
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文HumanSD
本仓库包含了ICCV2023论文的实现:
HumanSD:一种基于骨架引导的原生人体图像生成扩散模型 [项目主页] [论文] [代码] [视频] [数据]
Xuan Ju∗12, Ailing Zeng∗1, Chenchen Zhao∗2, Jianan Wang1, Lei Zhang1, Qiang Xu2
∗ 共同第一作者 1国际数字经济研究院 2香港中文大学
在这项工作中,我们提出了一种用于可控人体图像生成的原生骨架引导扩散模型HumanSD。与使用双分支扩散进行图像编辑不同,我们使用新颖的热图引导去噪损失对原始SD模型进行微调。这种策略在模型训练过程中有效且高效地增强了给定的骨架条件,同时缓解了灾难性遗忘效应。HumanSD在三个大规模的人体中心数据集上进行微调,这些数据集包含文本-图像-姿势信息,其中两个数据集是本工作中建立的。

- (a) 预训练的无姿势文本引导稳定扩散(SD)的生成结果
- (b) 作为ControlNet和我们提出的HumanSD的条件的姿势骨架图像
- (c) ControlNet的生成结果
- (d) HumanSD(我们的方法)的生成结果。ControlNet和HumanSD同时接收文本和姿势条件。
HumanSD在以下方面展现了其优势:(I)具有挑战性的姿势,(II)准确的绘画风格,(III)姿势控制能力,(IV)多人场景,以及(V)精细的细节。
目录
待办事项
新闻!!我们的论文已被ICCV2023接收!训练代码已发布。
- 发布推理代码和预训练模型
- 发布Gradio UI演示
- 公开训练数据(LAION-Human)
- 发布训练代码
模型概览
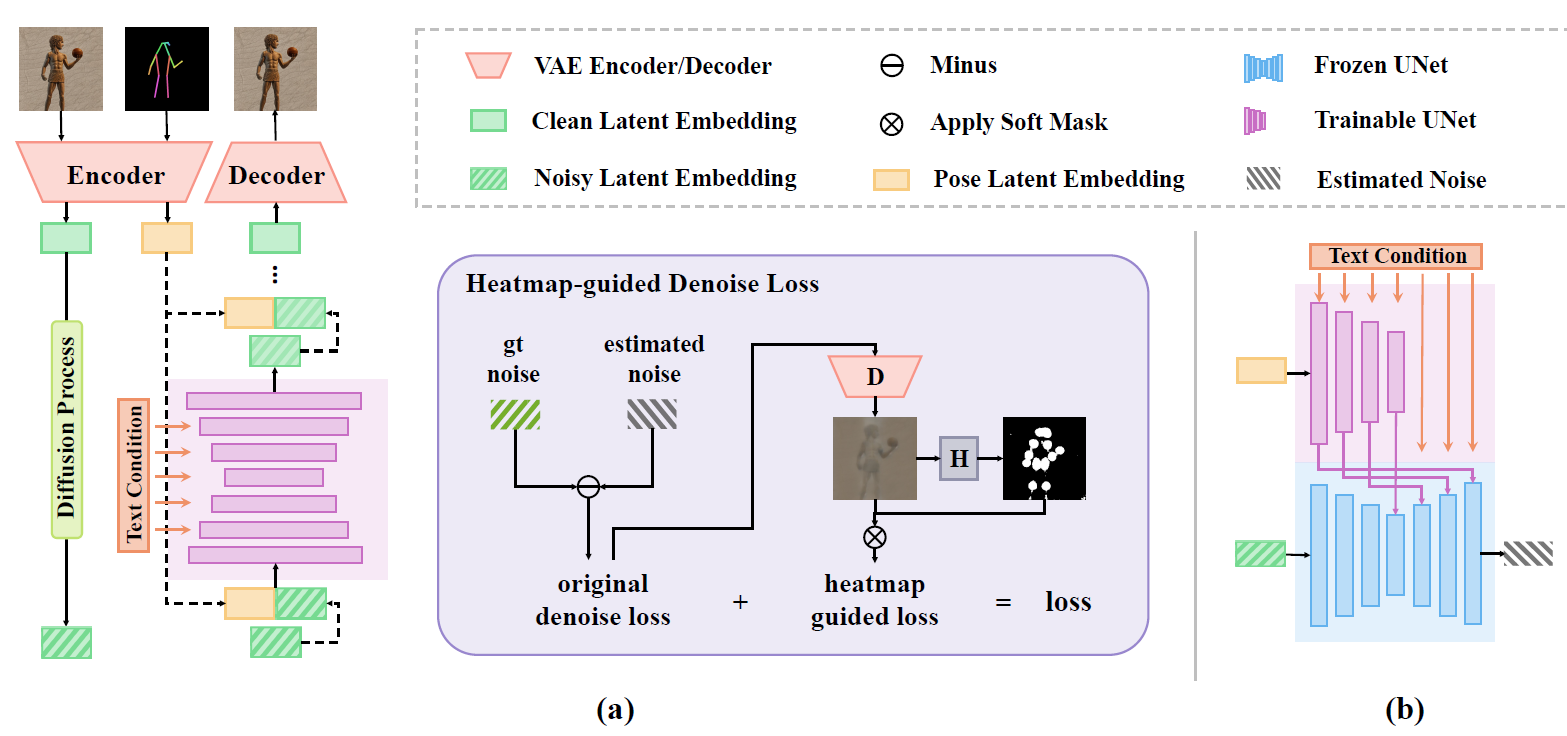
入门指南
环境要求
HumanSD已在Python 3.9的Pytorch 1.12.1上实现和测试。
克隆仓库:
git clone git@github.com:IDEA-Research/HumanSD.git
我们建议您首先按照官方说明安装pytorch。例如:
# conda
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
然后,您可以通过以下方式安装所需的包:
pip install -r requirements.txt
您还需要按照这里的说明安装MMPose。请注意,您只需将MMPose安装为Python包即可。注意:由于MMPose的更新,我们建议您安装0.29.0版本的MMPose。
模型和检查点
下载HumanSD所需的检查点,可以在这里找到。数据结构应如下所示:
|-- humansd_data
|-- checkpoints
|-- higherhrnet_w48_humanart_512x512_udp.pth
