
 访问官网
访问官网 Github
Github 论文
论文FastViT: 使用结构重参数化的快速混合视觉Transformer
这是以下论文的官方代码库:
FastViT: 使用结构重参数化的快速混合视觉Transformer Pavan Kumar Anasosalu Vasu, James Gabriel, Jeff Zhu, Oncel Tuzel, Anurag Ranjan. ICCV 2023
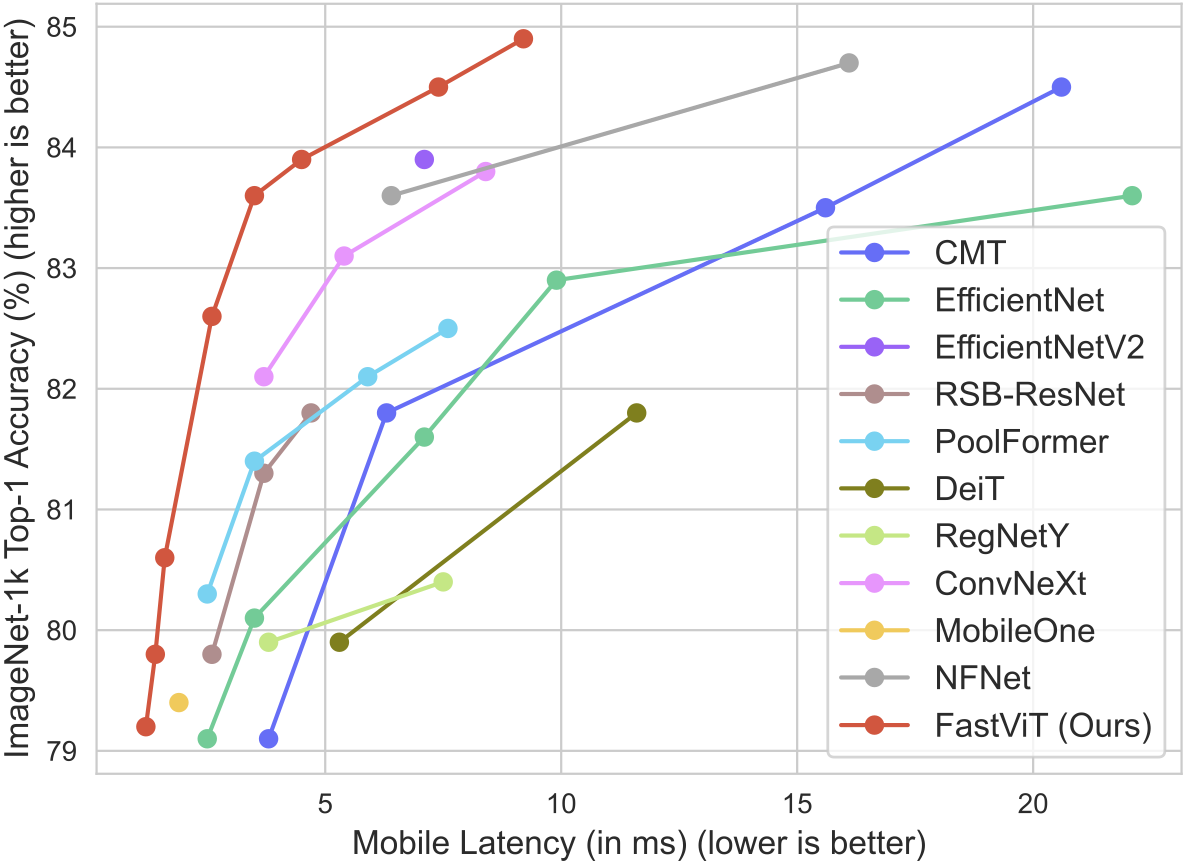
所有模型都在ImageNet-1K上训练,并使用ModelBench应用在iPhone 12 Pro上进行基准测试。
环境设置
conda create -n fastvit python=3.9
conda activate fastvit
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
使用方法
要使用我们的模型,请参考以下代码片段:
import torch
import models
from timm.models import create_model
from models.modules.mobileone import reparameterize_model
# 从头开始训练/微调
model = create_model("fastvit_t8")
# ... 训练 ...
# 加载未融合的预训练检查点用于微调
# 或用于下游任务训练,如检测/分割
checkpoint = torch.load('/path/to/unfused_checkpoint.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
