
 Github
Github 文档
文档 论文
论文

![]()
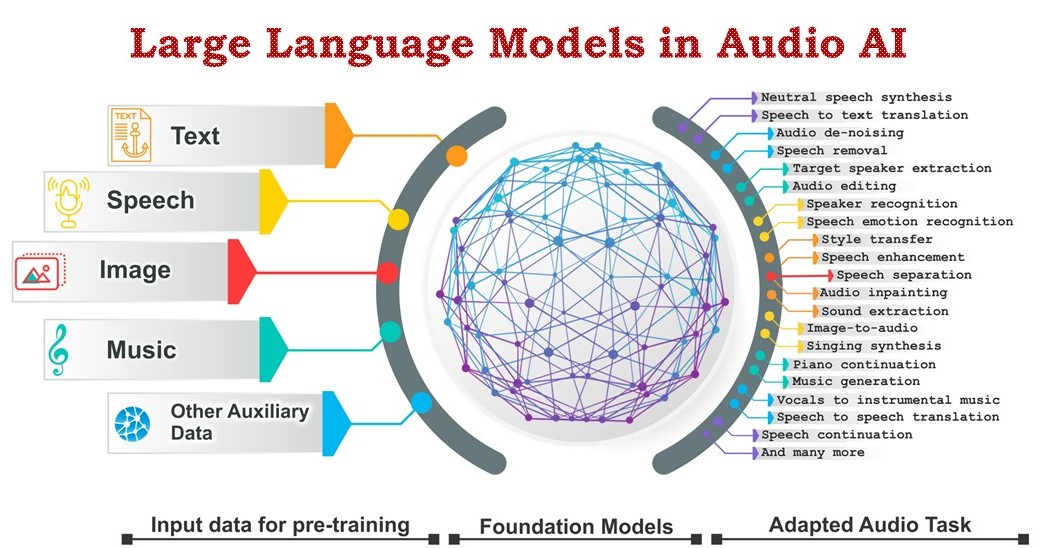
本仓库是对我们综述论文的补充:大型音频模型的火花:综述与展望。
作者:Siddique Latif,Moazzam Shoukat,Fahad Shamshad,Muhammad Usama,Yi Ren,Heriberto Cuayahuitl,Xulong Zhang,Roberto Togneri,Wenwu Wang,Bjorn Schuller。
摘要: 本综述论文全面概述了将大型语言模型应用于音频信号处理领域的最新进展和挑战。音频处理因其多样化的信号表示和广泛的来源(从人声到乐器和环境声音)而面临着不同于传统自然语言处理场景的挑战。尽管如此,以Transformer为基础架构的大型音频模型在这一领域表现出显著的效果。通过利用海量数据,这些模型在各种音频任务中展现出卓越能力,涵盖从自动语音识别和文本转语音到音乐生成等多个方面。值得注意的是,最近像SeamlessM4T这样的基础音频模型开始显示出作为通用翻译器的能力,支持多达100种语言的多种语音任务,而无需依赖单独的特定任务系统。本文深入分析了基础大型音频模型的最新方法、性能基准以及在实际场景中的应用。我们还强调了当前的局限性,并对大型音频模型领域未来的研究方向提供了见解,旨在激发进一步讨论,从而促进下一代音频处理系统的创新。

音频人工智能中的优秀大型语言模型
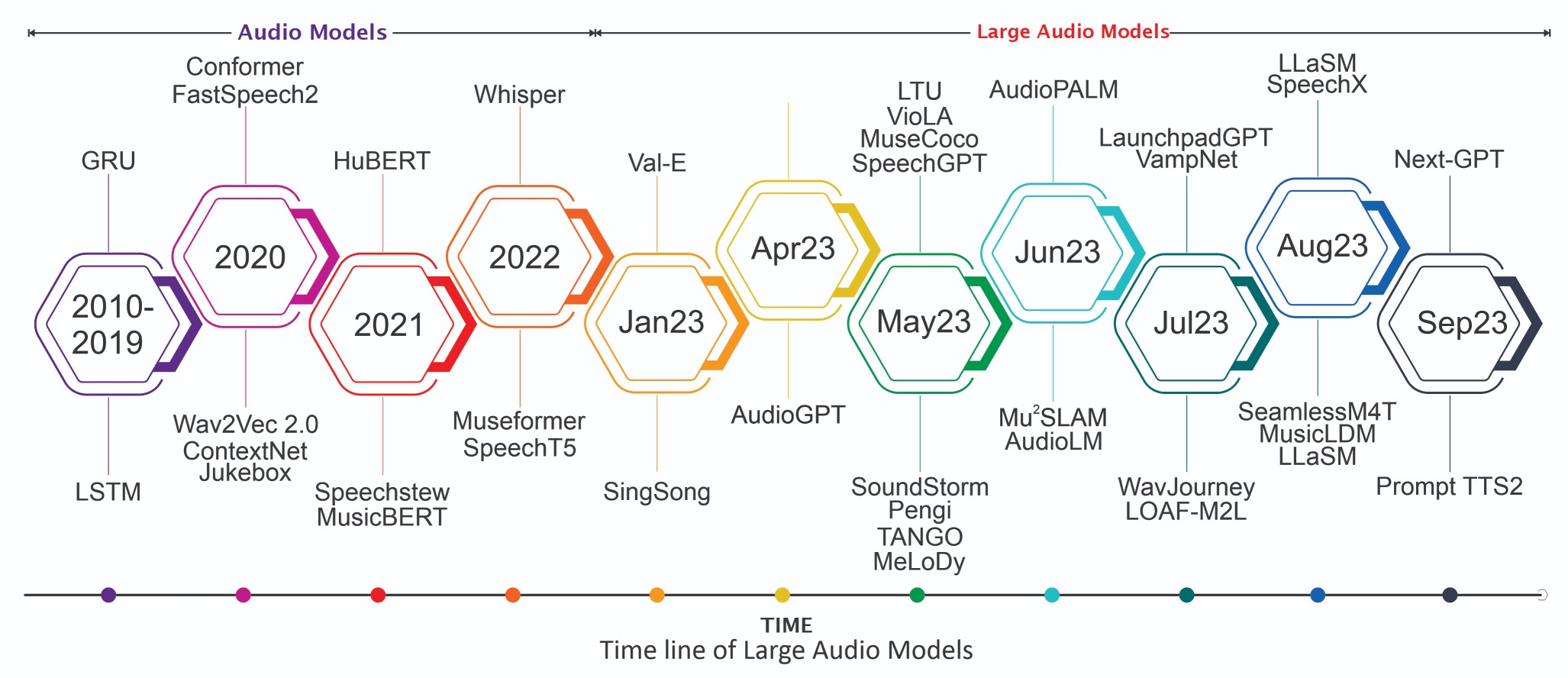
音频信号处理中优秀大型人工智能模型的精选列表,灵感来自其他优秀倡议。我们计划定期更新本页面上相关的最新论文及其开源实现。
概述
综述论文
深度学习技术在语音处理中的应用综述[2023]。
Ambuj Mehrish, Navonil Majumder, Rishabh Bharadwaj, Rada Mihalcea, Soujanya Poria
[PDF]
基于音频的应用中深度强化学习的综述[2023]。
Latif, Siddique and Cuayáhuitl, Heriberto and Pervez, Farrukh and Shamshad, Fahad and Ali, Hafiz Shehbaz and Cambria, Erik
[PDF]
大型语言模型综述[2023]。
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen
[PDF]
大型语言模型评估综述[2023]。
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, Xing Xie
[PDF]
大型语言模型的挑战与应用[2023]。
Kaddour, Jean and Harris, Joshua and Mozes, Maximilian and Bradley, Herbie and Raileanu, Roberta and McHardy, Robert