|-- v2-1_512-ema-pruned.ckpt
|-- humansd-v1.ckpt
请注意,v2-1_512-ema-pruned.ckpt应从Stable Diffusion下载。
快速演示
您可以通过命令行或gradio运行演示。
您可以通过以下命令行运行演示:
python scripts/pose2img.py --prompt "油画,女孩们在舞台上跳舞" --pose_file assets/pose/demo.npz
您还可以运行与ControlNet和T2I-Adapter的对比演示:
python scripts/pose2img.py --prompt "油画,女孩们在舞台上跳舞" --pose_file assets/pose/demo.npz --controlnet --t2i
您可以通过以下方式运行gradio演示:
python scripts/gradio/pose2img.py
我们还提供了与ControlNet和T2I-Adapter的对比,您可以在一个演示中运行所有这些方法。但您需要按照以下步骤下载相应的模型和检查点:
对比ControlNet和T2I-Adapter的结果。
(1) 您需要使用以下命令初始化ControlNet和T2I-Adapter作为子模块git submodule init
git submodule update
(2) 然后从以下位置下载检查点: a. T2I-Adapter b. ControlNet。 并将它们放入humansd_data/checkpoints
然后,运行:
python scripts/gradio/pose2img.py --controlnet --t2i
请注意,由于路径冲突,您可能需要修改T2I-Adapter中的一些代码。
例如,使用
from comparison_models.T2IAdapter.ldm.models.diffusion.ddim import DDIMSampler
而不是
from T2IAdapter.ldm.models.diffusion.ddim import DDIMSampler
数据集
您可以参考此处的代码来加载数据。
Laion-Human
您可以在这里申请访问Laion-Human。请注意,我们已经提供了姿势注释、图像的.parquet文件和映射文件,请根据.parquet下载图像。.parquet中的key是相应的图像索引。例如,00033.parquet中key=338717的图像对应于images/00000/000338717.jpg。
下载图像和姿势后,您需要解压缩文件,使其看起来像这样:
|-- humansd_data
|-- datasets
|-- Laion
|-- Aesthetics_Human
|-- images
|-- 00000.parquet
|-- 00001.parquet
|-- ...
