
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文OmniFusion
OmniFusion是一种先进的多模态人工智能模型,旨在通过整合图像以及潜在的音频、3D和视频内容等额外数据模态来扩展传统语言处理系统的能力。
更新日志
[2024年4月10日] OmniFusion-1.1权重已上传至Huggingface。现在模型可以说俄语了 :)
[2024年4月1日] 发布了OmniFusion-1.1的模型训练源代码
[2023年11月22日] OmniFusion权重可在Huggingface上获取
架构
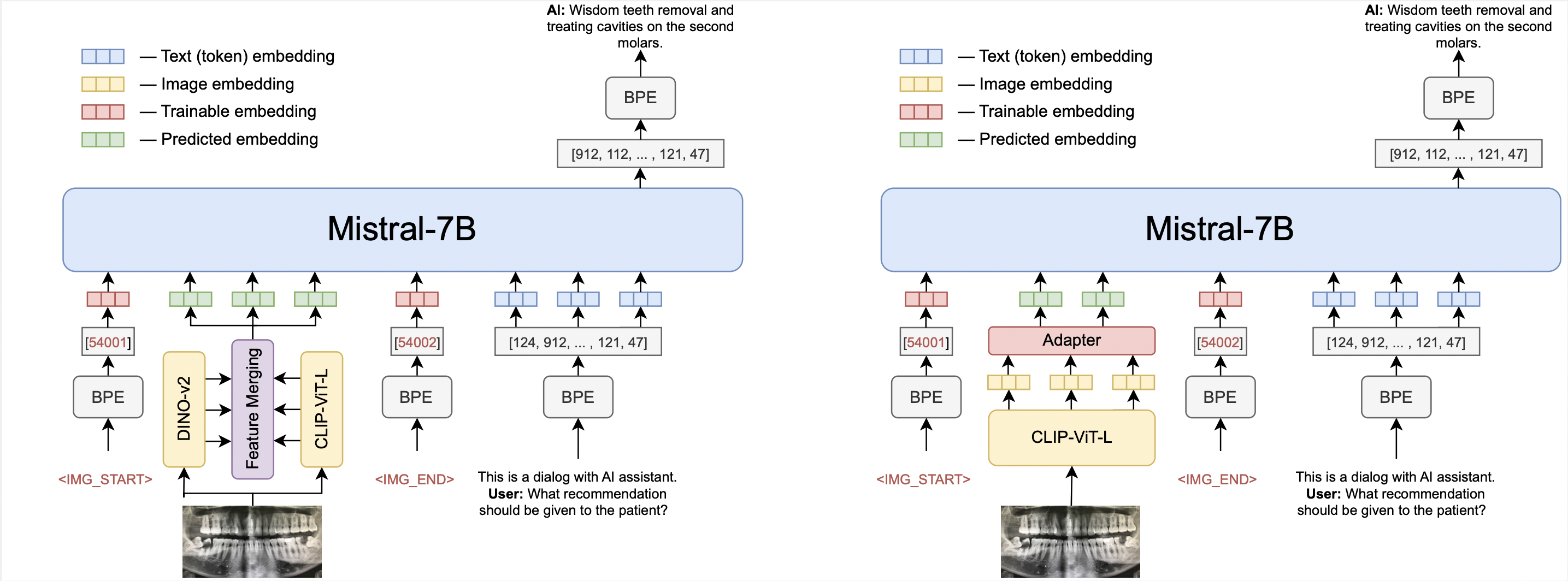
开源OmniFusion的核心是Mistral-7B。模型有两个版本:第一个使用一个视觉编码器CLIP-ViT-L,第二个使用两个编码器(CLIP-ViT-L和Dino V2)。最初专注于图像处理,我们选择CLIP-ViT-L作为视觉编码器,因为它具有高效的信息传输能力。
OmniFusion最重要的组件是其适配器,这是一种允许语言模型解释和整合不同模态信息的机制。对于单编码器版本,适配器是一个单层四头的transformer层,相比更简单的线性层或MLP结构表现更优。具有两个编码器的模型使用一个从视觉编码器的所有层收集特征的适配器,这个适配器没有注意力层。
适配器接收视觉编码器的嵌入(不包括CLS标记),并将其映射为与语言模型兼容的文本嵌入。
为进一步增强模型的多模态能力,我们使用可学习的自定义标记来标记文本序列中视觉数据的开始和结束。
训练过程包括两个阶段
- 在图像描述任务(LAION、CC-4M等)上预训练适配器。
- 一旦适配器学会将视觉嵌入映射到语言模型的文本空间,我们解冻Mistral以提高对话格式和复杂查询的理解能力。
- 数据集由英语和俄语数据组成,结构如下:
| 任务 | 数据集来源 | 样本数量 |
|---|---|---|
| 图像描述 | ShareGPT4V | 100K |
| 视觉问答 | COCO, SAM-9K | 20K, 9K |
| 网络问答 | WebData | 1.5K |
| OCR问答 | TextVQA, OCRVQA | 120K |
| 对话 | LLaVA-v1.5-665K, OCRVQA | 665K |
| 文档视觉问答 | 专有数据(俄语) | 20K |
| 纯文本微调 | 专有数据(俄语), Alpaca(英语) | 10K |
使用方法
import torch
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
from urllib.request import urlopen
import torch.nn as nn
from huggingface_hub import hf_hub_download
# 加载投影适配器和图像编码器的一些源文件
hf_hub_download(repo_id="AIRI-Institute/OmniFusion", filename="models.py", local_dir='./')
from models import CLIPVisionTower
DEVICE = "cuda:0"
PROMPT = "这是与AI助手的对话。\n"
tokenizer = AutoTokenizer.from_pretrained("AIRI-Institute/OmniFusion", subfolder="OmniMistral-v1_1/tokenizer", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("AIRI-Institute/OmniFusion", subfolder="OmniMistral-v1_1/tuned-model", torch_dtype=torch.bfloat16, device_map=DEVICE)
hf_hub_download(repo_id="AIRI-Institute/OmniFusion", filename="OmniMistral-v1_1/projection.pt", local_dir='./')
hf_hub_download(repo_id="AIRI-Institute/OmniFusion", filename="OmniMistral-v1_1/special_embeddings.pt", local_dir='./')
projection = torch.load("OmniMistral-v1_1/projection.pt", map_location=DEVICE)
special_embs = torch.load("OmniMistral-v1_1/special_embeddings.pt", map_location=DEVICE)
clip = CLIPVisionTower("openai/clip-vit-large-patch14-336")
clip.load_model()
clip = clip.to(device=DEVICE, dtype=torch.bfloat16)
def gen_answer(model, tokenizer, clip, projection, query, special_embs, image=None):
bad_words_ids = tokenizer(["\n", "</s>", ":"], add_special_tokens=False).input_ids + [[13]]
gen_params = {
"do_sample": False,
"max_new_tokens": 50,
"early_stopping": True,
"num_beams": 3,
"repetition_penalty": 1.0,
"remove_invalid_values": True,
"eos_token_id": 2,
"pad_token_id": 2,
"forced_eos_token_id": 2,
"use_cache": True,
"no_repeat_ngram_size": 4,
"bad_words_ids": bad_words_ids,
"num_return_sequences": 1,
}
with torch.no_grad():
image_features = clip.image_processor(image, return_tensors='pt')
image_embedding = clip(image_features['pixel_values']).to(device=DEVICE, dtype=torch.bfloat16)