# ... 训练 ...
# 用于推理
model.eval()
model_inf = reparameterize_model(model)
# 在测试时使用model_inf
FastViT模型库
图像分类
在ImageNet-1K上训练的模型
| 模型 | Top-1准确率 | 延迟 | PyTorch检查点 (url) | CoreML模型 |
|---|---|---|---|---|
| FastViT-T8 | 76.2 | 0.8 | T8(未融合) | fastvit_t8.mlpackage.zip |
| FastViT-T12 | 79.3 | 1.2 | T12(未融合) | fastvit_t12.mlpackage.zip |
| FastViT-S12 | 79.9 | 1.4 | S12(未融合) | fastvit_s12.mlpackage.zip |
| FastViT-SA12 | 80.9 | 1.6 | SA12(未融合) | fastvit_sa12.mlpackage.zip |
| FastViT-SA24 | 82.7 | 2.6 | SA24(未融合) | fastvit_sa24.mlpackage.zip |
| FastViT-SA36 | 83.6 | 3.5 | SA36(未融合) | fastvit_sa36.mlpackage.zip |
| FastViT-MA36 | 83.9 | 4.6 | MA36(未融合) | fastvit_ma36.mlpackage.zip |
使用知识蒸馏在ImageNet-1K上训练的模型。
| 模型 | Top-1 准确率 | 延迟 | Pytorch 检查点 (url) | CoreML 模型 |
|---|---|---|---|---|
| FastViT-T8 | 77.2 | 0.8 | T8(未融合) | fastvit_t8.mlpackage.zip |
| FastViT-T12 | 80.3 | 1.2 | T12(未融合) | fastvit_t12.mlpackage.zip |
| FastViT-S12 | 81.1 | 1.4 | S12(未融合) | fastvit_s12.mlpackage.zip |
| FastViT-SA12 | 81.9 | 1.6 | SA12(未融合) | fastvit_sa12.mlpackage.zip |
| FastViT-SA24 | 83.4 | 2.6 | SA24(未融合) | fastvit_sa24.mlpackage.zip |
| FastViT-SA36 | 84.2 | 3.5 | SA36(未融合) | fastvit_sa36.mlpackage.zip |
| FastViT-MA36 | 84.6 | 4.6 | MA36(未融合) | fastvit_ma36.mlpackage.zip |
延迟基准测试
所有模型的延迟都是在iPhone 12 Pro上使用ModelBench应用测量的。 如需更多详细信息,请联系James Gabriel和Jeff Zhu。 所有报告的数字都四舍五入到最接近的小数点。
训练
图像分类
数据集准备
下载ImageNet-1K数据集,并按以下结构组织数据:
/path/to/imagenet-1k/
train/
class1/
img1.jpeg
class2/
img2.jpeg
validation/
class1/
img3.jpeg
class2/
img4.jpeg
要训练FastViT模型的变体,请按照以下相应的命令操作:
FastViT-T8
# 无蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_t8 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256
# 有蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_t8 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256
--distillation-type "hard"
FastViT-T12
# 无蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_t12 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256
# 使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_t12 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256
--distillation-type "hard"
FastViT-S12
# 不使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_s12 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256
# 使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_s12 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256
--distillation-type "hard"
FastViT-SA12
# 不使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_sa12 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.1
# 使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_sa12 -b 128 --lr 1e-3 \
--native-amp --output /path/to/save/results \
--input-size 3 256 256
--distillation-type "hard"
FastViT-SA24
# 不使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_sa24 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.1
# 使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_sa24 -b 128 --lr 1e-3 \
--native-amp --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.05 \
--distillation-type "hard"
FastViT-SA36
# 不使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_sa36 -b 128 --lr 1e-3 \
--native-amp --mixup 0.2 --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.2
# 使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_sa36 -b 128 --lr 1e-3 \
--native-amp --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.1 \
--distillation-type "hard"
FastViT-MA36
# 不使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_t8 -b 128 --lr 1e-3 \
--native-amp --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.35
# 使用蒸馏
python -m torch.distributed.launch --nproc_per_node=8 train.py \
/path/to/ImageNet/dataset --model fastvit_t8 -b 128 --lr 1e-3 \
--native-amp --output /path/to/save/results \
--input-size 3 256 256 --drop-path 0.2 \
--distillation-type "hard"
评估
要在ImageNet上运行评估,请按照以下示例命令操作:
FastViT-T8
# 评估未融合的检查点
python validate.py /path/to/ImageNet/dataset --model fastvit_t8 \
--checkpoint /path/to/pretrained_checkpoints/fastvit_t8.pth.tar
# 评估融合的检查点
python validate.py /path/to/ImageNet/dataset --model fastvit_t8 \
--checkpoint /path/to/pretrained_checkpoints/fastvit_t8_reparam.pth.tar \
--use-inference-mode
模型导出
要从PyTorch检查点导出CoreML包文件,请按照以下示例命令操作:
FastViT-T8
python export_model.py --variant fastvit_t8 --output-dir /path/to/save/exported_model \
--checkpoint /path/to/pretrained_checkpoints/fastvit_t8_reparam.pth.tar
引用
@inproceedings{vasufastvit2023,
author = {Pavan Kumar Anasosalu Vasu and James Gabriel and Jeff Zhu and Oncel Tuzel and Anurag Ranjan},
title = {FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023}
}
致谢
我们的代码库是基于多个开源贡献构建的,详情请参阅ACKNOWLEDGEMENTS。












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}