
 访问官网
访问官网 Github
Github 论文
论文TalkingGaussian:通过高斯散射实现结构持续的3D说话头像合成
这是我们ECCV 2024论文《TalkingGaussian:通过高斯散射实现结构持续的3D说话头像合成》的官方代码仓库。
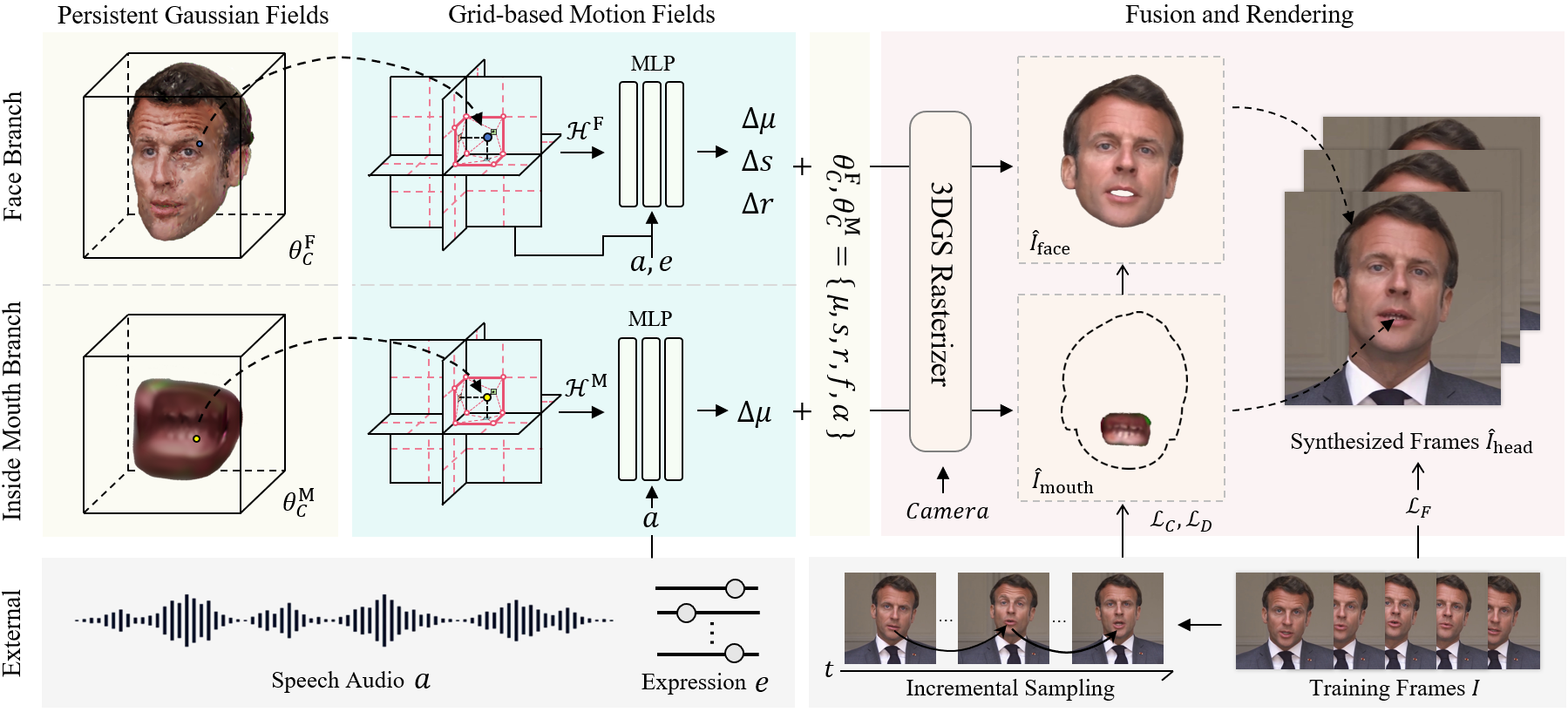
安装
在Ubuntu 18.04、CUDA 11.3、PyTorch 1.12.1上测试通过
git clone git@github.com:Fictionarry/TalkingGaussian.git --recursive
conda env create --file environment.yml
conda activate talking_gaussian
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
如果在安装diff-gaussian-rasterization或gridencoder时遇到问题,请参考gaussian-splatting和torch-ngp。
准备工作
-
准备面部解析模型和用于头部姿态估计的3DMM模型。
bash scripts/prepare.sh -
从Basel Face Model 2009下载3DMM模型:
# 1. 将01_MorphableModel.mat复制到data_util/face_tracking/3DMM/ # 2. 运行以下命令 cd data_utils/face_tracking python convert_BFM.py -
为EasyPortrait准备环境:
# 准备mmcv conda activate talking_gaussian pip install -U openmim mim install mmcv-full==1.7.1 # 下载模型权重 cd data_utils/easyportrait wget "https://n-ws-620xz-pd11.s3pd11.sbercloud.ru/b-ws-620xz-pd11-jux/easyportrait/experiments/models/fpn-fp-512.pth"
使用方法
重要提示
-
本代码仅供研究目的使用。作者不对代码的准确性、完整性或适用于特定目的做出任何明示或暗示的保证。使用本代码风险自负。
-
作者明确禁止将本代码用于任何恶意或非法活动。使用本代码即表示您同意遵守所有适用的法律和法规,并同意不使用它来伤害他人或进行任何被认为不道德或非法的行为。
-
作者不对使用本代码而导致的任何损害、损失或问题负责。
-
鼓励用户负责任且合乎道德地使用本代码。
视频数据集
这里我们提供了两个在实验中使用的视频片段,这些片段来自YouTube。请尊重原创作者的权利,并在使用时遵守YouTube的版权政策。
预处理训练视频
-
将训练视频放在
data/<ID>/<ID>.mp4下。视频必须是25FPS,所有帧都包含说话的人。 分辨率应该约为512x512,时长约1-5分钟。
-
运行脚本处理视频。