[PDF]
大型语言模型与人类对齐:一项综述[2023]。
Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi, Xingshan Zeng, Wenyong Huang, Lifeng Shang, Xin Jiang, Qun Liu
[PDF]
Segment Anything Model在视觉及其他领域的综合调查[2023]。
Zhang, Chunhui and Liu, Li and Cui, Yawen and Huang, Guanjie and Lin, Weilin and Yang, Yiqian and Hu, Yuehong
[PDF]
视觉语言模型在视觉任务中的应用:综述[2023]。
Zhang, Jingyi and Huang, Jiaxing and Jin, Sheng and Lu, Shijian
[PDF]
基础模型定义视觉新时代:综述与展望[2023]。
Awais, Muhammad and Naseer, Muzammal and Khan, Salman and Anwer, Rao Muhammad and Cholakkal, Hisham and Shah, Mubarak and Yang, Ming-Hsuan and Khan, Fahad Shahbaz
[PDF]
ChatGPT在USMLE考试中的表现:大型语言模型在AI辅助医学教育中的潜力[2023]。
Tiffany H. Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, Victor Tseng
[PDF]
ChatGPT时代的工程教育:生成式AI在教育中的前景与陷阱[2023]。
Junaid Qadir
[PDF]
ChatGPT:废话制造机还是高等教育传统评估的终结?[2023]。
Jürgen Rudolph, Samson Tan, Shannon Tan
[PDF]
通用医疗人工智能的基础模型[2023]。
Moor, Michael and Banerjee, Oishi and Abad, Zahra Shakeri Hossein and Krumholz, Harlan M and Leskovec, Jure and Topol, Eric J and Rajpurkar, Pranav
[PDF]
大型AI模型在健康信息学中的应用、挑战和未来[2023]。
Jianing Qiu, Lin Li, Jiankai Sun, Jiachuan Peng, Peilun Shi, Ruiyang Zhang, Yinzhao Dong, Kyle Lam, Frank P.-W. Lo, Bo Xiao, Wu Yuan, Dong Xu, Benny Lo
[PDF]
电子健康记录大型语言模型和基础模型的不稳定基础[2023]。
