
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文语言: 英文 简体中文
Diffusion-SVC



此仓库是DDSP-SVC仓库的扩散部分的单独存放。可单独训练和推理。
Diffusion SVC 2.0 即将到来,可在v2.0_dev分支提前体验:前往分支
最近更新:使用本仓库的naive模型和浅扩散模型搭配可以用极低训练成本达到比单纯扩散模型更好的效果,强力推荐。但是小网络的naive模型泛化能力较弱,在小数据集上可能会有音域问题,这个时候naive模型微调不能训练太多步数(这会让底模退化),前级也可以考虑更换为无限音域的ddsp模型。
效果和介绍见[介绍视频(暂未完成)]
欢迎加群交流讨论:882426004
0.简介
Diffusion-SVC 是DDSP-SVC仓库的扩散部分的单独存放。可单独训练和推理。
相比于比较著名的 Diff-SVC, 本项目的显存占用少得多,训练和推理速度更快,并针对浅扩散和实时用途有专门优化。可以在较强的GPU上实时推理。配合本项目的naive模型进行浅扩散,即使是较弱的GPU也可以实时生成质量优秀的音频。
如果训练数据和输入源的质量都非常高,Diffusion-SVC可能拥有最好的转换效果。
本项目可以很容易的级联在别的声学模型之后进行浅扩散,以改善最终的输出效果或降低性能占用。例如在DDSP-SVC和本项目的naive模型后级联Diffusion-SVC,可进一步减少需要的扩散步数并得到高质量的输出。
除此之外,本项目还可以单独训练浅扩散所需的降噪步数而不训练完整的从高斯噪声开始的降噪过程,这可以提高训练速度并改善质量,更多信息见下文。
免责声明:请确保仅使用合法获得的授权数据训练 Diffusion-SVC 模型,不要将这些模型及其合成的任何音频用于非法目的。 本库作者不对因使用这些模型检查点和音频而造成的任何侵权,诈骗等违法行为负责。
1. 安装依赖
-
安装PyTorch:我们推荐从 PyTorch 官方网站 下载 PyTorch.
-
安装依赖
pip install -r requirements.txt
2. 配置预训练模型
- (必要操作) 下载预训练 ContentVec 编码器并将其放到
pretrain文件夹。经过裁剪的ContentVec镜像有完全一样的效果,但大小只有190MB。- 注意:也可以使用别的特征提取,但仍然优先推荐ContentVec。支持的所有特征提取见
tools/tools.py中的Units_Encoder类。
- 注意:也可以使用别的特征提取,但仍然优先推荐ContentVec。支持的所有特征提取见
- (必要操作) 从 DiffSinger 社区声码器项目 下载预训练声码器,并解压至
pretrain/文件夹。- 注意:你应当下载名称中带有
nsf_hifigan的压缩文件,而非nsf_hifigan_finetune。
- 注意:你应当下载名称中带有
如果需要使用声纹模型,则需要将配置文件的use_speaker_encoder设置为true, 并从这里下载预训练声纹模型,该模型来自mozilla/TTS。
3. 预处理
1. 配置训练数据集和验证数据集
1.1 手动配置:
将所有的训练集数据 (.wav 格式音频切片) 放到 data/train/audio,也可以是配置文件中指定的文件夹如xxxx/yyyy/audio。
将所有验证集数据(.wav 格式音频切片)放到 data/val/audio 目录下,也可以是配置文件中指定的文件夹,如 aaaa/bbbb/audio。
1.2 程序随机选择:
运行 python draw.py,程序将帮助你挑选验证集数据(可以调整 draw.py 中的参数修改抽取文件的数量等参数)。
1.3 文件夹结构目录展示:
注意:说话人 ID 必须从 1 开始,不能从 0 开始;如果只有一个说话人,则该说话人 ID 必须为 1
- 目录结构:
data
├─ train
│ ├─ audio
│ │ ├─ 1
│ │ │ ├─ aaa.wav
│ │ │ ├─ bbb.wav
│ │ │ └─ ....wav
│ │ ├─ 2
│ │ │ ├─ ccc.wav
│ │ │ ├─ ddd.wav
│ │ │ └─ ....wav
│ │ └─ ...
|
├─ val
| ├─ audio
│ │ ├─ 1
│ │ │ ├─ eee.wav
│ │ │ ├─ fff.wav
│ │ │ └─ ....wav
│ │ ├─ 2
│ │ │ ├─ ggg.wav
│ │ │ ├─ hhh.wav
│ │ │ └─ ....wav
│ │ └─ ...