projected_vision_embeddings = projection(image_embedding).to(device=DEVICE, dtype=torch.bfloat16)
prompt_ids = tokenizer.encode(f"{PROMPT}", add_special_tokens=False, return_tensors="pt").to(device=DEVICE)
question_ids = tokenizer.encode(query, add_special_tokens=False, return_tensors="pt").to(device=DEVICE)
prompt_embeddings = model.model.embed_tokens(prompt_ids).to(torch.bfloat16)
question_embeddings = model.model.embed_tokens(question_ids).to(torch.bfloat16)
embeddings = torch.cat(
[
prompt_embeddings,
special_embs['SOI'][None, None, ...],
projected_vision_embeddings,
special_embs['EOI'][None, None, ...],
special_embs['USER'][None, None, ...],
question_embeddings,
special_embs['BOT'][None, None, ...]
],
dim=1,
).to(dtype=torch.bfloat16, device=DEVICE)
out = model.generate(inputs_embeds=embeddings, **gen_params)
out = out[:, 1:]
generated_texts = tokenizer.batch_decode(out)[0]
return generated_texts
img_url = "https://i.pinimg.com/originals/32/c7/81/32c78115cb47fd4825e6907a83b7afff.jpg" question = "这张图片中天空的颜色是什么?" img = Image.open(urlopen(img_url))
answer = gen_answer( model, tokenizer, clip, projection, query=question, special_embs=special_embs, image=img )
img.show() print(question) print(answer)
### 结果
OmniFusion与最新的多模态SOTA模型进行了基准测试。它在生成指标和TextVQA等分类基准测试中表现出色。
OmniFusion-1.1(GigaChat LLM)在各种基准测试上的结果:
<p align="left">
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/6b711ead-52c5-4fc5-9dda-7aa7823cd9b6.png" width="50%">
</p>
Omifusion-1.0结果:
<p align="left">
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/47777cb0-ff47-4668-9a52-168f6938f6f2.png" width="50%">
</p>
Omifusion-1.1(Mistral)
| 模型 | textvqa| scienceqa | pope | gqa | ok_vqa |
| -------------------------------------- | ------ | ---------- | --------- | -------- | ------- |
| OmniFusion-1.1(单编码器,Mistral) | **0.4893** | **0.6802** | 0.7818 | 0.4600 | 0.5187 |
| OmniFusion-1.1(双编码器,Mistral) | 0.4755 | 0.6732 | **0.8153** | **0.4761** | **0.5317** |
Omifusion-1.0(前一版本)在视觉对话基准测试上的表现
| 模型 | NDCG | MRR | Recall@1 | Recall@5 | Recall@10 |
| ------------ | ---- | ---- | -------- | -------- | --------- |
| OmniFusion | 25.91| 10.78| 4.74 | 13.80 | 20.53 |
| LLaVA-13B | 24.74| 8.91 | 2.98 | 10.80 | 18.02 |
### OmniFusion-1.1示例
<p align="left">
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/210ac9e3-ed4a-4c55-a673-b4f49b268554.png" width="100%">
</p>
<p align="left">
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/598797b4-6f34-4edd-a655-f5a9290529ea.png" width="100%">
</p>
### OmniFusion-1.0示例
<p align="left">
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/80241ff1-3a44-411b-8723-ccb24c7ae7e0.png" width="100%">
</p>
### 未来计划
目前正在开发一个能够理解俄语、使用ImageBind编码器并接受更多模态(声音、3D、视频)的版本。请关注GitHub上的更新!
### 作者
来自AIRI研究所的FusionBrain科学小组与Sber AI的科学家合作领导了该模型的开发。
主要贡献者:
+ Anton Razzhigaev:[博客](https://t.me/abstractDL)
+ Elizaveta Goncharova
+ Matvey Mihkalchuk
+ Maxim Kurkin
+ Irina Abdullaeva
+ Denis Dimitrov [博客](https://t.me/dendi_math_ai)
+ Andrey Kuznetsov [博客](https://t.me/complete_ai)












{kind=link}