python data_utils/process.py data/<ID>/<ID>.mp4 -
获取动作单元
在OpenFace中运行
FeatureExtraction,重命名并将输出的CSV文件移动到data/<ID>/au.csv。 -
生成牙齿遮罩
export PYTHONPATH=./data_utils/easyportrait python ./data_utils/easyportrait/create_teeth_mask.py ./data/<ID>
音频预处理
在我们的论文中,我们使用DeepSpeech特征进行评估。
-
DeepSpeech
python data_utils/deepspeech_features/extract_ds_features.py --input data/<name>.wav # 保存到 data/<name>.npy
-
HuBERT
与ER-NeRF类似,HuBERT也可用。推荐用于音频不是英语的情况。
训练和测试时指定
--audio_extractor hubert。python data_utils/hubert.py --wav data/<name>.wav # 保存到 data/<name>_hu.npy
训练
# 如果资源充足,可以部分并行以加速训练。请参见脚本。
bash scripts/train_xx.sh data/<ID> output/<project_name> <GPU_ID>
测试
# 保存到 output/<project_name>/test/ours_None/renders
python synthesize_fuse.py -S data/<ID> -M output/<project_name> --eval
使用目标音频进行推理
python synthesize_fuse.py -S data/<ID> -M output/<project_name> --use_train --audio <preprocessed_audio_feature>.npy
引用
如果您发现这个代码库对您的项目有帮助,请考虑按以下方式引用:
@article{li2024talkinggaussian,
title={TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting},
author={Jiahe Li and Jiawei Zhang and Xiao Bai and Jin Zheng and Xin Ning and Jun Zhou and Lin Gu},
journal={arXiv preprint arXiv:2404.15264},
year={2024}
}
致谢
本代码基于gaussian-splatting开发,使用了simple-knn和修改后的diff-gaussian-rasterization。部分代码来自RAD-NeRF、DFRF、GeneFace和AD-NeRF。牙齿遮罩来自EasyPortrait。感谢这些优秀的项目!











