
 访问官网
访问官网 Github
Github 文档
文档xxHash - 极速哈希算法
xxHash是一种极速哈希算法,处理速度可达内存速度极限。 代码具有高度可移植性,在所有平台(小端/大端)上生成相同的哈希值。 该库包含以下算法:
- XXH32:使用32位运算生成32位哈希值
- XXH64:使用64位运算生成64位哈希值
- XXH3(自v0.8.0起):使用向量化运算生成64位或128位哈希值。 128位变体称为XXH128。
所有变体均成功通过SMHasher测试套件,该套件用于评估哈希函数的质量(碰撞、分散性和随机性)。 此外还提供了额外的测试,更全面地评估64位哈希的速度和碰撞特性。
| 分支 | 状态 |
|---|---|
| release |  |
| dev |  |
基准测试
基准测试参考系统使用Intel i7-9700K处理器,运行Ubuntu x64 20.04。
开源基准测试程序使用clang v10.0编译器和-O3标志编译。
| 哈希名称 | 位宽 | 带宽 (GB/s) | 小数据速度 | 质量 | 备注 |
|---|---|---|---|---|---|
| XXH3 (SSE2) | 64 | 31.5 GB/s | 133.1 | 10 | |
| XXH128 (SSE2) | 128 | 29.6 GB/s | 118.1 | 10 | |
| RAM顺序读取 | N/A | 28.0 GB/s | N/A | N/A | 供参考 |
| City64 | 64 | 22.0 GB/s | 76.6 | 10 | |
| T1ha2 | 64 | 22.0 GB/s | 99.0 | 9 | 碰撞略差 |
| City128 | 128 | 21.7 GB/s | 57.7 | 10 | |
| XXH64 | 64 | 19.4 GB/s | 71.0 | 10 | |
| SpookyHash | 64 | 19.3 GB/s | 53.2 | 10 | |
| Mum | 64 | 18.0 GB/s | 67.0 | 9 | 碰撞略差 |
| XXH32 | 32 | 9.7 GB/s | 71.9 | 10 | |
| City32 | 32 | 9.1 GB/s | 66.0 | 10 | |
| Murmur3 | 32 | 3.9 GB/s | 56.1 | 10 | |
| SipHash | 64 | 3.0 GB/s | 43.2 | 10 | |
| FNV64 | 64 | 1.2 GB/s | 62.7 | 5 | 雪崩效应差 |
| Blake2 | 256 | 1.1 GB/s | 5.1 | 10 | 加密级 |
| SHA1 | 160 | 0.8 GB/s | 5.6 | 10 | 加密级但已破解 |
| MD5 | 128 | 0.6 GB/s | 7.8 | 10 | 加密级但已破解 |
注1:小数据速度是对算法在小数据上效率的粗略评估。更详细的分析请参考下一段。
注2:某些算法的速度快于RAM。在这种情况下,只有当输入已在CPU缓存(L3或更好)中时,它们才能达到最大速度潜力。否则,它们会受限于RAM速度。
小数据
大数据的性能只是整体情况的一部分。 哈希在哈希表和布隆过滤器等结构中也非常有用。 在这些用例中,经常需要对大量小数据(从几个字节开始)进行哈希处理。 算法在这些场景下的性能可能会有很大不同,因为算法的某些部分(如初始化或最终处理)会成为固定开销。 分支预测失误的影响也会变得更加明显。
