
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

DigiRL:通过自主强化学习训练野外设备控制代理
口头报告 @ FM Wild, ICML
| 网站 | 演示 | 结果 | 论文 | 检查点 | 数据 |
预印本"DigiRL:通过自主强化学习训练野外设备控制代理"的研究代码。
Hao Bai*, Yifei Zhou*, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, Aviral Kumar
加州大学伯克利分校, 伊利诺伊大学厄巴纳-香槟分校, 谷歌 DeepMind
*贡献相同,按字母顺序排列;工作在加州大学伯克利分校完成
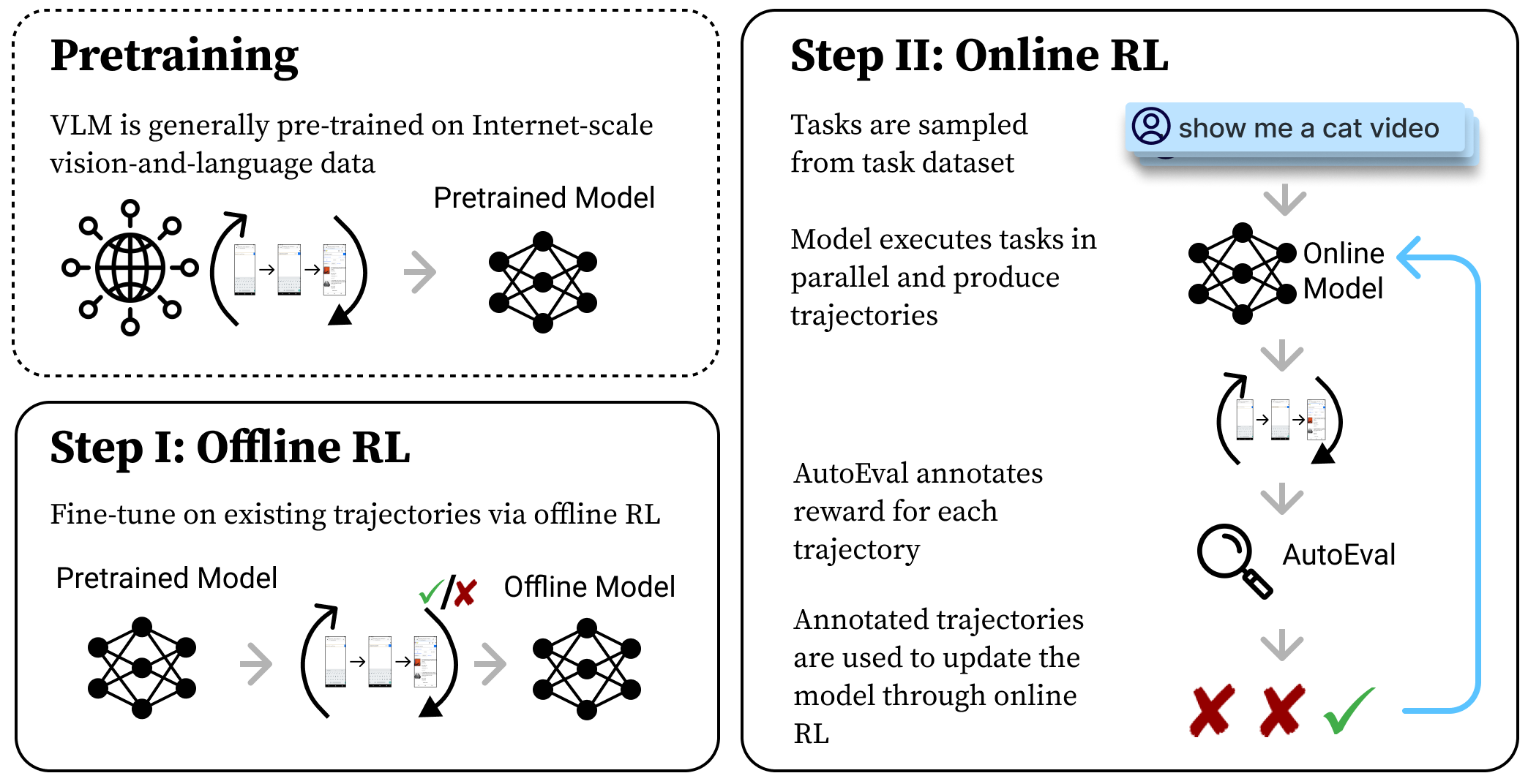
🍩 特性
环境特性
- 自适应错误处理支持。
- 多机器模拟并行支持。
- 检查点恢复支持。
- 轨迹视频录制支持。
方法特性
-
论文中提出的两种训练算法
- DigiRL(自动课程 + 双重鲁棒估计器过滤)。
- 过滤行为克隆(基于奖励的过滤)。
-
三种训练模式:
- 仅离线训练:基准方法 - 使用 AutoUI 检查点收集数据(我们已为您准备好这些数据),然后使用这些预先收集的次优轨迹进行训练。此模式仅允许使用检查点进行评估。
- 仅在线训练:传统 RL 方法 - AutoUI 检查点同时与环境交互并在线学习。此模式允许交互式训练。
- 离线到在线训练:论文中评估的最强大方法 - AutoUI 检查点首先学习预先收集的数据,然后从此检查点开始同时与环境交互并进行在线学习。此模式允许交互式训练。
-
两个代理:
-
两个野外安卓任务集:
- AitW 通用:一般浏览,打开应用程序。
- AitW 网上购物:在流行购物网站上购物。
- 如果您有好的候选项,也可以探索其他 AitW 子集或其他任务集,请在问题中提出。
-
DDP 多 GPU 训练:
- 我们支持使用
accelerate进行多 GPU 训练。如果您只有 1 个 GPU,可以关闭此功能。AutoUI 运行 DigiRL 算法只需要 12GB 的 GPU 内存,但我们提供此功能,以防您想尝试更大的模型。
- 我们支持使用
🚀 快速开始
依赖项
首先,创建一个 conda 环境并安装所有 pip 包要求。
conda create -n digirl python==3.10
conda activate digirl
git clone https://github.com/DigiRL-agent/digirl.git
cd digirl
pip install -e .
环境设置
要为 DigiRL/过滤 BC 设置与之交互的 Android 环境,请参阅环境 README。在继续之前,您应该能够通过运行此脚本查看此截图。
模型检查点和数据集
AutoUI 模型的 SFT 检查点已在此处发布,我们使用它:
只需下载 Auto-UI-Base.zip,然后解压到一个目录。
cd <path_to_autoui_dir>
wget https://huggingface.co/cooelf/Auto-UI/resolve/main/Auto-UI-Base.zip
