
gpu.cpp: 开启跨平台GPU编程新时代
在当今计算密集型应用日益普及的背景下,如何充分利用GPU的强大计算能力成为许多开发者面临的挑战。gpu.cpp应运而生,为开发者提供了一个轻量级、高效且跨平台的GPU编程解决方案。本文将深入探讨gpu.cpp的设计理念、核心功能、使用方法以及未来发展方向,帮助读者全面了解这一创新工具。
gpu.cpp简介
gpu.cpp是一个轻量级的C++库,旨在简化跨平台GPU计算的实现过程。它基于WebGPU规范,提供了一套简洁的API,使开发者能够轻松地在各种GPU硬件上进行通用计算。无论是NVIDIA、AMD还是Intel的GPU,甚至是移动设备上的GPU,gpu.cpp都能够实现高效的跨平台运行。
这个库的核心目标是为个人开发者和研究人员提供一个高杠杆率的工具,使他们能够将GPU计算轻松集成到自己的项目中,而无需深入了解底层的GPU编程细节。gpu.cpp的设计理念强调轻量化、快速迭代和低样板代码,让开发者能够专注于算法实现,而不是繁琐的GPU编程细节。
核心设计理念
-
高杠杆率API: gpu.cpp提供了最小化的API表面积,但却能覆盖广泛的GPU计算需求。这种设计使得开发者能够用最少的代码实现复杂的GPU计算任务。
-
快速编译运行周期: 库的设计确保了项目能够几乎瞬时完成构建,编译和运行周期通常不超过5秒。这大大提高了开发效率,让开发者能够快速迭代和测试他们的算法。
-
最小化依赖: gpu.cpp仅依赖标准的C++编译器和WebGPU的本地实现,无需其他外部库依赖。这简化了项目的设置和部署过程。
-
透明性和可预测性: 库的设计避免了过度的抽象和封装,使得代码行为更加透明和可预测。这有助于开发者更好地理解和控制GPU计算过程。
-
资源管理优化: gpu.cpp采用了优化的资源管理策略,将资源获取与热路径执行分离,确保关键路径的高效执行。
核心功能和API概览
gpu.cpp的API设计简洁明了,主要包括以下几个核心概念:
- Context: GPU设备上下文,是与GPU交互的核心对象。
- Tensor: 表示GPU上的数据缓冲区。
- KernelCode: 包含WGSL(WebGPU Shading Language)代码的GPU程序。
- Kernel: 可以在GPU上调度执行的完整程序,包含KernelCode和绑定的Tensor资源。
主要的API函数包括:
createContext(): 创建GPU设备上下文createTensor(): 在GPU上分配数据缓冲区createKernel(): 创建可执行的GPU程序dispatchKernel(): 异步调度GPU程序执行wait(): 等待GPU计算完成toCPU(): 将数据从GPU传输到CPUtoGPU(): 将数据从CPU传输到GPU
这些API的设计遵循了"GPU名词"和"GPU动词"的概念,使得代码结构清晰,易于理解和使用。
快速入门:GELU激活函数实现
为了更直观地展示gpu.cpp的使用方法,让我们来看一个实际的例子:实现GELU(Gaussian Error Linear Unit)激活函数。GELU是现代大型语言模型中常用的非线性激活函数。
以下是使用gpu.cpp实现GELU的完整代码示例:
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu;
static const char *kGelu = R"(
const GELU_SCALING_FACTOR: f32 = 0.7978845608028654; // sqrt(2.0 / PI)
@group(0) @binding(0) var<storage, read_write> inp: array<{{precision}}>;
@group(0) @binding(1) var<storage, read_write> out: array<{{precision}}>;
@compute @workgroup_size({{workgroupSize}})
fn main(
@builtin(global_invocation_id) GlobalInvocationID: vec3<u32>) {
let i: u32 = GlobalInvocationID.x;
if (i < arrayLength(&inp)) {
let x: f32 = inp[i];
out[i] = select(0.5 * x * (1.0 + tanh(GELU_SCALING_FACTOR
* (x + .044715 * x * x * x))), x, x > 10.0);
}
}
)";
int main(int argc, char **argv) {
Context ctx = createContext();
static constexpr size_t N = 10000;
std::array<float, N> inputArr, outputArr;
