
 Github
Github Huggingface
Huggingface 论文
论文MambaOut: 我们真的需要用Mamba来处理视觉任务吗?


纪念科比·布莱恩特
"我还能说什么呢,曼巴精神永存。" — 科比·布莱恩特,NBA告别演讲,2016年

图片来源:https://www.ebay.ca/itm/264973452480
这是我们论文"MambaOut: 我们真的需要用Mamba来处理视觉任务吗?"中提出的MambaOut的PyTorch实现。
更新
-
2024年5月20日:根据Issue #5的建议,我们发布了具有24个门控CNN块的MambaOut-Kobe模型版本,在ImageNet上达到了80.0%的准确率。MambaOut-Kobe以仅41%的参数量和33%的FLOPs超越了ViT-S 0.2%的准确率。详见模型。
-
2024年5月18日:添加了一个教程,讲解如何计算Transformer的FLOPs(论文中的公式6)。
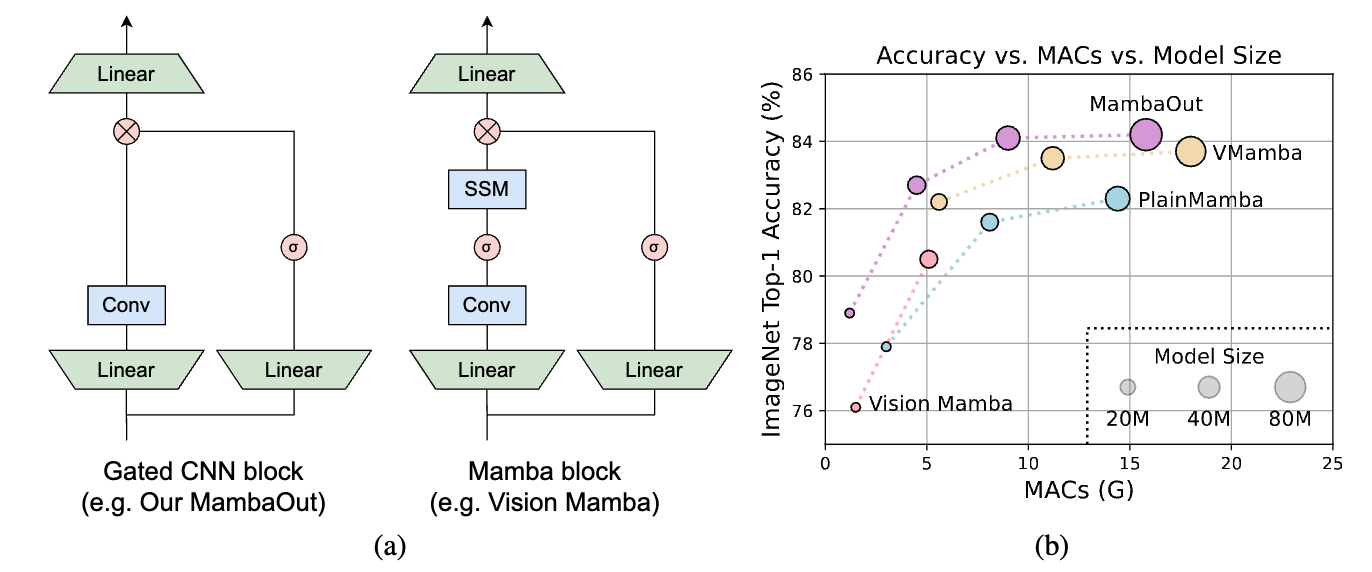 图1:(a) 门控CNN和Mamba块的架构(省略了归一化和短路连接)。Mamba块通过增加一个额外的状态空间模型(SSM)来扩展门控CNN。正如第3节将从概念上讨论的那样,SSM对于ImageNet上的图像分类并不是必需的。为了实证验证这一说法,我们堆叠门控CNN块来构建一系列名为MambaOut的模型。(b) 在ImageNet图像分类任务上,MambaOut优于视觉Mamba模型,如Vision Mamba、VMamba和PlainMamba。
图1:(a) 门控CNN和Mamba块的架构(省略了归一化和短路连接)。Mamba块通过增加一个额外的状态空间模型(SSM)来扩展门控CNN。正如第3节将从概念上讨论的那样,SSM对于ImageNet上的图像分类并不是必需的。为了实证验证这一说法,我们堆叠门控CNN块来构建一系列名为MambaOut的模型。(b) 在ImageNet图像分类任务上,MambaOut优于视觉Mamba模型,如Vision Mamba、VMamba和PlainMamba。