2. 正式预处理
python preprocess.py -c configs/config.yaml
您可以在预处理之前修改配置文件 configs/config.yaml
3. 备注:
-
请保持所有音频切片的采样率与 yaml 配置文件中的采样率一致!(推荐使用 fap 进行重采样等前处理)
-
将长音频切成小段可以加快训练速度,但所有音频切片的时长不应少于 2 秒。如果音频切片太多,则需要较大的内存,可以在配置文件中将
cache_all_data选项设置为 false 来解决此问题。 -
验证集的音频切片总数建议为 10 个左右,不要放太多,否则验证过程会很慢。
-
如果您的数据集质量不是很高,请在配置文件中将 'f0_extractor' 设为 'crepe'。crepe 算法的抗噪性最好,但代价是会极大增加数据预处理所需的时间。
-
配置文件中的 'n_spk' 参数将控制是否训练多说话人模型。如果您要训练多说话人模型,为了对说话人进行编号,所有音频文件夹的名称必须是不大于 'n_spk' 的正整数
4. 训练
1. 不使用预训练数据进行训练:
python train.py -c configs/config.yaml
2. 预训练模型:
-
我们强烈建议使用预训练模型进行微调,这将比直接训练容易和节省得多,并能达到比小数据集更高的上限。
-
注意,在底模上微调需要使用和底模一样的编码器,如同为 ContentVec,对别的编码器(如声纹)也是同理,还要注意模型的网络大小等参数相同。
!!!!!!!!!推荐训练浅扩散模型+naive模型!!!!!!!!!
只训练 k_step_max 深度的浅扩散模型与 naive 模型的组合比单纯完全扩散的质量可能还要更高,同时训练速度更快。但是 naive 模型可能存在音域问题。
2.1 训练完整过程的扩散预训练模型
(注意:whisper-ppg 对应 whisper 的 medium 权重,whisper-ppg-large 对应 whisper 的 large-v2 权重)
| Units 编码器 | 网络大小 | 数据集 | 下载 |
|---|---|---|---|
| contentvec768l12(推荐) | 512*20 | VCTK m4singer | HuggingFace |
| hubertsoft | 512*20 | VCTK m4singer | HuggingFace |
| whisper-ppg(仅支持 sovits) | 512*20 | VCTK m4singer opencpop kiritan | HuggingFace |
补充一个用 contentvec768l12 编码的整活底模,数据集为 m4singer/opencpop/vctk,不推荐使用,不保证没问题:下载。
2.2 仅训练k_step_max深度的扩散预训练模型
(注意:whisper-ppg对应whisper的medium权重,whisper-ppg-large对应whisper的large-v2权重)
| 使用的编码器 | 网络大小 | k_step_max | 数据集 | 浅扩散模型下载 |
|---|---|---|---|---|
| contentvec768l12 | 512*30 | 100 | VCTK m4singer | HuggingFace |
| contentvec768l12 | 512*20 | 200 | VCTK m4singer | HuggingFace |
| contentvec256l9 | 512*20 | 200 | VCTK m4singer | HuggingFace |
| contentvec256l9 | 768*30 | 200 | VCTK m4singer | HuggingFace |
| whisper-ppg(仅支持sovits) | 768*30 | 200 | PTDB m4singer | HuggingFace |
- 实验表明,naive模型在小数据集上存在音域问题,建议优先考虑使用较少步数微调naive模型或直接使用无限音域的ddsp模型
2.3 与2.2配套的Naive预训练模型和DDSP预训练模型
| 使用的编码器 | 网络大小 | 数据集 | 类型 | Naive模型下载 |
|---|---|---|---|---|
| contentvec768l12 | 3*256 | VCTK m4singer | Naive | HuggingFace |
- 注意:naive预训练模型也可用作完整扩散模型的前级naive模型。微调shallow模型时建议将配置文件中的
decay_step改小(如10000)。
3. 使用预训练数据(底模)进行训练:
- 欢迎PR训练的多人底模(请使用授权同意开源的数据集进行训练)。
- 预训练模型见上文,需要特别注意使用相同编码器的模型。
- 将名为
model_0.pt的预训练模型放到config.yaml中"expdir: exp/*****"参数指定的模型导出文件夹内,如果没有就新建一个,程序会自动加载该文件夹下的预训练模型。 - 按照不使用预训练数据进行训练的方式启动训练。
4.1. Naive模型与组合模型
Naive模型
Naive模型是一个轻量级的svc模型,可以作为浅扩散的前级,训练方式与扩散模型一致,示例配置文件在configs/config_naive.yaml。其所需的预处理和扩散模型是一样的。
python train.py -c configs/config_naive.yaml