XXH3的设计目标是在长输入和短输入上都能有出色的性能, 这可以从下图中观察到:
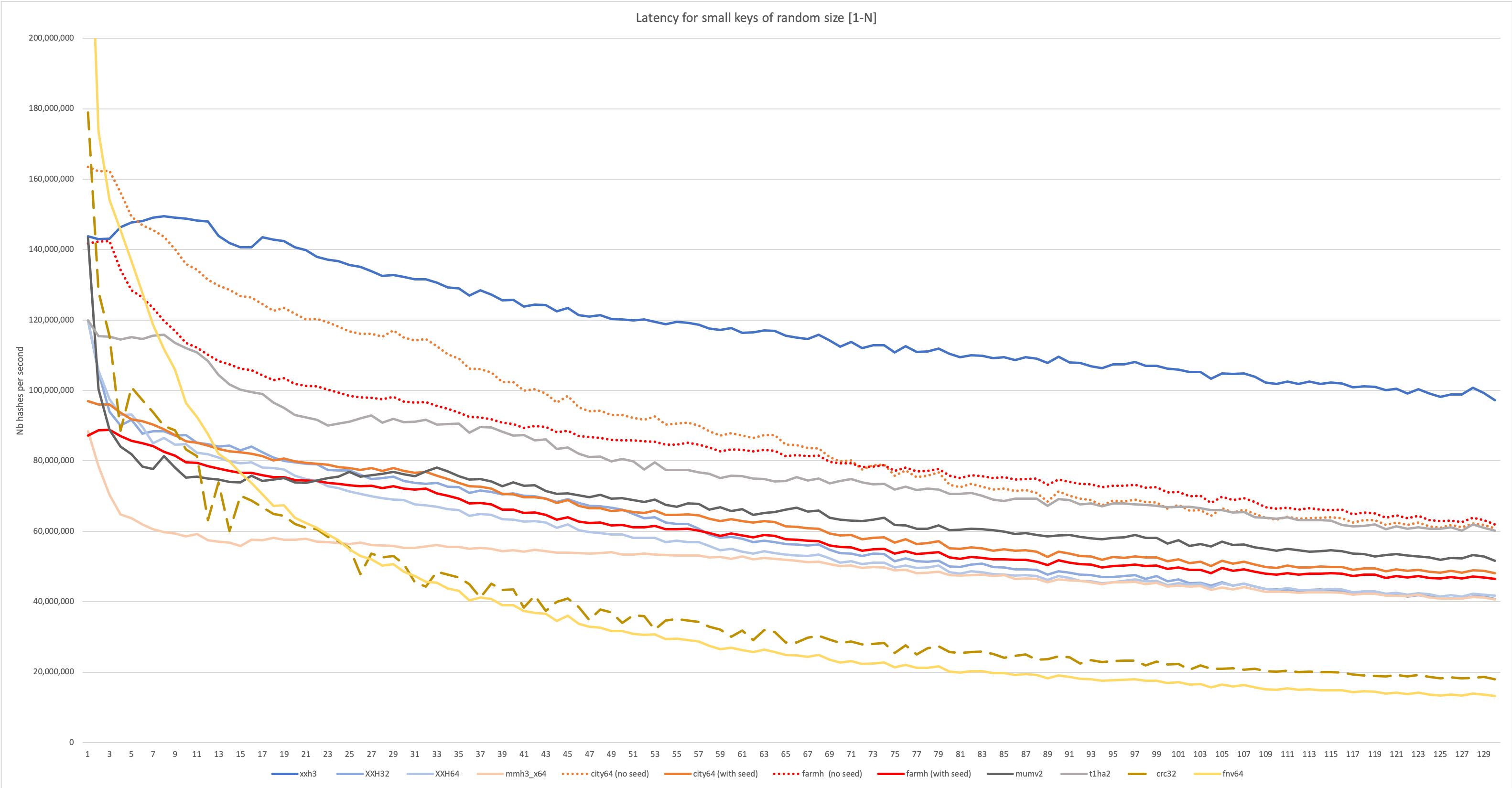
更详细的分析请访问wiki: https://github.com/Cyan4973/xxHash/wiki/Performance-comparison#benchmarks-concentrating-on-small-data-
质量
速度并不是唯一重要的属性。 生成的哈希值必须具备出色的分散性和随机性, 这样其任何子部分都可以最大程度地分散表格或索引, 并将冲突减少到理论最小水平,遵循生日悖论。
xxHash已经通过Austin Appleby出色的SMHasher测试套件进行了测试,
并通过了所有测试,确保了合理的质量水平。
它还通过了来自SMHasher的较新分支的扩展测试,包括额外的场景和条件。
最后,xxHash提供了自己的大规模冲突测试器, 能够生成和比较数十亿个哈希值,以测试64位哈希算法的极限。 在这方面,xxHash也表现出良好的结果,符合生日悖论。 更详细的分析记录在wiki中。
构建修饰符
以下宏可以在编译时设置,以修改libxxhash的行为。它们通常默认是禁用的。
XXH_INLINE_ALL:使所有函数内联,实现直接包含在xxhash.h中。 内联函数有利于提高速度,特别是对于小键值。 当键的长度表示为_编译时常量_时,它_极其有效_, 观察到的性能提升在+200%范围内。 详情请参见这篇文章。XXH_PRIVATE_API:与XXH_INLINE_ALL效果相同。仍然可用于遗留支持。 这个名称强调XXH_*符号名称不会被导出。XXH_STATIC_LINKING_ONLY:允许访问内部状态声明,用于静态分配。 由于ABI更改的风险,与动态链接不兼容。XXH_NAMESPACE:用XXH_NAMESPACE的值为所有符号添加前缀。 此宏只能使用可编译的字符集。 在xxHash源代码多次包含的情况下,用于避免符号命名冲突。 客户端应用程序仍使用常规函数名, 因为符号通过xxhash.h自动转换。XXH_FORCE_ALIGN_CHECK:当输入对齐时使用更快的直接读取路径。 在无法从未对齐地址加载内存的架构上,当要哈希的输入恰好在32位或64位边界对齐时,此选项可能导致显著的性能改进。 在具有良好未对齐内存访问性能的平台上(对齐和未对齐访问使用相同指令)略有不利。 此选项在x86、x64和aarch64上自动禁用,在所有其他平台上启用。XXH_FORCE_MEMORY_ACCESS:默认方法0使用可移植的memcpy()表示法。 方法1使用gcc特定的packed属性,可为某些目标提供更好的性能。 方法2强制未对齐读取,这不符合标准,但有时可能是提取更好读取性能的唯一方法。 方法3使用字节移位操作,这对于不内联memcpy()的旧编译器或没有字节交换指令的大端系统最佳。XXH_CPU_LITTLE_ENDIAN:默认情况下,字节序由在编译时解析的运行时测试确定。 如果编译器无法简化运行时测试,可能会影响性能。 可以跳过自动检测,通过将此宏设置为1来简单声明架构为小端。 将其设置为0表示大端。XXH_ENABLE_AUTOVECTORIZE:根据CPU矢量能力和编译器版本,可能会为XXH32和XXH64触发自动矢量化。 注意:自动矢量化在较新版本的clang中更容易触发。 对于XXH32,SSE4.1或等效(NEON)就足够了,而XXH64需要AVX512。 不幸的是,自动矢量化通常会降低XXH性能。 因此,xxhash源代码默认尝试防止自动矢量化。 