
 访问官网
访问官网 Github
Github 论文
论文AutoKG



论文"大型语言模型用于知识图谱构建和推理:近期能力和未来机遇"的代码和数据
🌄概述
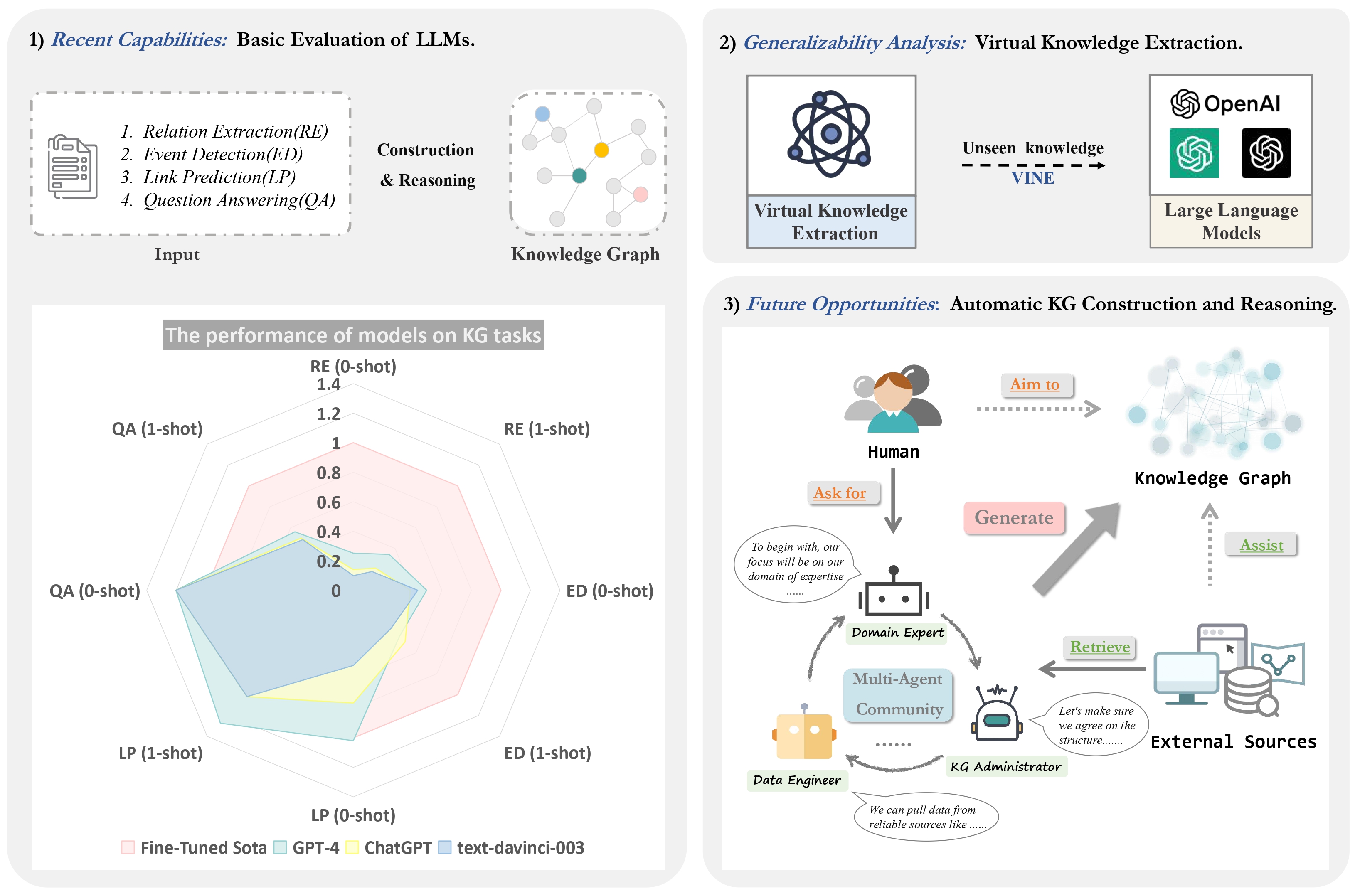
我们工作的概述。主要包含三个部分:1) 基础评估:详细评估了大型模型(text-davinci-003、ChatGPT和GPT-4)在零样本和单样本设置下的表现,以全监督最先进模型的性能数据作为基准;2) 虚拟知识提取:在构建的VINE数据集上检验大型模型的虚拟知识能力;3) 自动知识图谱:提出利用多个代理来促进知识图谱的构建和推理。
🌟 评估
数据预处理
我们在实验中使用的数据集如下:
- 知识图谱构建 您可以从上述地址下载数据集,也可以直接从相应的***"datas"***文件夹中找到本实验中使用的数据,例如DuIE2.0。
- 知识图谱推理
- 问答
- FreebaseQA
- MetaQA
预期的文件结构如下:
AutoKG
|-- KG Construction
| |-- DuIE2.0
| | |-- datas #数据集
| | |-- prompts #零样本/单样本提示
| | |-- duie_processor.py #预处理数据
| | |-- duie_prompts.py #生成提示
| |--MAVEN
| | |-- datas #数据集
| | |-- prompts #零样本/单样本提示
| | |-- maven_processor.py #预处理数据
| | |-- maven_prompts.py #生成提示
| |--RE-TACRED
| | |-- datas #数据集
| | |-- prompts #零样本/单样本提示
| | |-- retacred_processor.py #预处理数据
| | |-- retacred_prompts.py #生成提示
| |--SciERC
| | |-- datas #数据集
| | |-- prompts #零样本/单样本提示
| | |-- scierc_processor.py #预处理数据
| | |-- scierc_prompts.py #生成提示
|-- KG Reasoning (Link Prediction)
| |-- FB15k-237
| | |-- data #样本数据
| | |-- prompts #零样本/单样本提示
| |-- ATOMIC2020
| | |-- data #样本数据
| | |-- prompts #零样本/单样本提示
| | |-- system_eval #ATOMIC2020的评估
如何运行
-
知识图谱构建(以DuIE2.0为例)
cd KG Construction python duie_processor.py python duie_prompts.py然后我们将在*"prompts"*文件夹中得到零样本/单样本提示
-
知识图谱推理
-
问答
🕵️虚拟知识提取
我们构建的VINE数据集可以在**这里**获取。
执行以下代码生成提示:
cd Virtual Knowledge Extraction
python VINE_processor.py
python VINE_prompts.py
🤖AutoKG
我们的AutoKG代码基于CAMEL: 大规模语言模型社会"思维"探索的交流代理和该论文的LangChain实现,您可以通过此链接获取更多详细信息。
- 在
Autokg.py中更改OPENAI_API_KEY - 在
RE_CAMEL.py中更改SERPAPI_API_KEY。(您可以在serpapi获取更多信息)
运行Autokg.py脚本。
cd AutoKG
python Autokg.py
引用
如果您使用了本代码或数据,请引用以下论文:
@article{zhu2023llms,
title={LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities},
author={Zhu, Yuqi and Wang, Xiaohan and Chen, Jing and Qiao, Shuofei and Ou, Yixin and Yao, Yunzhi and Deng, Shumin and Chen, Huajun and Zhang, Ningyu},
journal={arXiv preprint arXiv:2305.13168},
year={2023}
}