unzip Auto-UI-Base.zip
# 等待...
ls Auto-UI-Base
# config.json pytorch_model.bin tokenizer.json training_args.bin
# generation_config.json special_tokens_map.json tokenizer_config.json
我们提供使用此 SFT 检查点预先收集的轨迹:
Google Drive 文件夹包含 4 个文件,统计数据如下(您可以使用 gdown 下载所需的检查点):
| 文件名 | 轨迹数量 | 时间步长 | 文件大小 |
|---|---|---|---|
general-off2on-zeroshot-trajectories.pt | 608 | 10 | 95.5M |
general-offline-zeroshot-trajectories.pt | 1552 | 10 | 243.9M |
webshop-off2on-zeroshot-trajectories.pt | 528 | 20 | 115.2M |
webshop-offline-zeroshot-trajectories.pt | 1296 | 20 | 297.5M |
其中 general/webshop 表示 AitW 通用/网上购物子集,off2on/offline 表示数据是用于离线学习还是离线到在线学习。为了公平比较,离线学习应使用与离线到在线学习最终使用的相似数量的数据。
将这些文件存储到一个目录中:
mkdir ~/data && cd ~/data
# 将 .pt 文件复制到此处
如果您想使用我们最终的离线到在线检查点来重现论文中的分数,也可以从 Google Drive 下载。我们发布每个环境中每种算法的第一个离线到在线检查点(论文中的 run1):
Google Drive 文件夹还包含 4 个文件:
| 文件名 | 论文中的索引 | 测试集分数 | 文件大小 |
|---|---|---|---|
general-off2on-digirl.zip | run1 | 70.8 | 1.9G |
general-off2on-filteredbc.zip | run1 | 59.4 | 1.9G |
webshop-off2on-digirl.zip | run1 | 75.0 | 1.9G |
webshop-off2on-filteredbc.zip | run1 | 55.2 | 1.9G |
您也可以通过 Huggingface 访问。
请注意,这些检查点仅允许评估,因为我们只发布了 AutoUI 检查点,而不是优化器状态。
修改配置
然后在scripts/config/main/default.yaml中更改huggingface_token、wandb_token、gemini_token等,请注意,您需要指定此文件中所有留空或标记为<username>的条目。这个配置是默认配置 - 您还需要指定子配置 - 例如,如果您想运行在线算法,您还应该检查scripts/config/main/digirl_online中需要修改的内容。欢迎自定义您的配置并尝试代码!
