
预训练语言模型:NLP领域的重大突破与应用前景
近年来,预训练语言模型(Pre-trained Language Models, PLMs)在自然语言处理(Natural Language Processing, NLP)领域取得了巨大成功,引发了从监督学习到"预训练+微调"范式的重大转变。作为NLP领域的"芝麻街",这些模型不仅改变了我们处理语言任务的方式,还为人工智能的发展带来了新的机遇和挑战。本文将全面介绍预训练语言模型的工作原理、发展历程、代表性模型以及广泛应用,探讨它们为何如此强大以及未来的发展方向。
预训练语言模型的工作原理
预训练语言模型的核心思想是通过在大规模未标注语料上进行自监督学习,让模型学习到语言的通用表示和知识,然后将其迁移到下游特定任务中。这个过程可以类比为创造一个"博览群书"的AI助手,它通过阅读海量文本来理解语言的使用方式和知识体系,然后可以应用这些知识来解决各种具体的语言任务。
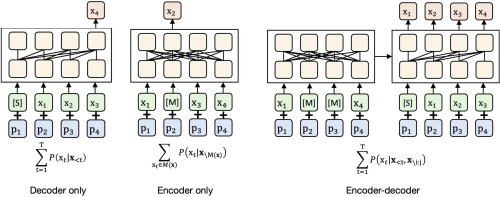
预训练语言模型通常采用Transformer架构,包含多层的自注意力机制和前馈神经网络。在预训练阶段,模型会学习预测被遮蔽的词或下一个词等自监督任务。这使得模型能够捕捉到词与词之间的复杂关系,理解上下文语境,并学习到语言的语法结构和语义知识。
预训练完成后,模型可以通过微调(fine-tuning)或少样本学习(few-shot learning)等方式快速适应下游任务。这种方法大大减少了对标注数据的需求,同时提高了模型在各种NLP任务上的表现。
预训练语言模型的发展历程
预训练语言模型的发展可以追溯到词嵌入技术,如Word2Vec和GloVe。这些方法通过在大规模语料上学习词的分布式表示,为后续的深度学习模型奠定了基础。随着深度学习的发展,以ELMo为代表的上下文相关的词表示方法出现,进一步提升了模型对语言上下文的理解能力。
2018年,BERT(Bidirectional Encoder Representations from Transformers)的出现标志着预训练语言模型进入了新的阶段。BERT采用双向Transformer结构,通过掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)两个预训练任务,学习到了更加强大的语言表示。BERT在多个NLP任务上取得了突破性的成果,引发了学术界和工业界的广泛关注。
在BERT之后,各种改进和变体不断涌现。GPT(Generative Pre-trained Transformer)系列模型采用单向自回归方式进行预训练,在生成任务上表现出色。XLNet引入了排列语言模型,解决了BERT的一些局限性。RoBERTa通过优化训练策略进一步提升了BERT的性能。T5将各种NLP任务统一为文本到文本的生成问题,展示了预训练模型的通用性。
近年来,大规模语言模型如GPT-3、PaLM和PanGu-α等的出现,将预训练语言模型的规模和能力推向了新的高度。这些拥有数百亿甚至上千亿参数的模型展示了惊人的少样本学习能力和通用性,能够完成各种复杂的语言任务。
代表性预训练语言模型
-
BERT: 双向Transformer编码器,通过MLM和NSP任务进行预训练,在多个NLP任务上取得了突破性进展。
-
GPT系列: 单向自回归预训练模型,以GPT-3为代表,展示了大规模语言模型的强大能力。
-
XLNet: 采用排列语言模型,结合了自回归模型和BERT的优点。
-
RoBERTa: BERT的优化版本,通过改进训练策略提升了性能。
-
T5: 将所有NLP任务统一为文本到文本的转换问题,展示了预训练模型的通用性。
-
ALBERT: 通过参数共享和因式分解等技术,大幅减少了模型参数量,同时保持了高性能。
-
ELECTRA: 采用判别器替换生成器的方式进行预训练,提高了计算效率。
-
PanGu-α: 华为诺亚方舟实验室开发的大规模中文预训练模型,拥有2000亿参数。
预训练语言模型的广泛应用
预训练语言模型在NLP领域的各个方面都展现出了强大的能力:
-
文本分类: 在情感分析、主题分类等任务中,预训练模型能够快速适应不同领域,取得优异性能。
-
命名实体识别: 模型能够准确识别和分类文本中的实体,如人名、地名、组织机构等。
-
问答系统: 预训练模型可以理解问题并从给定文本中抽取答案,或生成人类可理解的回答。
-
文本生成: 从写作辅助到对话系统,预训练模型展示了强大的文本生成能力。
-
机器翻译: 通过多语言预训练,模型可以实现高质量的跨语言翻译。
-
文本摘要: 模型能够理解长文本并生成简洁准确的摘要。
-
语义相似度计算: 在信息检索、文本匹配等任务中,预训练模型可以准确计算文本间的语义相似度。
-
代码生成与理解: 一些预训练模型还展示了理解和生成编程代码的能力。

为什么预训练语言模型如此强大?