但是,系统在不断发展,这个结论并非一成不变。 例如,有报告称最新的Zen4 CPU更有可能通过矢量化提高性能。 因此,如果您更喜欢或想测试矢量化代码,可以启用此标志: 它将移除防止矢量化的保护代码,从而使XXH32和XXH64更有可能被自动矢量化。XXH32_ENDJMP:将XXH32的多分支最终阶段切换为单个跳转。 这通常不利于性能,特别是在哈希随机大小的输入时。 但根据具体架构和编译器,跳转可能在小输入上提供略微更好的性能。默认禁用。XXH_IMPORT:MSVC特定:只应为动态链接定义,因为它可以防止链接错误。XXH_NO_STDLIB:禁用调用<stdlib.h>函数,特别是malloc()和free()。libxxhash的XXH*_createState()将始终失败并返回NULL。 但一次性哈希(如XXH32())或使用静态分配状态的流式处理 仍按预期工作。 此构建标志对于没有动态分配的嵌入式环境很有用。XXH_DEBUGLEVEL:当设置为任何大于等于1的值时,启用assert()语句。 这会(略微)降低执行速度,但可能有助于在调试会话中发现错误。
二进制大小控制
XXH_NO_XXH3:从生成的二进制中移除与XXH3(64位和128位)相关的符号。XXH3是libxxhash大小的最大贡献者, 因此对于不使用XXH3的应用程序来说,这对减小二进制大小很有用。XXH_NO_LONG_LONG:移除依赖64位long long类型的算法的编译, 包括XXH3和XXH64。 只会编译XXH32。 对于没有64位支持的目标(架构和编译器)很有用。XXH_NO_STREAM:禁用流式API,将库限制为仅单次使用变体。XXH_NO_INLINE_HINTS:默认情况下,xxHash使用__attribute__((always_inline))和__forceinline来提高性能,但会增加代码大小。 将此宏定义为1会将所有内部函数标记为static,允许编译器决定是否内联函数。 这在优化最小二进制大小时非常有用, 在GCC和Clang上使用-O0、-Os、-Oz或-fno-inline编译时会自动定义。 根据编译器和架构的不同,这也可能提高性能。XXH_SIZE_OPT:0:默认,优化速度1:-Os和-Oz的默认设置:禁用一些速度优化以进行大小优化2:使代码尽可能小,性能可能会受影响
XXH3特有的构建修饰符
XXH_VECTOR:手动选择向量指令集(默认:在编译时自动选择)。可用的指令集有XXH_SCALAR、XXH_SSE2、XXH_AVX2、XXH_AVX512、XXH_NEON和XXH_VSX。编译器可能需要额外的标志以确保正确支持(例如,x86_64上的gcc需要-mavx2支持AVX2,或-mavx512f支持AVX512)。XXH_PREFETCH_DIST:选择预取距离。用于特定硬件平台的底层适配。仅适用于XXH3。XXH_NO_PREFETCH:禁用预取。某些平台或情况下不使用预取可能表现更好。仅适用于XXH3。
Makefile变量
使用make编译命令行界面xxhsum时,还可以设置以下环境变量:
DISPATCH=1:使用xxh_x86dispatch.c,在运行时根据本地主机自动选择scalar、sse2、avx2或avx512指令集。此选项仅适用于x86/x64系统。XXH_1ST_SPEED_TARGET:为基准模式下的第一次速度测试选择初始速度目标,以MB/s表示。基准测试将在后续迭代中调整目标,但第一次测试是"盲目"针对这个速度进行的。目前保守设置为10 MB/s,以支持非常慢(模拟)的平台。NODE_JS=1:使用Emscripten为Node.js编译xxhsum时,这会链接NODERAWFS库以实现不受限制的文件系统访问,并修补isatty使命令行工具能正确检测终端。这会使二进制文件专用于Node.js。
