
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文⚡️AnimateLCM:通过解耦一致性学习加速个性化模型和适配器的动画生成
[论文] [项目页面 ✨] [🤗Hugging Face 演示] [预训练模型] [Civitai]
作者:王福云、黄钊阳📮、施小雨、边伟康、宋广璐、刘宇、李鸿升📮
| 示例 1 | 示例 2 | 示例 3 |
|---|---|---|
 |  |  |
如果您使用了我们工作的任何部分,请引用:
@article{wang2024animatelcm,
title={AnimateLCM: Accelerating the Animation of Personalized Diffusion Models and Adapters with Decoupled Consistency Learning},
author={Wang, Fu-Yun and Huang, Zhaoyang and Shi, Xiaoyu and Bian, Weikang and Song, Guanglu and Liu, Yu and Li, Hongsheng},
journal={arXiv preprint arXiv:2402.00769},
year={2024}
}
新闻
- [2024.05]: 🔥🔥🔥 我们发布了用于加速稳定视频扩散的训练脚本。
- [2024.03]: 😆😆😆 我们发布了用于快速图像动画的AnimateLCM-I2V和AnimateLCM-SVD。
- [2024.02]: 🤗🤗🤗 发布预训练模型权重和Huggingface演示。
- [2024.02]: 💡💡💡 技术报告已在arXiv上发布。
以下是使用示例的屏幕录像。提示词:"倒映山脉的河流"
简介
一致性模型是由杨松教授提出的一种有前景的新型生成模型家族,用于快速且高质量的生成。
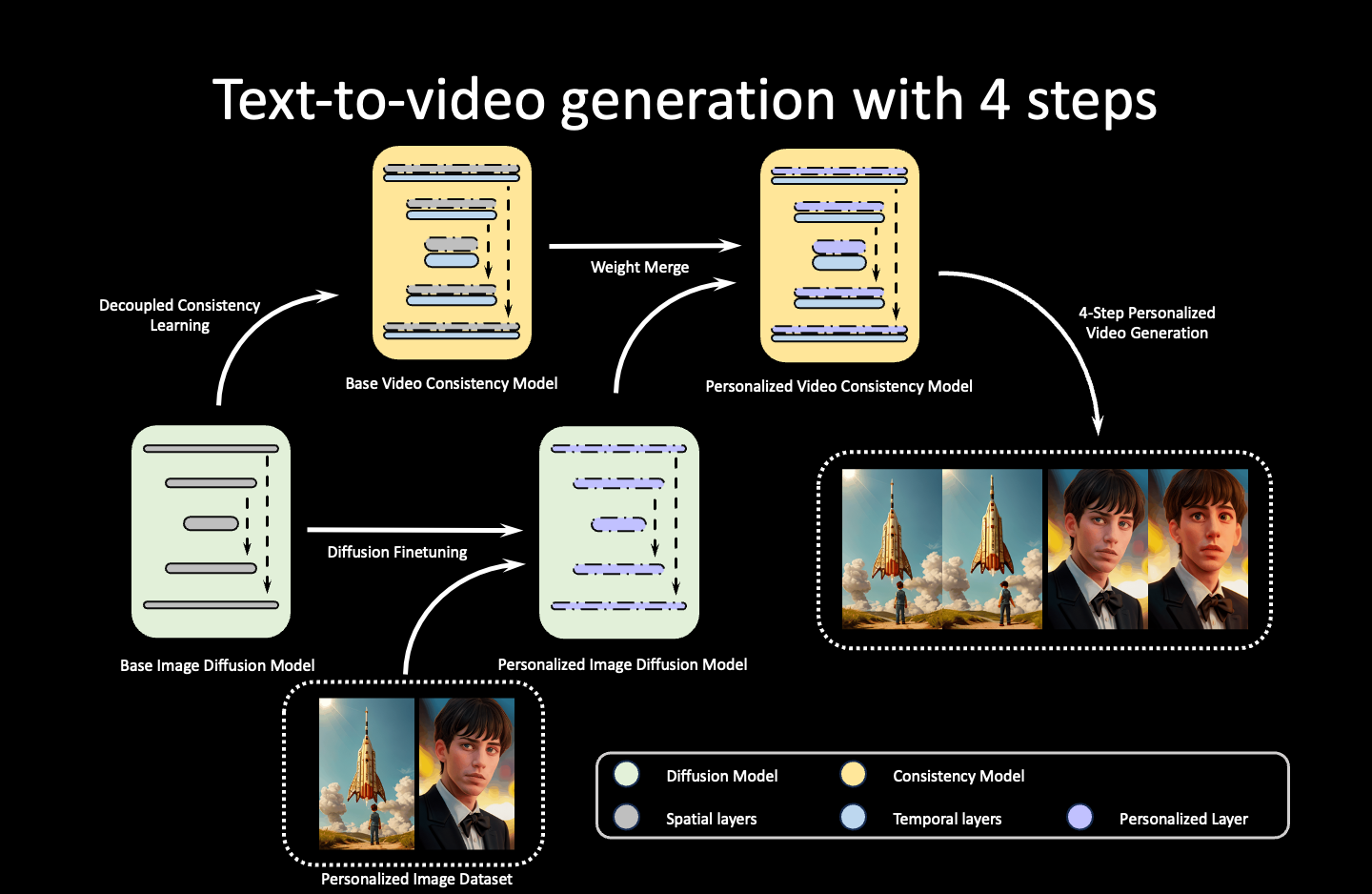
Animate-LCM是一项开创性工作,探索了遵循一致性模型的快速动画生成,能够在4次推理步骤内生成高质量的动画。