Michael Wornow, Yizhe Xu, Rahul Thapa, Birju Patel, Ethan Steinberg, Scott Fleming, Michael A. Pfeffer, Jason Fries & Nigam H. Shah
[PDF]
医学图像分析基础模型的挑战与前景[2023]。
Shaoting Zhang, Dimitris Metaxas
[PDF]
蛋白质序列嵌入模型综述[2023]。
Chau Tran, Siddharth Khadkikar, Aleksey Porollo
[PDF]
从法律角度看大型语言模型的简要综述[2023]。
Zhongxiang Sun
[PDF]
大型语言模型作为税务律师:法律能力涌现的案例研究[2023]。
John J. Nay, David Karamardian, Sarah B. Lawsky, Wenting Tao, Meghana Bhat, Raghav Jain, Aaron Travis Lee, Jonathan H. Choi, Jungo Kasai
[PDF]
决策基础模型:问题、方法和机遇[2023]。
Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, Dale Schuurmans
[PDF]
Transformer在语音处理中的应用:综述[2022]。
Siddique Latif, Aun Zaidi, Heriberto Cuayahuitl, Fahad Shamshad, Moazzam Shoukat, Junaid Qadir
[PDF]
基础模型的机遇与风险[2022]。
*Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx et. al. *
[PDF]
视觉语言预训练:基础、最新进展和未来趋势[2022]。
Zhe Gan, Linjie Li, Chunyuan Li, Lijuan Wang, Zicheng Liu, Jianfeng Gao
[PDF]
ChatGPT的善用?大型语言模型在教育领域的机遇与挑战[2022]。
Enkelejda Kasneci, Kathrin Sessler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, Stephan Krusche, Gitta Kutyniok, Tilman Michaeli, Claudia Nerdel, Jürgen Pfeffer, Oleksandra Poquet, Michael Sailer, Albrecht Schmidt, Tina Seidel, Matthias Stadler, Jochen Weller, Jochen Kuhn, Gjergji Kasneci
[PDF]
蛋白质语言模型与结构预测:联系与进展[2022]。
胡博臻, 夏俊, 郑江滨, 谭成, 黄宇飞, 徐永杰, 李Stan Z.
