
 访问官网
访问官网 Github
Github 文档
文档 论文
论文EEG-ATCNet
![]()
本仓库提供了论文《基于物理信息的注意力时间卷积网络用于脑电图运动想象分类》中提出的注意力时间卷积网络(ATCNet)的代码。
作者:Hamdi Altaheri, Ghulam Muhammad, Mansour Alsulaiman
沙特阿拉伯国王大学智能机器人研究中心
更新:
- ATCNet的正则化参数已经修改,resulting in提高了模型性能并增强了抗过拟合能力。
- 目前的main_TrainTest.py文件遵循论文1和论文2中概述的训练和评估方法,但已被确定为不符合行业最佳实践。因此,我们强烈建议采用在改进的main_TrainValTest.py文件中实现的方法。这个更新版本将数据分为训练/验证/测试集,遵循这篇文章中详细说明的指南(选项2)。
除了提出的ATCNet模型外,models.py文件还包括其他相关方法的实现,这些方法可以与ATCNet进行比较,包括:
- EEGNet,[论文,原始代码]
- EEG-TCNet,[论文,原始代码]
- TCNet_Fusion,[论文]
- MBEEG_SENet,[论文]
- EEGNeX,[论文,原始代码]
- DeepConvNet,[论文,原始代码]
- ShallowConvNet,[论文,原始代码]
下表显示了ATCNet和其他复现模型基于main_TrainValTest.py文件中定义的方法的性能:
| 模型 | 参数数量 | BCI 竞赛 IV-2a 数据集 (BCI 4-2a) | 高伽马数据集 (HGD)* | ||
| 训练时间(分钟)1,2 | 准确率(%) | 训练时间(分钟)1,2 | 准确率(%) | ||
| ATCNet | 113,732 | 13.5 | 81.10 | 62.6 | 92.05 |
| TCNet_Fusion | 17,248 | 8.8 | 69.83 | 65.2 | 89.73 |
| EEGTCNet | 4,096 | 7.0 | 65.36 | 36.8 | 87.80 |
| MBEEG_SENet | 10,170 | 15.2 | 69.21 | 104.3 | 90.13 |
| EEGNet | 2,548 | 6.3 | 68.67 | 36.5 | 88.25 |
| DeepConvNet | 553,654 | 7.5 | 42.78 | 43.9 | 87.53 |
| ShallowConvNet | 47,364 | 8.2 | 67.48 | 61.8 | 87.00 |
2 (500轮,无提前停止)
* 请注意,HGD用于"实际运动"而非"运动想象"
本仓库在attention_models.py文件中包含以下注意力机制的实现:
这些注意力模块可以通过attention_models.py文件中的*attention_block(net, attention_model)方法调用,其中'net'是输入层,'attention_model'*表示注意力机制的类型,有五个选项:None、'mha'、'mhla'、'cbam'和'se'。
示例:
input = Input(shape = (10, 100, 1))
