
NeMo-Aligner: 助力构建更安全可靠的大语言模型
随着人工智能技术的飞速发展,大语言模型(LLM)在各行各业的应用日益广泛。然而,如何使这些强大的模型能够更好地与人类价值观和偏好保持一致,成为了一个亟待解决的重要问题。为了应对这一挑战,NVIDIA近期推出了一款名为NeMo-Aligner的开源工具包,旨在帮助研究人员和开发者更高效地进行模型对齐工作。
NeMo-Aligner的核心功能
NeMo-Aligner是一个可扩展的工具包,专门用于高效的模型对齐。它支持多种先进的模型对齐算法,包括:
- SteerLM: 一种基于属性条件的监督微调技术,可作为RLHF的替代方案
- 监督微调(SFT): 传统的模型微调方法
- 奖励模型训练: 用于评估模型输出质量的关键组件
- 基于人类反馈的强化学习(RLHF): 使用PPO算法实现
- 直接偏好优化(DPO): 一种无需参考模型的对齐方法
- 自对弈微调(SPIN): 能将弱语言模型转变为强语言模型的技术
这些算法使用户能够将语言模型调整得更安全、无害和有帮助。NeMo-Aligner的一大亮点是能够在各种规模的模型上执行端到端的对齐过程,并利用多种并行技术来确保对齐过程的高效性和资源利用率。
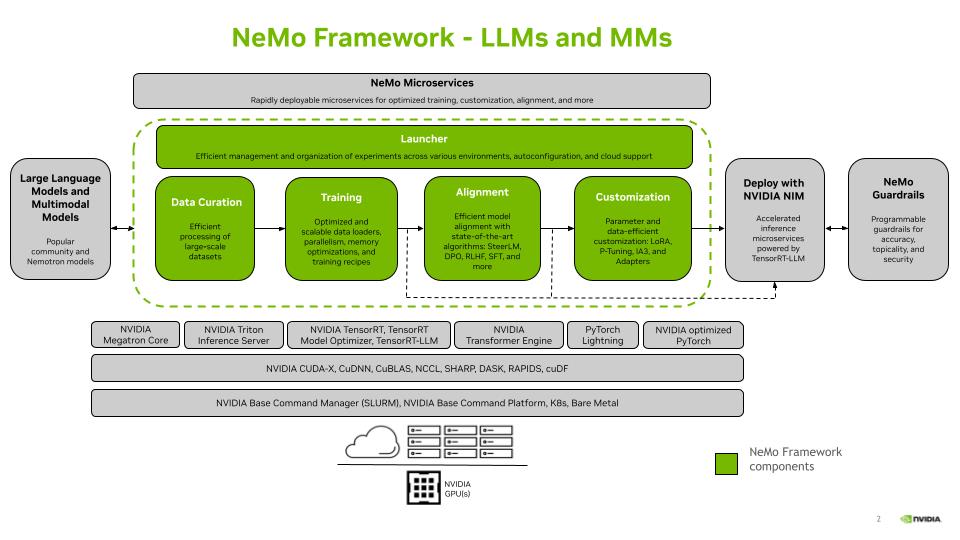
技术特点与优势
-
高度可扩展性: NeMo-Aligner基于NeMo Framework构建,可以利用张量并行、数据并行和流水线并行等技术,实现在数千个GPU上的大规模训练。
-
生态系统兼容性: 该工具包生成的检查点与NeMo生态系统兼容,便于进行推理部署和进一步定制。
-
灵活性: 支持多种参数高效微调(PEFT)技术,如Ptuning、LoRA、Adapters和IA3,在保持接近SFT精度的同时大幅降低计算成本。
-
全面的工具支持: 提供了一系列工具,包括数据处理、模型训练、评估等,简化了整个对齐流程。
-
最新技术支持: 集成了TensorRT-LLM,可以加速RLHF流程中的生成过程。
实际应用案例
NeMo-Aligner已经在多个大型语言模型项目中得到应用,展现了其强大的能力:
- 使用NeMo-Aligner对齐的Llama3-70B-SteerLM-Chat模型
- 基于TRT-LLM使用NeMo-Aligner对齐的Llama3-70B-PPO-Chat模型
- 使用NeMo Aligner对齐的Llama3-70B-DPO-Chat模型
这些模型展示了NeMo-Aligner在不同对齐算法和模型规模上的适用性。
未来发展方向
NVIDIA表示,NeMo-Aligner目前仍处于早期阶段,他们正在持续改进这一工具包,以使开发者能够更容易地选择和应用不同的对齐算法,从而构建安全、有帮助且可靠的模型。未来的工作重点包括:
- 添加拒绝采样(Rejection Sampling)支持
- 持续提高PPO学习阶段的稳定性
- 改进RLHF的性能
开源与社区贡献
NeMo-Aligner采用Apache 2.0许可证开源,NVIDIA欢迎社区贡献。开发者可以通过GitHub仓库(https://github.com/NVIDIA/NeMo-Aligner)参与到项目中来,提交问题、讨论或贡献代码。
总结
NeMo-Aligner的推出,为研究人员和开发者提供了一个强大的工具,以应对大语言模型对齐这一关键挑战。通过支持多种先进的对齐算法,并结合高度的可扩展性和灵活性,NeMo-Aligner有望推动更多安全、有益的AI应用的发展。随着工具包的不断完善和社区的积极参与,我们可以期待看到更多创新性的对齐技术和应用在未来涌现。
对于那些希望深入了解或使用NeMo-Aligner的读者,NVIDIA提供了详细的文档、示例和教程。此外,有关NeMo-Aligner的技术细节,可以参考其论文。
随着AI技术的不断发展,确保大语言模型能够安全、负责任地服务于人类社会变得越来越重要。NeMo-Aligner的出现无疑为这一目标的实现提供了有力的工具支持。我们期待看到更多研究者和开发者利用这一工具,共同推动AI技术向着更加安全、可控的方向发展。


