预训练语言模型的成功可以归因于以下几个关键因素:
-
大规模数据学习: 通过在海量文本上进行预训练,模型可以学习到丰富的语言知识和世界知识。
-
深层网络结构: Transformer等深层结构使模型能够捕捉到语言的复杂模式和长距离依赖。
-
自监督学习: 通过巧妙设计的预训练任务,模型可以从未标注数据中学习有用的表示。
-
迁移学习: 预训练-微调范式使得模型可以将通用知识迁移到特定任务,大大提高了效率和性能。
-
上下文理解: 双向或自回归预训练使模型能够更好地理解语言的上下文信息。
-
多任务学习: 一些模型采用多任务预训练,进一步增强了模型的通用性。
预训练语言模型的挑战与未来发展
尽管预训练语言模型取得了巨大成功,但它们仍然面临一些挑战:
-
计算资源需求: 大规模模型的训练和推理需要巨大的计算资源,限制了其广泛应用。
-
模型压缩: 如何在保持性能的同时减小模型规模是一个重要研究方向。
-
解释性: 大型神经网络模型的"黑箱"性质使其决策过程难以解释。
-
偏见与公平性: 预训练数据中的偏见可能会被模型学习并在下游任务中表现出来。
-
领域适应: 如何更好地将通用预训练模型适应到特定领域仍需进一步研究。
-
多模态学习: 将语言与图像、音频等其他模态结合是未来的重要方向。
-
持续学习: 使模型能够不断学习新知识而不遗忘旧知识是一个挑战。
未来,预训练语言模型的发展可能会朝着以下方向前进:
- 更高效的预训练方法,减少计算资源需求。
- 结合符号推理和神经网络,增强模型的逻辑推理能力。
- 多模态和跨模态预训练,实现更全面的智能。
- 可解释性和可控性的增强,使模型决策更加透明和可信。
- 更好的知识整合和利用机制,使模型成为真正的"知识库"。
- 针对特定领域和任务的定制化预训练策略。
结论
预训练语言模型作为NLP领域的重大突破,不仅推动了学术研究的进展,还在各行各业的实际应用中发挥着越来越重要的作用。它们代表了人工智能向着更加通用和智能的方向迈出的重要一步。尽管仍面临诸多挑战,但预训练语言模型无疑将继续引领NLP技术的发展,为人类社会带来深远的影响。
随着研究的不断深入和技术的持续创新,我们有理由相信,预训练语言模型将在未来为我们带来更多令人兴奋的突破和应用。它们不仅会改变我们与计算机交互的方式,还可能对教育、医疗、科研等多个领域产生深远影响。在这个充满机遇与挑战的时代,密切关注预训练语言模型的发展,积极探索其应用潜力,将是每个NLP研究者和从业者的重要任务。
















