
 访问官网
访问官网 Github
Github 文档
文档 论文
论文CoDet: 基于共现引导的区域-词语对齐的开放词汇目标检测
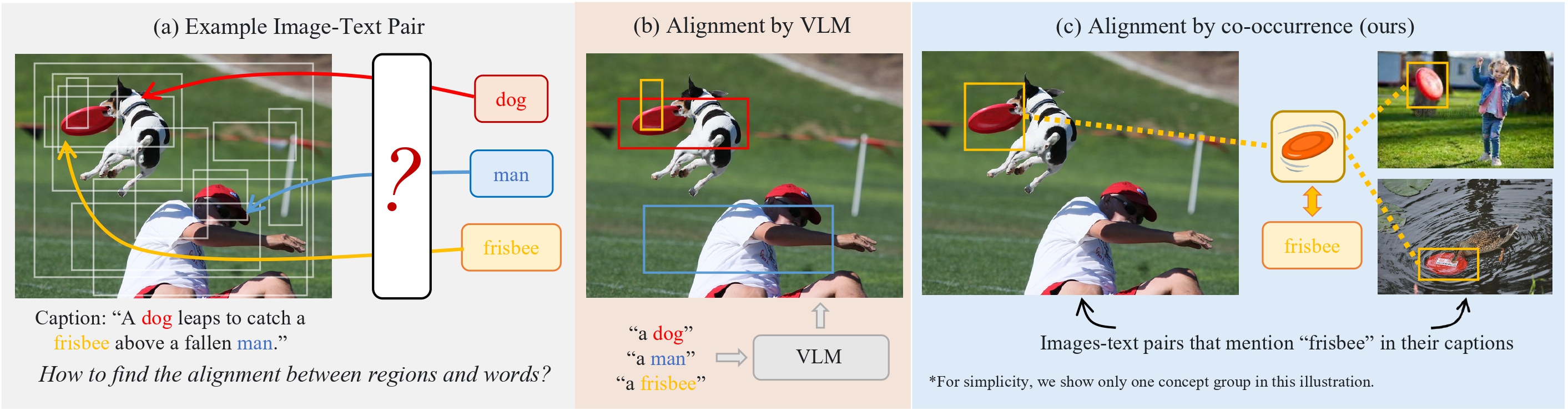
CoDet: 基于共现引导的区域-词语对齐的开放词汇目标检测,
Chuofan Ma, Yi Jiang, Xin Wen, Zehuan Yuan, Xiaojuan Qi
NeurIPS 2023 (https://arxiv.org/abs/2310.16667)
项目主页 (https://codet-ovd.github.io)
特点
- 使用网络规模的图像-文本对训练开放词汇检测器
- 通过共现而非区域-文本相似度来对齐区域和词语
- 在开放词汇LVIS上达到最先进性能
- 部署现代视觉基础模型
- 与roboflow集成,自动标注图像以训练小型微调模型
安装
设置环境
conda create --name codet python=3.8 -y && conda activate codet
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
git clone https://github.com/CVMI-Lab/CoDet.git
安装Apex和xFormer(如果不使用EVA-02骨干网络,可以跳过此步骤)
pip install ninja
pip install -v -U git+https://github.com/facebookresearch/xformers.git@7e05e2caaaf8060c1c6baadc2b04db02d5458a94
git clone https://github.com/NVIDIA/apex && cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./ && cd ..
安装detectron2和其他依赖
cd CoDet/third_party/detectron2
pip install -e .
cd ../..