它依赖于解耦学习范式,首先学习图像生成先验,然后学习时间生成先验以实现快速采样,大大提高了训练效率。
AnimateLCM的高级工作流程可以概括为
演示
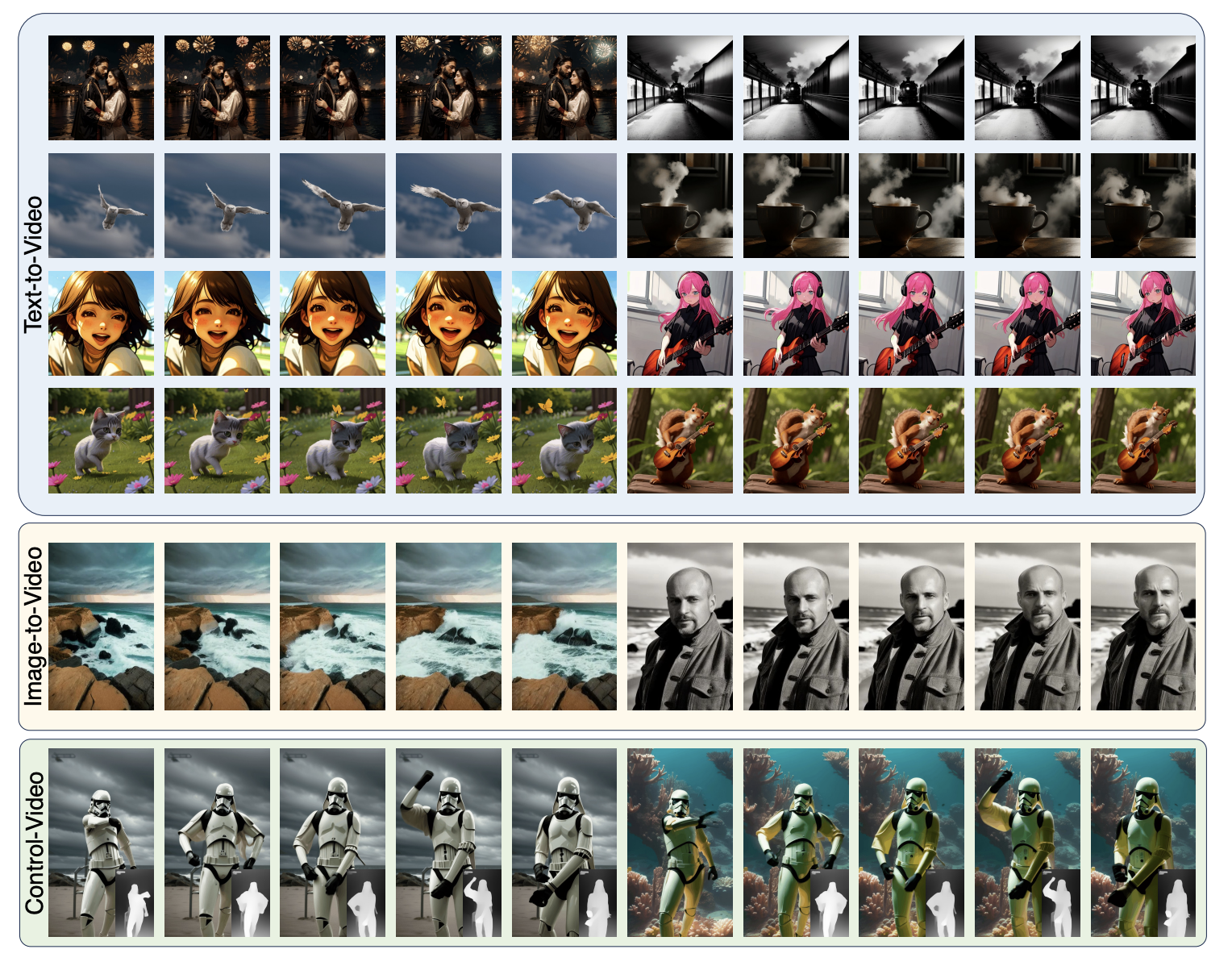
我们在项目页面上发布了许多由Animate-LCM生成的演示视频。总的来说,AnimateLCM适用于快速、文本到视频、控制到视频、图像到视频、视频到视频风格化以及长视频生成。
模型
到目前为止,我们已经发布了三个可供使用的模型
-
Animate-LCM-T2V:用于个性化视频生成的空间LoRA权重和运动模块。社区的一些尝试表明,该运动模块也与许多为LCM调优的个性化模型兼容,例如Dreamshaper-LCM。
-
AnimateLCM-SVD-xt。我提供了AnimateLCM-SVD-xt和AnimateLCM-SVD-xt 1.1,它们分别从SVD-xt和SVD-xt 1.1调优而来。它们可以用1~8步生成25帧的高分辨率图像动画。你可以在Hugging Face的演示中尝试。感谢Hugging Face团队提供的GPU资源。
-
AnimateLCM-I2V。这是一个空间LoRA权重和一个带有额外图像编码器的运动模块,用于个性化图像动画。这是我们尝试直接训练一个图像动画模型,以实现快速采样而无需任何教师模型。它可以用2~4步生成个性化图像的动画。但由于训练资源非常有限,它的稳定性不如我希望的那样(就像大多数基于Stable-Diffusion-v1-5构建的I2V模型一样,它们在生成时通常不太稳定)。
安装和使用说明
我们将animatelcm_sd15和animatelcm_svd分成两个文件夹。它们基于不同的环境。请参考README_animatelcm_sd15和README_animatelcm_svd获取使用说明。
使用技巧
-
AnimateLCM-T2V:
- 4步通常可以达到不错的效果。为了更好的质量,可以使用6~8步推理来提高生成质量。
- CFG比例应设置在1~2之间。设置CFG=1可以将采样成本减半。但通常,我更喜欢使用CFG 1.5并设置适当的负面提示词来采样,以获得更好的质量。