[PDF]
一个人类撰写了这篇法律评论文章:GPT-3与法律实践[2022]。
Amy B. Cyphert
[PDF]
Transformer与RNN在语音应用中的对比研究[2019]。
刈田茂树, 陈南鑫, 林智树, 堀高明, 稻熊裕文, 姜子严, 染谷正男, Nelson Enrique Yalta Soplin, 山本龙一, 王晓飞, 渡边慎二, 吉村贵德, 张万有
[PDF]
热门大型音频模型
SpeechGPT:赋予大型语言模型内在的跨模态会话能力。 [2023]
张东、李世民、张鑫、詹俊、王鹏宇、周亚倩、邱锡鹏
[PDF]
AudioPaLM:一个能说能听的大型语言模型。 [2023]
Paul K. Rubenstein、Chulayuth Asawaroengchai、Duc Dung Nguyen、Ankur Bapna、Zalán Borsos、Félix de Chaumont Quitry、Peter Chen等
[PDF]
AudioLM:一种语言建模方法应用于音频生成 [2023]
Zalán Borsos、Raphaël Marinier、Damien Vincent、Eugene Kharitonov、Olivier Pietquin、Matt Sharifi、Dominik Roblek、Olivier Teboul、David Grangier、Marco Tagliasacchi、Neil Zeghidour
[PDF]
倾听、思考和理解 [2023]
袁功、罗弘印、刘亚历山大、Leonid Karlinsky、James Glass
[PDF]
VioLA:用于语音识别、合成和翻译的统一编解码器语言模型 [2023]
王天瑞、周龙、张子强、吴宇、刘树杰、Yashesh Gaur、陈卓、李金玉、魏福如
[PDF]
Audiogen:文本引导的音频生成 [2022]
Felix Kreuk、Gabriel Synnaeve、Adam Polyak、Uriel Singer、Alexandre Défossez、Jade Copet、Devi Parikh、Yaniv Taigman、Yossi Adi
[PDF]
简单且可控的音乐生成 [2023]
Jade Copet、Felix Kreuk、Itai Gat、Tal Remez、David Kant、Gabriel Synnaeve、Yossi Adi、Alexandre Défossez
[PDF]
MusicLM:从文本生成音乐 [2023]
Andrea Agostinelli、Timo I. Denk、Zalán Borsos、Jesse Engel、Mauro Verzetti、Antoine Caillon、Qingqing Huang、Aren Jansen、Adam Roberts、Marco Tagliasacchi、Matt Sharifi、Neil Zeghidour、Christian Frank
[PDF]
SeamlessM4T—大规模多语言和多模态机器翻译 [2023]
Seamless Communication、Loic Barrault、Andy Chung、David Dale、Ning Dong (AI)、Paul-Ambroise Duquenne、Hady Elsahar等
[PDF]
SALMONN:探索大型语言模型的通用听觉能力 [2023]
唐长利、余文毅、孙广智、陈晓钊、谭天、李伟、陆路、马泽军、张超
[PDF][Github]
自动语音识别(ASR)
仅解码器架构在语音转文本和大型语言模型集成中的应用 [2023]
吴健、Yashesh Gaur、陈卓、周龙、朱一萌、王天瑞、李金玉、刘树杰、任博、刘林全、吴宇
[PDF]
X-LLM:将多模态视为外语来引导先进大型语言模型 [2023]
陈飞龙、韩明伦、赵浩志、张庆阳、石静、徐爽、徐波
[PDF][Github]
利用语音适配大型语言模型实现全格式端到端语音识别 [2023]
凌少石、胡宇轩、钱双贝、叶国利、钱耀、龚毅凡、Ed Lin、曾明
[PDF]
双向语言模型的语义分割改进了长形式ASR [2023]
W. Ronny Huang、张浩、Shankar Kumar、张硕寅、Tara N. Sainath
[PDF]
为大型语言模型提示语音识别能力 [2023]
Yassir Fathullah、吴春阳、Egor Lakomkin、贾俊腾、上官远、李科、郭金曦、熊文翰、Jay Mahadeokar、Ozlem Kalinli、Christian Fuegen、Mike Seltzer
[PDF]
连接语音编码器和大型语言模型用于ASR [2023]
余文毅、唐长利、孙广智、陈晓钊、谭天、李伟、陆路、马泽军、张超
[PDF]
SALMONN:探索大型语言模型的通用听觉能力 [2023]
唐长利、余文毅、孙广智、陈晓钊、谭天、李伟、陆路、马泽军、张超
[PDF][Github]
神经语音合成
调查大型语言模型的意外性对语音合成韵律的效用 [2023].