运行实验
修改配置后,您现在可以使用以下命令运行实验:
cd scripts
python run.py --config-path config/main --config-name digirl_online
run.py文件是程序的入口,您可以传递配置名称来运行不同的实验。配置文件位于scripts/config/目录中。
主要结果复现
要复现我们论文中表1的结果,首先按上述说明下载相应的检查点。由于训练集的结果是通过随机抽样任务获得的,我们建议复现测试结果(通过顺序抽样前96个轨迹获得)。
为此,修改eval_only.yaml配置文件及其父级'default.yaml'配置文件以进行实验设置。例如,您可以修改这些配置进行复现:
default.yaml- 设置
task_split: "test"和eval_sample_mode: "sequential" - 如果
task_set设置为webshop,别忘了将max_steps增加到20(因为webshop任务通常需要比一般任务更多的步骤才能完成)。
- 设置
eval_only.yaml- 确保
rollout_size(在default.yaml中)*eval_iterations(在eval_only.yaml中)= 96。例如,rollout_size (16) * eval_iterations (6) = 96。
- 确保
(可选)CogAgent服务器
我们设置CogAgent的方式是使用基于Gradio的API方法,这意味着您需要在服务器上设置CogAgent推理服务,然后使用我们的代码查询该API。要设置CogAgent,请参考Jiayi Pan的AutoEval项目的GitHub页面。
获取链接并在scripts/config/cogagent/default.yaml文件中进行修改。您至少需要一个具有48GB内存的GPU来托管CogAgent进行推理。
(可选)多机模拟并行
如果您想启动大规模模拟(比如同时运行超过32个模拟器),您需要多台机器同时收集轨迹。详情请参考multimachine-training README。
(可选)多GPU DDP训练
我们使用accelerate进行多GPU DDP训练。要启用此功能,您需要在accelerate配置中确定机器上的GPU数量。如果您的模型非常大,也可以进行多机DDP训练,但我们目前不支持这种方式。
要启用此功能,您唯一需要做的就是将python run.py替换为accelerate launch --config_file <config_file> run.py。以下是一个示例:
accelerate launch --config_file config/accelerate_config/default_config.yaml run.py --config-path config/main --config-name digirl_off2on
如果您成功设置了这个,应该能看到学习速度大大加快。
🌟 贡献
我们欢迎开源社区为这个项目做出贡献。如果您发明了一种算法,或者支持其他类型的基础模型,请提出PR或issue。示例主题:
- 其他算法如PPO或您发明的任何算法。
- 其他基础模型如LLaVA。
- 其他任务集如WebArena。
- 潜在的次优实现。
📄 许可证
本工作的所有内容均遵循Apache License v2.0,包括代码库、数据和模型检查点。
📚 引用
考虑引用我们的论文!
@article{bai2024digirl,
title={DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning},
author={Bai, Hao and Zhou, Yifei and Cemri, Mert and Pan, Jiayi and Suhr, Alane and Levine, Sergey and Kumar, Aviral},
journal={arXiv preprint arXiv:2406.11896},
year={2024}
}












{kind=link}