pip install -r requirements.txt
准备数据集
我们使用LVIS和Conceptual Caption (CC3M)进行OV-LVIS实验,
COCO进行OV-COCO实验,
以及Objects365进行跨数据集评估。
在开始处理之前,请从官方网站下载(选定的)数据集,并将它们放置或软链接到CoDet/datasets/下。
CoDet/datasets/metadata/是预处理的元数据(包含在仓库中)。
更多详情请参考DATA.md。
$CoDet/datasets/
metadata/
lvis/
coco/
cc3m/
objects365/
模型库
OV-COCO
| 骨干网络 | 框AP50 | 框AP50_新类别 | 配置 | 模型 |
|---|---|---|---|---|
| ResNet50 | 46.8 | 30.6 | CoDet_OVCOCO_R50_1x.yaml | 检查点 |
OV-LVIS
| 骨干网络 | 掩码 mAP | 新类掩码 mAP | 配置 | 模型 |
|---|---|---|---|---|
| ResNet50 | 31.3 | 23.7 | CoDet_OVLVIS_R5021k_4x_ft4x.yaml | 检查点 |
| Swin-B | 39.2 | 29.4 | CoDet_OVLVIS_SwinB_4x_ft4x.yaml | 检查点 |
| EVA02-L | 44.7 | 37.0 | CoDet_OVLVIS_EVA_4x.yaml | 检查点 |
推理
要使用自定义图像/视频进行测试,请运行
python demo.py --config-file [配置文件] --input [你的图像文件] --output [输出文件路径] --vocabulary lvis --opts MODEL.WEIGHTS [模型权重]
或者你可以自定义测试词汇表,例如:
python demo.py --config-file [配置文件] --input [你的图像文件] --output [输出文件路径] --vocabulary custom --custom_vocabulary 耳机,网络摄像头,纸,咖啡 --confidence-threshold 0.3 --opts MODEL.WEIGHTS [模型权重]
要评估预训练模型,请运行
python train_net.py --num-gpus $GPU_NUM --config-file /path/to/config --eval-only MODEL.WEIGHTS /path/to/ckpt
要在Objects365上评估预训练模型(跨数据集评估),请运行
python train_net.py --num-gpus $GPU_NUM --config-file /path/to/config --eval-only MODEL.WEIGHTS /path/to/ckpt DATASETS.TEST "('objects365_v2_val',)" MODEL.RESET_CLS_TESTS True MODEL.TEST_CLASSIFIERS "('datasets/metadata/o365_clip_a+cnamefix.npy',)" MODEL.TEST_NUM_CLASSES "(365,)" MODEL.MASK_ON False
训练
论文中使用的训练配置列在CoDet/configs中。
大多数配置文件需要预训练模型权重进行初始化(在配置文件中由MODEL.WEIGHTS指示)。
请在训练之前训练或下载相应的预训练模型,并将它们放在CoDet/models/下。
| 名称 | 模型 |
|---|---|
| resnet50_miil_21k.pkl | 来自MIIL的ResNet50-21K预训练 |
| swin_base_patch4_window7_224_22k.pkl | 来自Swin-Transformer的SwinB-21K预训练 |
| eva02_L_pt_m38m_p14to16.pt | 来自EVA的EVA02-L混合38M预训练 |
| BoxSup_OVCOCO_CLIP_R50_1x.pth | 来自Detic的ResNet50 COCO基类预训练 |
| BoxSup-C2_Lbase_CLIP_R5021k_640b64_4x.pth | 来自Detic的ResNet50 LVIS基类预训练 |
| BoxSup-C2_Lbase_CLIP_SwinB_896b32_4x.pth | 来自Detic的SwinB LVIS基类预训练 |
要在单个节点上进行训练,请运行
python train_net.py --num-gpus $GPU_NUM --config-file /path/to/config
注意:默认情况下,我们使用8个V100进行ResNet50或SwinB的训练,使用16个A100进行EVA02-L的训练。 如果你使用不同数量的GPU进行训练,请记得相应地重新调整学习率。
引用
如果您发现这个仓库对您的研究有用,请考虑引用我们的论文:
@inproceedings{ma2023codet,
title={CoDet: Co-Occurrence Guided Region-Word Alignment for Open-Vocabulary Object Detection},
author={Ma, Chuofan and Jiang, Yi and Wen, Xin and Yuan, Zehuan and Qi, Xiaojuan},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}
致谢
许可证
本项目采用Apache License 2.0许可 - 详情请参阅LICENSE文件。











