
awesome-pretrained-chinese-nlp-models学习资料汇总
awesome-pretrained-chinese-nlp-models是一个收集高质量中文预训练模型的开源项目,旨在为中文自然语言处理研究提供便利。本文将对该项目进行介绍,并整理相关的学习资源,帮助读者快速上手使用。
项目简介
awesome-pretrained-chinese-nlp-models项目由GitHub用户lonePatient创建和维护,主要收集了目前公开的一些高质量中文预训练模型、中文多模态模型、中文大语言模型等内容。项目地址:
https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models
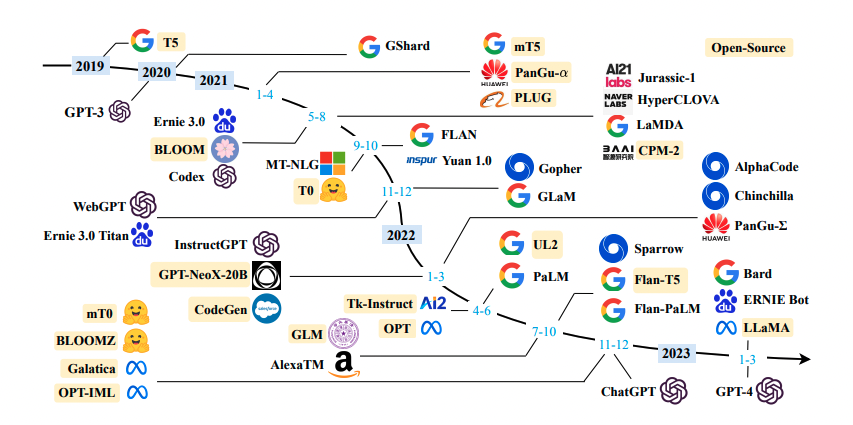
模型列表
该项目收集整理了大量中文预训练模型,主要包括以下几类:
- 通用基础大模型
- 垂直基础大模型
- 通用对话大模型
- 垂直对话大模型
- 多模态对话大模型
- NLU系列模型(BERT、RoBERTa、ALBERT等)
- NLG系列模型(GPT、T5、BART等)
- NLU-NLG系列模型(UniLM、CPM等)
- 多模态模型(WenLan、CogView等)
每个模型都提供了详细的参数信息、下载链接、相关论文等资料。
在线体验
项目还收集了一些可在线体验的中文大模型,如:
- 文心一言: https://yiyan.baidu.com/
- 通义千问: https://qianwen.aliyun.com/
- 星火认知: https://xinghuo.xfyun.cn/
读者可以通过这些链接直接体验最新的中文大语言模型。
开源数据集
项目还整理了一些开源的中文NLP数据集资源:
- CLUE benchmark: https://github.com/CLUEbenchmark/CLUE
- ChineseGLUE: https://github.com/chineseGLUE/chineseGLUE
- OpenCLaP: https://github.com/thunlp/OpenCLaP
这些数据集可以用于训练和评估中文NLP模型。
使用指南
对于想要使用这些预训练模型的读者,可以参考以下步骤:
- 访问项目GitHub页面,选择感兴趣的模型
- 根据提供的下载链接获取模型权重文件
- 使用Hugging Face Transformers等框架加载模型
- 根据具体任务进行微调或直接使用
更详细的使用说明可以参考各模型的说明文档。
总结
awesome-pretrained-chinese-nlp-models项目为中文自然语言处理研究提供了宝贵的资源。无论是初学者还是专业研究人员,都可以从中获益。希望本文的介绍能够帮助读者更好地利用这个优秀的开源项目。
