构建xxHash - 使用vcpkg
你可以使用vcpkg依赖管理器下载和安装xxHash:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install xxhash
vcpkg中的xxHash端口由Microsoft团队成员和社区贡献者保持更新。如果版本过时,请在vcpkg仓库上创建一个问题或拉取请求。
示例
最简单的示例调用xxhash的64位变体作为一次性函数,从单个缓冲区生成哈希值,并从C/C++程序调用:
#include "xxhash.h"
(...)
XXH64_hash_t hash = XXH64(buffer, size, seed);
}
流式变体更复杂,但可以逐步提供数据:
#include "stdlib.h" /* abort() */
#include "xxhash.h"
XXH64_hash_t calcul_hash_streaming(FileHandler fh)
{
/* 创建哈希状态 */
XXH64_state_t* const state = XXH64_createState();
if (state==NULL) abort();
size_t const bufferSize = SOME_SIZE;
void* const buffer = malloc(bufferSize);
if (buffer==NULL) abort();
/* 用选定的种子初始化状态 */
XXH64_hash_t const seed = 0; /* 或任何其他值 */
if (XXH64_reset(state, seed) == XXH_ERROR) abort();
/* 用输入数据填充状态,任意大小,任意次数 */
(...)
while ( /* 还有数据 */ ) {
size_t const length = get_more_data(buffer, bufferSize, fh);
if (XXH64_update(state, buffer, length) == XXH_ERROR) abort();
(...)
}
(...)
/* 生成最终哈希值 */
XXH64_hash_t const hash = XXH64_digest(state);
/* 状态可以重复使用;但在此示例中,只是简单释放 */
free(buffer);
XXH64_freeState(state);
return hash;
}
许可证
库文件xxhash.c和xxhash.h采用BSD许可证。
工具xxhsum采用GPL许可证。
其他编程语言
除了C语言参考版本外, 得益于众多优秀贡献者的努力, xxHash还可用于许多不同的编程语言。 这些语言列表在此。
打包状态
许多发行版都捆绑了包管理器,
可以轻松安装xxhash,既有libxxhash库,
也有xxhsum命令行界面。

特别鸣谢
- Takayuki Matsuoka,又名@t-mat,创建了
xxhsum -c并在早期xxh版本中提供了巨大支持 - Mathias Westerdahl,又名@JCash,引入了
XXH64的第一个版本 - Devin Hussey,又名@easyaspi314,对
XXH3和XXH128进行了令人难以置信的低级优化