block1 = Conv2D(1, (1, 10))(input)
block2 = attention_block(block1, 'mha') # mha: 多头自注意力
output = Dense(4, activation="softmax")(Flatten()(block2))
preprocess.py文件基于两种方法加载和划分数据集:
- 特定受试者(受试者相关)方法。在这种方法中,我们使用与原始BCI-IV-2a竞赛划分相同的训练和测试数据,即第1阶段的试验用于训练,第2阶段的试验用于测试。
- 留一受试者法(LOSO)方法。LOSO用于受试者无关评估。在LOSO中,模型通过多个折叠进行训练和评估,折叠数等于受试者数量,每个折叠中使用一个受试者进行评估,其他受试者用于训练。LOSO评估技术确保使用训练数据中未出现的独立受试者来评估模型。
preprocess.py文件中的get_data()方法用于加载数据集并将其分为训练集和测试集。该方法默认使用特定受试者方法。如果您想使用受试者无关(LOSO)方法,请将参数LOSO设置为True。
关于ATCNet
ATCNet部分受到Vision Transformer (ViT)的启发。ATCNet与ViT的区别如下:
- ViT使用单层线性投影,而ATCNet使用多层非线性投影,即专门为基于EEG的脑信号设计的卷积投影。
- ViT由一系列编码器堆叠而成,前一个编码器的输出是后一个的输入。ATCNet由并行编码器组成,所有编码器的输出被连接起来。
- ViT中的编码器块由多头自注意力(MHA)和多层感知器(MLP)组成,而ATCNet中MHA后面是时间卷积网络(TCN)。
- ViT的第一个编码器接收整个输入序列,而ATCNet中每个编码器接收输入序列的移动窗口。
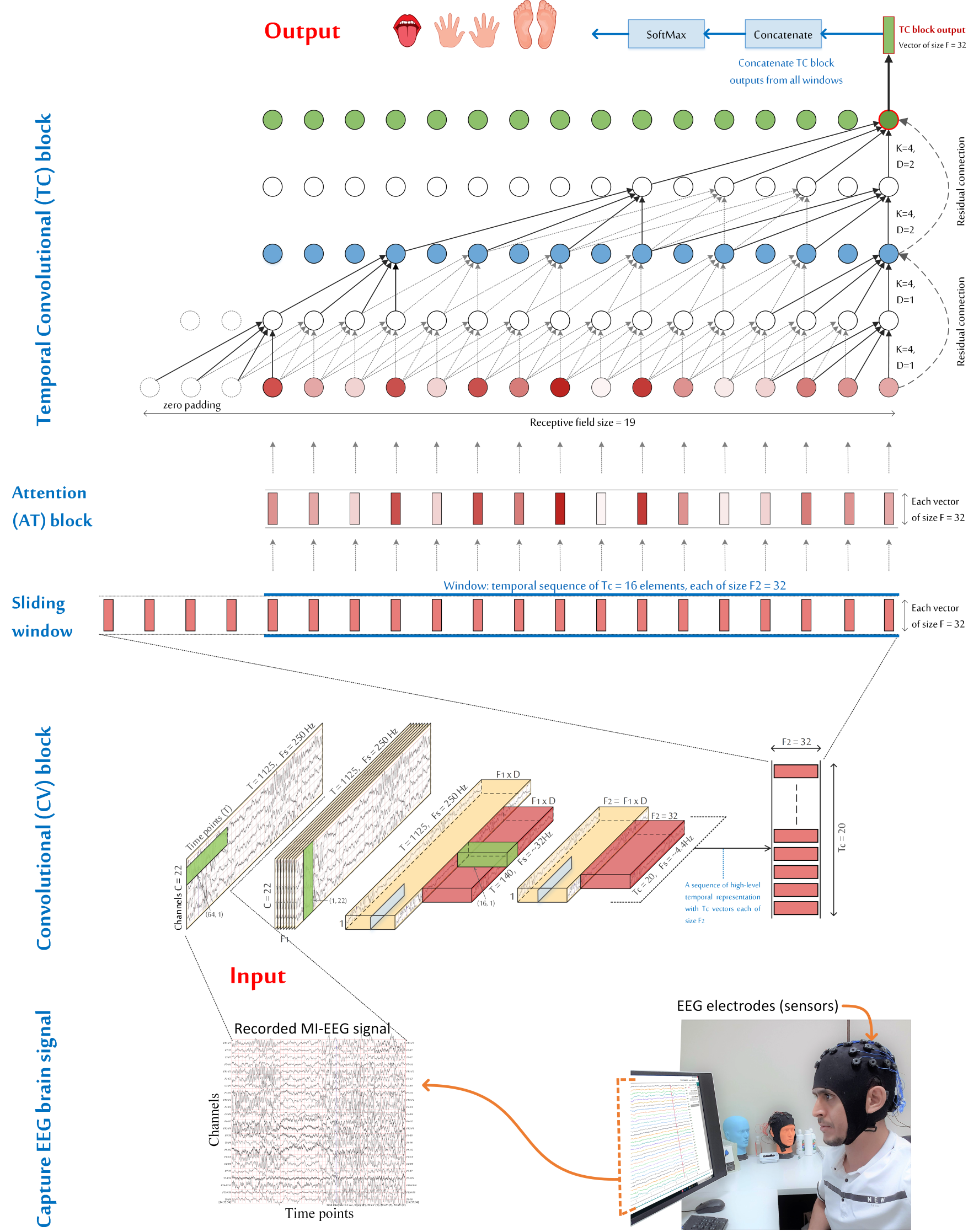
ATCNet模型由三个主要模块组成:
- 卷积(CV)模块:通过三个卷积层将MI-EEG信号中的低级时空信息编码为高级时间表示序列。
- 注意力(AT)模块:使用多头自注意力(MHA)突出时间序列中最重要的信息。
- 时间卷积(TC)模块:使用时间卷积层从突出的信息中提取高级时间特征。
- ATCNet模型还利用基于卷积的滑动窗口来增强MI数据并有效提升MI分类性能。
可视化ATCNet模型中数据的转换。
开发环境
模型的训练和测试使用单个GPU,Nvidia GTX 2070 8GB(驱动版本:512.78,CUDA 11.3),使用Python 3.7和TensorFlow框架。在Ubuntu 20.04.4 LTS和Windows 11上使用Anaconda 3。 需要以下软件包:
- TensorFlow 2.7
- matplotlib 3.5
- NumPy 1.20
- scikit-learn 1.0
- SciPy 1.7
数据集
需要下载BCI Competition IV-2a数据集,并在main_TrainValTest.py文件中的'data_path'变量中设置数据路径。数据集可以从这里下载。
参考文献
如果您在研究中发现本工作有用,请使用以下BibTeX条目进行引用
[BibTeX引用信息略]