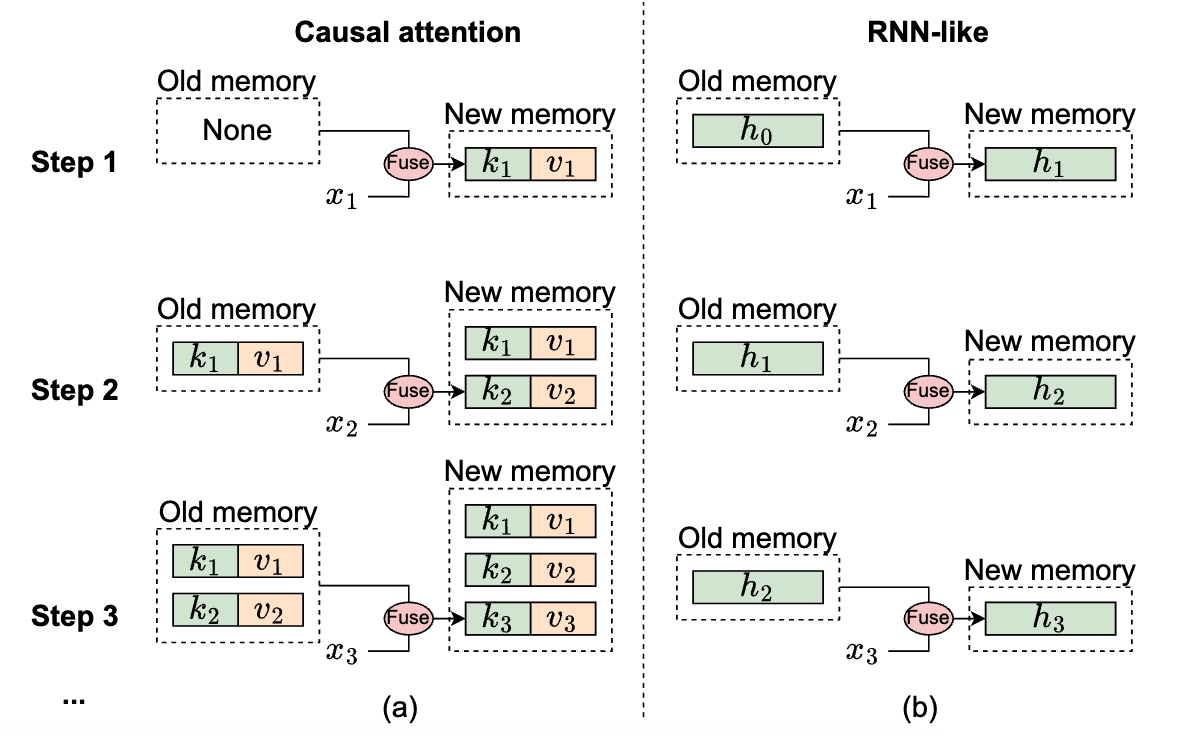 图2:从记忆角度说明因果注意力和RNN类模型的机制,其中$x_i$表示第$i$步的输入标记。(a) 因果注意力将所有先前标记的键$k$和值$v$存储为记忆。通过不断添加当前标记的键和值来更新记忆,因此记忆是无损的,但缺点是整合旧记忆和当前标记的计算复杂度随着序列长度的增加而增加。因此,注意力可以有效地处理短序列,但可能在处理较长序列时遇到困难。(b) 相比之下,RNN类模型将先前的标记压缩为固定大小的隐藏状态$h$,作为记忆。这种固定大小意味着RNN记忆本质上是有损的,无法直接与注意力模型的无损记忆容量竞争。尽管如此,RNN类模型在处理长序列时可以显示出明显的优势,因为合并旧记忆与当前输入的复杂度保持恒定,不受序列长度的影响。
图2:从记忆角度说明因果注意力和RNN类模型的机制,其中$x_i$表示第$i$步的输入标记。(a) 因果注意力将所有先前标记的键$k$和值$v$存储为记忆。通过不断添加当前标记的键和值来更新记忆,因此记忆是无损的,但缺点是整合旧记忆和当前标记的计算复杂度随着序列长度的增加而增加。因此,注意力可以有效地处理短序列,但可能在处理较长序列时遇到困难。(b) 相比之下,RNN类模型将先前的标记压缩为固定大小的隐藏状态$h$,作为记忆。这种固定大小意味着RNN记忆本质上是有损的,无法直接与注意力模型的无损记忆容量竞争。尽管如此,RNN类模型在处理长序列时可以显示出明显的优势,因为合并旧记忆与当前输入的复杂度保持恒定,不受序列长度的影响。
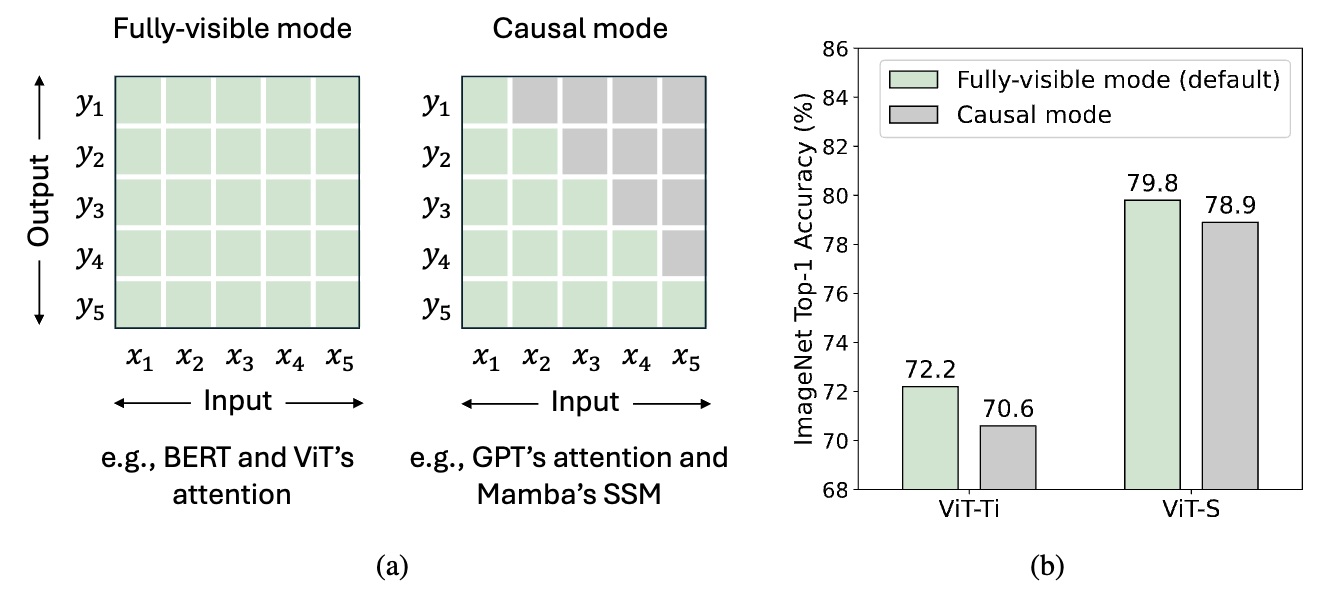 图3:(a) 标记混合的两种模式。对于总共$T$个标记,全可见模式允许标记$t$从所有标记中聚合输入,即$ \left{ x_i \right}{i=1}^{T} $,来计算其输出$y_t$。相比之下,因果模式将标记$t$限制为只能从前面和当前的标记$ \left{ x_i \right}{i=1}^{t} $中聚合输入。默认情况下,注意力在全可见模式下运行,但可以通过因果注意力掩码调整为因果模式。RNN类模型,如Mamba的SSM,由于其循环特性,本质上在因果模式下运行。(b) 我们将ViT的注意力从全可见模式修改为因果模式,并观察到在ImageNet上的性能下降,这表明因果混合对于理解任务是不必要的。