- 采样时将视频长度设置为16帧。这是模型训练时使用的长度。
- 这些模型应该可以以零样本方式与IP-Adapter、ControlNet和许多为Stable Diffusion调优的适配器一起使用。如果你希望获得更好的组合效果,可以尝试使用我提供的无教师自适应脚本一起调优它们。这不会影响采样速度。
-
AnimateLCM-I2V:
-
2-4步应该可以用于个性化图像动画。
-
在大多数情况下,模型不需要CFG值。只需将CFG设为1以减少推理成本。
-
我额外设置了一个"运动比例"超参数。默认设置为0.8。如果将其设置为0.0,你应该总是得到静态动画。你可以增加运动比例来获得更大的动作,但有时会导致生成失败。
-
典型的工作流程可以是:
- 使用你的个性化图像模型生成高质量图像。
- 将生成的图像作为输入,并重复使用相同的提示词进行图像动画。
- 你甚至可以进一步应用AnimateLCM-T2V来改善最终的运动质量。
-
-
AnimateLCM-SVD:
- 1-4步应该可以工作。
- SVD需要两个CFG值:
CFG_min和CFG_max。默认情况下,CFG_min设置为1。在[1, 1.5]之间稍微调整CFG_max将获得良好的结果。同样,将其设置为1以减少推理成本。 - 对于AnimateLCM-SVD-xt的其他超参数,请直接遵循原始SVD设计。
相关说明
- 🎉 AnimateLCM在ComfyUI上的教程视频:教程视频
- 🎉 AnimateLCM的ComfyUI版本:AnimateLCM-ComfyUI & ComfyUI-Reddit
比较
AnimateLCM-T2V的屏幕录制。提示词:"戴墨镜的狗"。

联系与合作
我愿意进行合作,但不接受全职实习。如果你对我的一些工作感兴趣,希望以任何形式进行合作/讨论,请随时联系我。
致谢
我要感谢**AK**宣传我们的工作,感谢Hugging Face团队在构建Gradio演示和存储模型方面提供的帮助。还要感谢Dhruv Nair在diffusers方面提供的帮助。











