 | 18.7 | 44.0 | 配置 | 模型 和 日志 |
| LITv2-S | 4 | 38 | 230 | 20.4 | 43.7 | 配置 | 模型 和 日志 |
| LITv2-M | 2 | 59 | 348 | 12.2 | 46.0 | 配置 | 模型 和 日志 |
| LITv2-M | 4 | 59 | 312 | 14.8 | 45.8 | 配置 | 模型 和 日志 |
| LITv2-B | 2 | 97 | 481 | 9.5 | 46.7 | 配置 | 模型 和 日志 |
| LITv2-B | 4 | 97 | 430 | 11.8 | 46.3 | 配置 | 模型 和 日志 |
Mask R-CNN
| 骨干网络 | 窗口大小 | 参数量 (百万) | 浮点运算量 (G) | FPS | 边界框 AP | 掩码 AP | 配置文件 | 下载链接 |
|---|---|---|---|---|---|---|---|---|
| LITv2-S | 2 | 47 | 261 | 18.7 | 44.9 | 40.8 | 配置 | 模型 和 日志 |
| LITv2-S | 4 | 47 | 249 | 21.9 | 44.7 | 40.7 | 配置 | 模型 和 日志 |
| LITv2-M | 2 | 68 | 367 | 12.6 | 46.8 | 42.3 | 配置 | 模型 和 日志 |
| LITv2-M | 4 | 68 | 315 | 16.0 | 46.5 | 42.0 | 配置 | 模型 和 日志 |
| LITv2-B | 2 | 106 | 500 | 9.3 | 47.3 | 42.6 | 配置 | 模型 和 日志 |
| LITv2-B | 4 | 106 | 449 | 11.5 | 46.8 | 42.3 | 配置 | 模型 和 日志 |
ADE20K数据集上的语义分割
所有模型都在8个V100 GPU上训练了80K次迭代,总批量大小为16。
| 主干网络 | 参数量 (M) | FLOPs (G) | FPS | mIoU | 配置文件 | 下载 |
|---|---|---|---|---|---|---|
| LITv2-S | 31 | 41 | 42.6 | 44.3 | 配置 | 模型 & 日志 |
| LITv2-M | 52 | 63 | 28.5 | 45.7 | 配置 | 模型 & 日志 |
| LITv2-B | 90 | 93 | 27.5 | 47.2 | 配置 | 模型 & 日志 |
在更多 GPU 上的吞吐量基准测试
| 模型 | 参数量 (M) | FLOPs (G) | A100 | V100 | RTX 6000 | RTX 3090 | Top-1 (%) |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 26 | 4.1 | 1,424 | 1,123 | 877 | 1,279 | 80.4 |
| PVT-S | 25 | 3.8 | 1,460 | 798 | 548 | 1,007 | 79.8 |
| Twins-PCPVT-S | 24 | 3.8 | 1,455 | 792 | 529 | 998 | 81.2 |
| Swin-Ti | 28 | 4.5 | 1,564 | 1,039 | 710 | 961 | 81.3 |
| TNT-S | 24 | 5.2 | 802 | 431 | 298 | 534 | 81.3 |
| CvT-13 | 20 | 4.5 | 1,595 | 716 | 379 | 947 | 81.6 |
| CoAtNet-0 | 25 | 4.2 | 1,538 | 962 | 643 | 1,151 | 81.6 |
| CaiT-XS24 | 27 | 5.4 | 991 | 484 | 299 | 623 | 81.8 |
| PVTv2-B2 | 25 | 4.0 | 1,175 | 670 | 451 | 854 | 82.0 |
| XCiT-S12 | 26 | 4.8 | 1,727 | 761 | 504 | 1,068 | 82.0 |
| ConvNext-Ti | 28 | 4.5 | 1,654 | 762 | 571 | 1,079 | 82.1 |
| Focal-Tiny | 29 | 4.9 | 471 | 372 | 261 | 384 | 82.2 |
| LITv2-S | 28 | 3.7 | 1,874 | 1,304 | 928 | 1,471 | 82.0 |
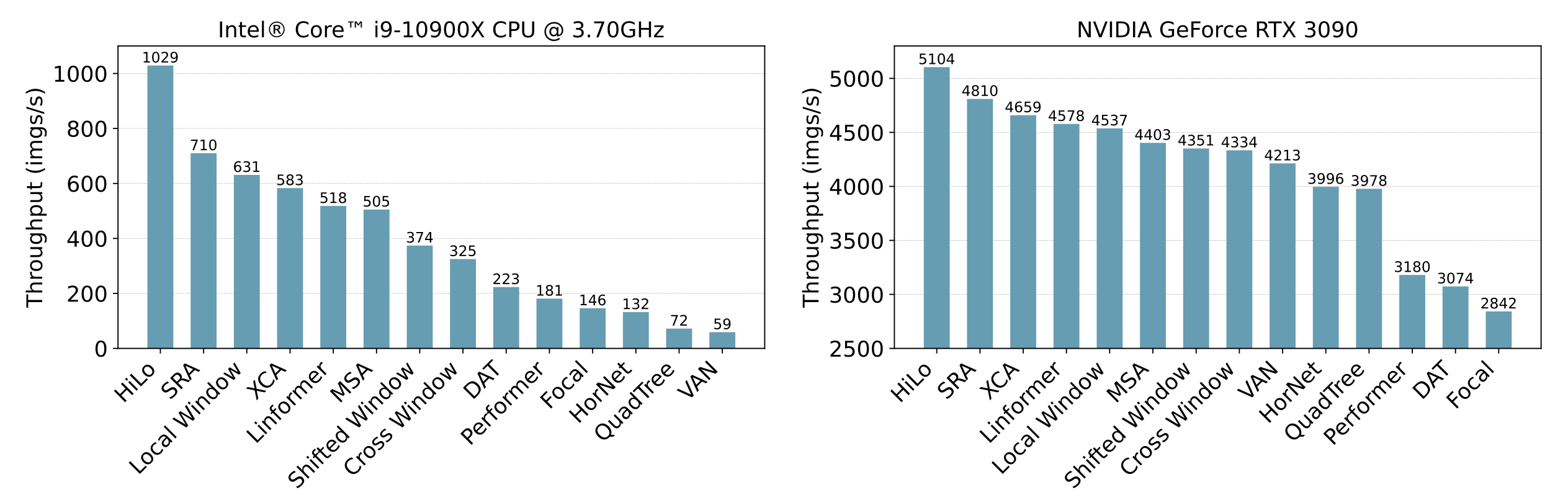
单个注意力层基准测试
以下可视化结果可参考 vit-attention-benchmark。
引用
如果您在研究中使用了 LITv2,请考虑使用以下 BibTeX 条目并给我们一个星标 🌟。
@inproceedings{pan2022hilo,
title={Fast Vision Transformers with HiLo Attention},
author={Pan, Zizheng and Cai, Jianfei and Zhuang, Bohan},
booktitle={NeurIPS},
year={2022}
}
如果您觉得代码有用,也请考虑以下 BibTeX 条目
@inproceedings{pan2022litv1,
title={Less is More: Pay Less Attention in Vision Transformers},
author={Pan, Zizheng and Zhuang, Bohan and He, Haoyu and Liu, Jing and Cai, Jianfei},
booktitle={AAAI},
year={2022}
}
许可证
本仓库在 LICENSE 文件中所列的 Apache 2.0 许可证下发布。