Sofoklis Kakouros, Juraj Šimko, Martti Vainio, Antti Suni
[PDF]
神经编解码语言模型是零样本文本到语音合成器 [2023].
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, Furu Wei
[PDF]
说、读和提示:最小监督下的高保真文本到语音转换 [2023].
Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, Neil Zeghidour
[PDF]
SpeechLMScore:使用语音语言模型评估语音生成 [2023].
Soumi Maiti, Yifan Peng, Takaaki Saeki, Shinji Watanabe
[PDF]
LM-VC:基于语言模型的零样本语音转换 [2023].
Zhichao Wang, Yuanzhe Chen, Lei Xie, Qiao Tian, Yuping Wang
[PDF]
使用预训练语言模型和大型语言模型评估英语作为第二语言的语音短语中断 [2023].
Zhiyi Wang, Shaoguang Mao, Wenshan Wu, Yan Xia, Yan Deng, Jonathan Tien
[PDF]
语音翻译 (ST)
SeamlessM4T—大规模多语言和多模态机器翻译 [2023].
Seamless Communication, Loic Barrault, Andy Chung, David Dale, Ning Dong (AI), Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Peng-Jen Chen, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Abinesh Ramakrishnan, Alexandre Mourachko, Amanda Kallet, Ann Lee, Anna Sun, Bapi Akula, Benjamin Peloquin, Bernie Huang, Bokai Yu, Brian Ellis, Can Balioglu, Carleigh Wood, Changhan Wang, Christophe Ropers, Cynthia Gao, Daniel Li (FAIR), Elahe Kalbassi, Ethan Ye, Gabriel Mejia Gonzalez, Hirofumi Inaguma, Holger Schwenk, Igor Tufanov, Ilia Kulikov, Janice Lam, Jeff Wang (PM - AI), Juan Pino, Justin Haaheim, Justine Kao, Prangthip Hasanti, Kevin Tran, Maha Elbayad, Marta R. Costa-jussa, Mohamed Ramadan, Naji El Hachem, Onur Çelebi, Paco Guzmán, Paden Tomasello, Pengwei Li, Pierre Andrews, Ruslan Mavlyutov, Russ Howes, Safiyyah Saleem, Skyler Wang, Somya Jain, Sravya Popuri, Tuan Tran, Vish Vogeti, Xutai Ma, Yilin Yang
[PDF]
PolyVoice:用于语音到语音翻译的语言模型 [2023].
Qianqian Dong, Zhiying Huang, Qiao Tian, Chen Xu, Tom Ko, Yunlong Zhao, Siyuan Feng, Tang Li, Kexin Wang, Xuxin Cheng, Fengpeng Yue, Ye Bai, Xi Chen, Lu Lu, Zejun Ma, Yuping Wang, Mingxuan Wang, Yuxuan Wang
[PDF]
AudioPaLM:一个能说能听的大型语言模型 [2023].