推理时使用-nmodel指向模型文件以使用,此时必须要指定浅扩散深度-kstep。
组合模型
使用combo.py可以将一个扩散模型和一个naive模型组合为一个combo模型,只需此模型就能实现浅扩散。这两个模型需要使用相同的参数训练(如相同的说话人id),因为推理时它们也使用相同的参数推理。
python combo.py -model <model> -nmodel <nmodel> -exp <exp> -n <name>
使用以上命令将两个模型组合。其中-model是扩散模型的路径,-nmodel是naive模型的路径;与模型同目录下的配置文件也会自动读取。-exp是输出组合模型的目录,-n是保存的组合模型名。上述命令会在<exp>下输出组合模型为<name>.ptc。
组合模型可直接在推理时作为扩散模型被正确加载用于浅扩散,而无需额外输入-nmodel来加载naive模型。
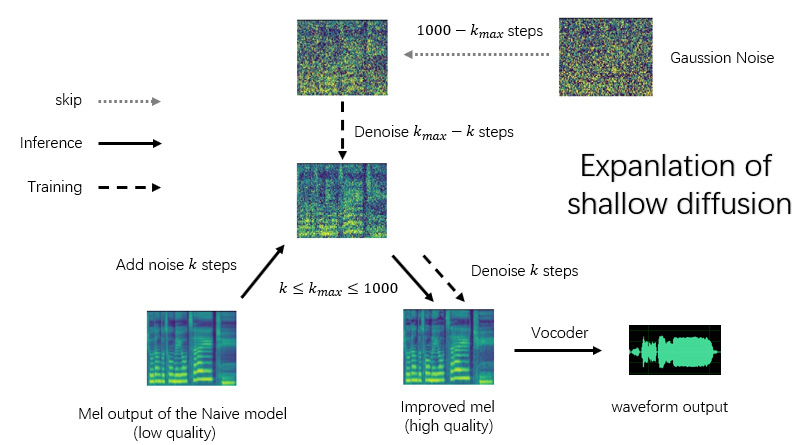
4.2. 关于k_step_max与浅扩散
(示意图见readme开头)
在浅扩散过程中,扩散模型只从一定加噪深度开始扩散,而无需从高斯噪声开始。因此,在浅扩散用途下,扩散模型也可以只训练一定加噪深度而不用从高斯噪声开始。
在配置文件中指定k_step_max为扩散深度来进行这种训练,该值必须小于1000(这是完整扩散的步数)。这样训练的模型不能单独推理,必须在前级模型的输出结果上或输入源上进行浅扩散;扩散的最大深度不能超过k_step_max。
示例配置文件见configs/config_shallow.yaml。
建议将这种只能浅扩散的扩散模型与naive模型组合为组合模型使用。
5. 可视化
# 使用tensorboard检查训练状态
tensorboard --logdir=exp
第一次验证后,在TensorBoard中可以看到合成后的测试音频。
6. 非实时推理
python main.py -i <input.wav> -model <model_ckpt.pt> -o <output.wav> -k <keychange> -id <speaker_id> -speedup <speedup> -method <method> -kstep <kstep> -nmodel <nmodel> -pe <f0_extractor>
-model是模型的路径,-k是变调,-speedup为加速倍速,-method为pndm、ddim、unipc或dpm-solver,-kstep为浅扩散步数,-id为扩散模型的说话人id。
如果-kstep不为空,则以输入源的mel进行浅扩散,若-kstep为空,则进行完整深度的高斯扩散。
-nmodel(可选,需要单独训练)是naive模型的路径,用来提供一个大致的mel给扩散模型进行k_step深度的浅扩散,其参数需要与主模型匹配。
-pe可选项为crepe、parselmouth、dio、harvest、rmvpe,默认为crepe。
如果使用了声纹编码,那么可以通过-spkemb指定一个外部声纹,或者通过-spkembdict覆盖模型的声纹词典。
7. Units索引(可选,不推荐)
与RVC和so-vits-svc类似的特征索引。
注意,此为可选功能,无索引也可正常使用,索引会占用大量存储空间,索引时还会大量占用CPU,此功能不推荐使用。
# 训练特征索引,需要先完成预处理
python train_units_index.py -c config.yaml
推理时,使用-lr参数使用。此参数为检索比率。
8. 实时推理
推荐使用本仓库自带的GUI进行实时推理,如果需要使用浅扩散请先组合模型。
python gui_realtime.py
本项目也可配合rtvc实现实时推理。
注意:目前flask_api为实验性功能,rtvc也未完善,不推荐使用此方式。
pip install rtvc
python rtvc
python flask_api.py
9. 兼容性
9.1. Units编码器
| Diffusion-SVC | DDSP-SVC | so-vits-svc | |
|---|---|---|---|
| ContentVec | √ | √ | √ |
| HubertSoft | √ | √ | √ |
| Hubert(Base,Large) | √ | √ | × |
| CNHubert(Base,Large) | √ | √ | √* |
| CNHubertSoft | √ | √ | × |
| Wav2Vec2-xlsr-53-espeak-cv-ft | √* | × | × |
| DPHubert | × | × | √ |
| Whisper-PPG | × | × | √* |
| WavLM(Base,Large) | × | × | √* |
10. Colab
可以使用TheMandateOfRock写的笔记Diffusion_SVC_CN.ipynb;由于我没有条件测试,所以有关问题请向笔记作者反馈。(我摸了)
11. Onnx导出
在exp文件夹下创建一个新文件夹(该文件夹的名字就是等会命令中的ProjectName),将模型和配置文件放置入其中,模型重命名为model.pt,配置为config.yaml
然后执行以下命令进行导出。
python diffusion/onnx_export.py --project <ProjectName>
导出完成之后会自动创建MoeVS的配置文件,感谢NaruseMioShirakana(同时也是MoeVS的作者)提供的onnx导出支持。