图3:(a) 标记混合的两种模式。对于总共$T$个标记,全可见模式允许标记$t$从所有标记中聚合输入,即$ \left{ x_i \right}{i=1}^{T} $,来计算其输出$y_t$。相比之下,因果模式将标记$t$限制为只能从前面和当前的标记$ \left{ x_i \right}{i=1}^{t} $中聚合输入。默认情况下,注意力在全可见模式下运行,但可以通过因果注意力掩码调整为因果模式。RNN类模型,如Mamba的SSM,由于其循环特性,本质上在因果模式下运行。(b) 我们将ViT的注意力从全可见模式修改为因果模式,并观察到在ImageNet上的性能下降,这表明因果混合对于理解任务是不必要的。
要求
PyTorch和timm 0.6.11(pip install timm==0.6.11)。
数据准备:ImageNet的文件夹结构如下,你可以使用这个脚本提取ImageNet。
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
模型
在ImageNet上训练的MambaOut模型
| 模型 | 分辨率 | 参数量 | MACs | Top1准确率 | 日志 |
|---|---|---|---|---|---|
| mambaout_femto | 224 | 7.3M | 1.2G | 78.9 | 日志 |
| mambaout_kobe* | 224 | 9.1M | 1.5G | 80.0 | 日志 |
| mambaout_tiny | 224 | 26.5M | 4.5G | 82.7 | 日志 |
| mambaout_small | 224 | 48.5M | 9.0G | 84.1 | 日志 |
| mambaout_base | 224 | 84.8M | 15.8G | 84.2 | 日志 |
* 科比纪念版,包含24个门控CNN块。
使用方法
我们还提供了一个Colab笔记本,其中包含使用MambaOut进行推理的步骤:。
Gradio演示
网页演示可在查看。您也可以轻松在本地运行Gradio演示。除了PyTorch和timm==0.6.11外,请通过
pip install gradio安装Gradio,然后运行
python gradio_demo/app.py
验证
要评估模型,请运行:
MODEL=mambaout_tiny
python3 validate.py /path/to/imagenet --model $MODEL -b 128 \
--pretrained
训练