for (int i = 0; i < N; ++i) {
inputArr[i] = static_cast<float>(i) / 10.0; // 模拟输入数据
}
Tensor input = createTensor(ctx, Shape{N}, kf32, inputArr.data());
Tensor output = createTensor(ctx, Shape{N}, kf32);
std::promise<void> promise;
std::future<void> future = promise.get_future();
Kernel op = createKernel(ctx, {kGelu, /* 1-D workgroup size */ 256, kf32},
Bindings{input, output},
/* number of workgroups */ {cdiv(N, 256), 1, 1});
dispatchKernel(ctx, op, promise);
wait(ctx, future);
toCPU(ctx, output, outputArr.data(), sizeof(outputArr));
for (int i = 0; i < 16; ++i) {
printf(" gelu(%.2f) = %.2f\n", inputArr[i], outputArr[i]);
}
return 0;
}
这个例子展示了gpu.cpp的核心工作流程:
- 定义WGSL代码实现GELU计算
- 创建GPU上下文和数据张量
- 创建并配置GPU内核
- 异步调度GPU计算
- 等待计算完成并将结果传回CPU
通过这个简单的例子,我们可以看到gpu.cpp如何简化了GPU编程的复杂性,让开发者能够专注于算法实现。
性能展示:矩阵乘法优化
为了展示gpu.cpp的性能潜力,库的作者实现了一个优化的矩阵乘法示例。这个实现基于Simon Boehm的CUDA矩阵乘法优化教程,采用了分块计算等技术。在MacBook Pro M1 Max笔记本上,该实现达到了约2.5+ TFLOPs的性能,相当于理论峰值10.4 TFLOPs的四分之一左右。
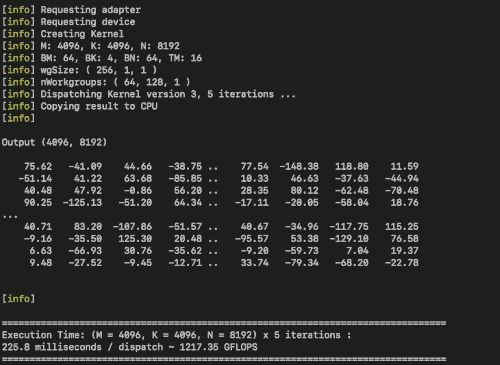
这个性能数据展示了gpu.cpp在实际应用中的强大潜力。虽然与专门优化的CUDA实现相比还有差距,但考虑到其跨平台特性和易用性,这已经是一个非常令人印象深刻的结果。
应用场景和潜在用户
gpu.cpp的设计使其适用于广泛的应用场景,包括但不限于:
- GPU算法开发: 研究人员和开发者可以快速原型化和测试新的GPU算法。
- 神经网络模型直接实现: 可以直接实现神经网络模型,而无需依赖大型深度学习框架。
- 物理仿真: 实现高性能的并行物理仿真,如粒子系统或流体动力学模拟。
- 多模态应用: 音频和视频处理等需要高计算能力的多模态应用。
- 离线图形渲染: 实现高效的离线渲染算法。
- 机器学习推理引擎: 构建轻量级的ML推理引擎和运行时。
- 并行数据处理: 实现高性能的并行数据处理应用。
gpu.cpp特别适合那些需要在个人计算设备上进行GPU计算的项目,如探索新的AI算法、动态模型压缩、实时多模态集成等。它为开发者提供了一个灵活的平台,可以在各种GPU硬件上实现高效的计算,同时保持代码的可移植性。
未来发展方向
尽管gpu.cpp已经展现出了强大的潜力,但它仍处于积极发展阶段。以下是一些计划中的改进和新特性:
- API优化: 进一步完善API设计,特别是在结构化参数处理和异步调度方面。
- 浏览器目标支持: 虽然基于WebGPU,但目前尚未测试针对浏览器的构建。这是短期内的一个重要目标。
- 可重用内核库: 计划将成熟的内核实现从特定示例迁移到一个小型可重用内核库中。
- 更多用例示例和测试: 将继续添加更多实际应用示例,以展示库的能力并指导API的改进。
- 性能优化: 持续优化现有实现,缩小与专门优化的CUDA实现之间的性能差距。
结语
gpu.cpp代表了GPU编程的一个新方向,它将强大的计算能力与简单易用的API相结合,为开发者打开了GPU编程的新世界。无论是研究人员、独立开发者还是企业开发团队,都可以从这个轻量级但功能强大的库中受益。
随着GPU在各种计算设备中变得越来越普遍,gpu.cpp这样的工具将在推动GPU计算普及化方面发挥重要作用。它不仅简化了GPU编程的复杂性,还为开发者提供了一个跨平台的解决方案,使他们能够充分利用各种硬件的计算能力。
我们期待看到gpu.cpp在未来的发展,以及它将如何影响和推动GPU编程领域的创新。对于那些对GPU编程感兴趣或者需要在项目中集成GPU计算的开发者来说,gpu.cpp无疑是一个值得关注和尝试的工具。

通过继续关注gpu.cpp项目的发展,参与社区讨论,甚至贡献代码,我们都可以成为这场GPU编程革命的一部分。让我们共同期待gpu.cpp为GPU计算世界带来更多可能性和创新。


