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, Dirk Padfield, James Qin, Danny Rozenberg, Tara Sainath, Johan Schalkwyk, Matt Sharifi, Michelle Tadmor Ramanovich, Marco Tagliasacchi, Alexandru Tudor, Mihajlo Velimirović, Damien Vincent, Jiahui Yu, Yongqiang Wang, Vicky Zayats, Neil Zeghidour, Yu Zhang, Zhishuai Zhang, Lukas Zilka, Christian Frank
[PDF]
SALMONN:面向大型语言模型的通用听觉能力 [2023].
Changli Tang, Wenyi Yu, Guangzhi Sun, Xiaozhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang
[PDF][Github]
其他语音应用
SpeechX:神经编解码语言模型作为多功能语音转换器 [2023].
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, Takuya Yoshioka
[PDF]
AudioGPT:理解和生成语音、音乐、声音和说话头像 [2023].
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe
[PDF]
X-LLM:通过将多模态视为外语来引导先进的大型语言模型 [2023].
Feilong Chen, Minglun Han, Haozhi Zhao, Qingyang Zhang, Jing Shi, Shuang Xu, Bo Xu
[PDF][Github]
大型语言模型能否帮助标注语音情感数据?探索新前沿 [2023].
Siddique Latif, Muhammad Usama, Mohammad Ibrahim Malik, Björn W. Schuller
[PDF]
LLaSM:大型语言和语音模型 [2023].
Yu Shu, Siwei Dong, Guangyao Chen, Wenhao Huang, Ruihua Zhang, Daochen Shi, Qiqi Xiang, Yemin Shi
[PDF]
SALMONN:面向大型语言模型的通用听觉能力 [2023].
Changli Tang, Wenyi Yu, Guangzhi Sun, Xiaozhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang
[PDF][Github]
音乐领域的大型音频模型
MusicGen: 简单且可控的音乐生成 [2023].
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez
[PDF]
JEN-1: 基于全方位扩散模型的文本引导通用音乐生成 [2023].
Peike Li, Boyu Chen, Yao Yao, Yikai Wang, Allen Wang, Alex Wang
[PDF]
VampNet: 通过掩码声学标记建模的音乐生成 [2023].
Hugo Flores Garcia, Prem Seetharaman, Rithesh Kumar, Bryan Pardo
[PDF]
使用指令微调的大语言模型和潜在扩散模型进行文本到音频生成 [2023].
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Soujanya Poria
[PDF]
WavJourney: 利用大型语言模型进行组合式音频创作 [2023].
Xubo Liu, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, Yin Cao, Qiuqiang Kong, Mark D. Plumbley, Wenwu Wang
[PDF]
MusicLDM: 使用节拍同步混合策略增强文本到音乐生成的新颖性 [2023].
Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, Shlomo Dubnov
[PDF]
探索预训练检查点在文本到音乐生成任务中的效果 [2022].
Shangda Wu, Maosong Sun
[PDF]
SingSong: 从歌唱生成音乐伴奏 [2023].
Chris Donahue, Antoine Caillon, Adam Roberts, Ethan Manilow, Philippe Esling, Andrea Agostinelli, Mauro Verzetti, Ian Simon, Olivier Pietquin, Neil Zeghidour, Jesse Engel
[PDF]
LOAF-M2L: 可唱旋律到歌词生成的措辞和格式联合学习 [2023].
Longshen Ou, Xichu Ma, Ye Wang
[PDF]
高效神经音乐生成 [2023].
Max W. Y. Lam, Qiao Tian, Tang Li, Zongyu Yin, Siyuan Feng, Ming Tu, Yuliang Ji, Rui Xia, Mingbo Ma, Xuchen Song, Jitong Chen, Yuping Wang, Yuxuan Wang
[PDF]
MuseCoco: 从文本生成符号音乐 [2023].