我们默认使用4096的批量大小,这里我们展示如何使用8个GPU进行训练。对于多节点训练,请根据您的情况调整--grad-accum-steps。
DATA_PATH=/path/to/imagenet
CODE_PATH=/path/to/code/MambaOut # 在此修改代码路径
ALL_BATCH_SIZE=4096
NUM_GPU=8
GRAD_ACCUM_STEPS=4 # 根据您的GPU数量和内存大小进行调整
let BATCH_SIZE=ALL_BATCH_SIZE/NUM_GPU/GRAD_ACCUM_STEPS
MODEL=mambaout_tiny
DROP_PATH=0.2
cd $CODE_PATH && sh distributed_train.sh $NUM_GPU $DATA_PATH \
--model $MODEL --opt adamw --lr 4e-3 --warmup-epochs 20 \
-b $BATCH_SIZE --grad-accum-steps $GRAD_ACCUM_STEPS \
--drop-path $DROP_PATH # --native-amp # 也可以使用 --native-amp 或 --amp 来加速训练
其他模型的训练脚本可在scripts中找到。
Transformer FLOPs计算教程
这个教程展示了如何计算Transformer的FLOPs(论文中的公式6)。欢迎反馈,我会持续改进它。
引用
@article{yu2024mambaout,
title={MambaOut: Do We Really Need Mamba for Vision?},
author={Yu, Weihao and Wang, Xinchao},
journal={arXiv preprint arXiv:2405.07992},
year={2024}
}
致谢
Weihao得到了Snap研究奖学金、Google TPU研究云(TRC)和Google云研究信用计划的部分支持。我们感谢Dongze Lian、Qiuhong Shen、Xingyi Yang和Gongfan Fang的宝贵讨论。
我们的实现基于pytorch-image-models、poolformer、ConvNeXt、metaformer和inceptionnext。