Peiling Lu, Xin Xu, Chenfei Kang, Botao Yu, Chengyi Xing, Xu Tan, Jiang Bian
[PDF]
LaunchpadGPT: 将语言模型作为Launchpad上的音乐可视化设计师 [2023].
Siting Xu, Yunlong Tang, Feng Zheng
[PDF]
音乐理解LLaMA: 通过问答和描述推进文本到音乐生成 [2023].
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, Ying Shan
[PDF][Github]
SALMONN: 面向大型语言模型的通用听觉能力 [2023].
Changli Tang, Wenyi Yu, Guangzhi Sun, Xiaozhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang
[PDF][Github]
Mustango: 迈向可控的文本到音乐生成 [2023].
Jan Melechovsky, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, Soujanya Poria
[PDF][Github]
音频数据集
| 标题 | 全称 | 规模 | 链接 |
|---|---|---|---|
| CommonVoice 11 | CommonVoice:大规模多语言语音语料库 | 58250个声音,共2508小时 | 下载 |
| Libri-Light | Libri-Light:有限或无监督ASR的基准 | 60000小时 | 下载 |
| Wenetspeech | Wenetspeech:用于语音识别的10000+小时多领域中文语料库 | 10000小时 | 下载 |
| Gigaspeech | Gigaspeech:不断发展的多领域ASR语料库,包含10,000小时转录音频 | 50000小时 | 下载 |
| MuST-C | MuST-C:多语言语音翻译语料库 | 3600小时 | 下载 |
| VoxPopuli | VoxPopuli:用于表示学习、半监督学习和解释的大规模多语言语音语料库 | 400k小时 | 下载 |
| CoVoST | CoVoST:大规模多语言语音到文本翻译语料库 | 2280小时 | 下载 |
| CVSS | CVSS:大规模多语言语音到语音翻译语料库 | 3909小时 | 下载 |
| EMIME | EMIME双语数据库 | - | 下载 |
| Audiocaps | Audiocaps:为野外音频生成描述 | 46000个音频 | 下载 |
| Clotho | Clotho:音频描述数据集 | 4981个音频,24905个描述 | 下载 |
| Audio set | Audio set:音频事件的本体和人工标记数据集 | 5.8k小时 | 下载 |
| Emopia | Emopia:用于情感识别和基于情感的音乐生成的多模态流行钢琴数据集 | 387个钢琴独奏音频 | 下载 |
| MetaMIDI | 构建MetaMIDI数据集:链接符号和音频音乐数据 | 436631个MIDI文件 | 下载 |
| DALI2 | 创建DALI,一个大型同步音频、歌词和音符数据集 | 7756首歌曲 | 下载 |
| MillionMIDI | 百万MIDI数据集(MMD) | 10万首歌曲 | 下载 |
| Vggsound | Vggsound:大规模音视频数据集 | 20万个视频 | 下载 |
| FSD50K | FSD50K:人工标记声音事件的开放数据集 | 51197个声音片段 | 下载 |
| Symphony | 使用置换不变语言模型生成交响乐 | 46359个MIDI文件 | 下载 |
| MusicCaps | MusicLM:从文本生成音乐 | 5521对音乐-文本配对 | 下载 |
| Jamendo | MTG-Jamendo数据集用于自动音乐标记 | 55525首曲目 | 下载 |
| MusicBench | Mustango:面向可控文本到音乐生成 | 53168首曲目 | 下载 |
引用
如果您发现此列表和调查对您的工作有用,请引用以下论文:
@article{latif2023sparks,
title={Sparks of Large Audio Models: A Survey and Outlook},
author={Latif, Siddique and Shoukat, Moazzam and Shamshad, Fahad and Usama, Muhammad and Cuay{\'a}huitl, Heriberto and Schuller, Bj{\"o}rn W},
journal={arXiv preprint arXiv:2308.12792},
year={2023}
}