|-- pose
|-- 00000
|-- 000000000.npz
|-- 000000001.npz
|-- ...
|-- 00001
|-- ...
|-- mapping_file_training.json
然后,您可以使用python utils/download_data.py下载所有图像。
之后,文件数据结构应如下所示:
|-- humansd_data
|-- datasets
|-- Laion
|-- Aesthetics_Human
|-- images
|-- 00000.parquet
|-- 00001.parquet
|-- ...
|-- 00000
|-- 000000000.jpg
|-- 000000001.jpg
|-- ...
|-- 00001
|-- ...
|-- pose
|-- 00000
|-- 000000000.npz
|-- 000000001.npz
|-- ...
|-- 00001
|-- ...
|-- mapping_file_training.json
如果您下载的LAION-Aesthetics是tar文件,这与我们的数据结构不同,我们建议您通过以下代码提取tar文件:
import tarfile
tar_file="00000.tar" # 00000.tar - 00286.tar
present_tar_path=f"xxxxxx/{tar_file}"
save_dir="humansd_data/datasets/Laion/Aesthetics_Human/images"
with tarfile.open(present_tar_path, "r") as tar_file:
for present_file in tar_file.getmembers():
if present_file.name.endswith(".jpg"):
print(f" image:- {present_file.name} -")
image_save_path=os.path.join(save_dir,tar_file.replace(".tar",""),present_file.name)
present_image_fp=TarIO.TarIO(present_tar_path, present_file.name)
present_image=Image.open(present_image_fp)
present_image_numpy=cv2.cvtColor(np.array(present_image),cv2.COLOR_RGB2BGR)
if not os.path.exists(os.path.dirname(image_save_path)):
os.makedirs(os.path.dirname(image_save_path))
cv2.imwrite(image_save_path,present_image_numpy)
Human-Art
文件数据结构应如下所示:
|-- humansd_data
|-- datasets
|-- HumanArt
|-- images
|-- 2D_virtual_human
|-- cartoon
|-- 000000000007.jpg
|-- 000000000019.jpg
|-- ...
|-- digital_art
|-- ...
|-- 3D_virtual_human
|-- real_human
|-- pose
|-- 2D_virtual_human
|-- cartoon
|-- 000000000007.npz
|-- 000000000019.npz
|-- ...
|-- digital_art
|-- ...
|-- 3D_virtual_human
|-- real_human
|-- mapping_file_training.json
|-- mapping_file_validation.json
训练
请注意,在开始训练之前,应下载并准备好数据集和检查点。
运行以下命令开始训练:
python main.py --base configs/humansd/humansd-finetune.yaml -t --gpus 0,1 --name finetune_humansd
如果您想在没有热图引导扩散损失的情况下进行微调以进行消融实验,可以运行以下命令:
python main.py --base configs/humansd/humansd-finetune-originalloss.yaml -t --gpus 0,1 --name finetune_humansd_original_loss
定量结果

可以通过以下方式计算指标:
python scripts/pose2img_metrics.py --outdir outputs/metrics --config utils/metrics/metrics.yaml --ckpt path_to_ckpt
定性结果
- (a) 由预训练的文本引导稳定扩散(SD)生成的图像
- (b) 作为ControlNet、T2I-Adapter和我们提出的HumanSD条件的姿势骨骼图像
- (c) 由ControlNet生成的图像
- (d) 由T2I-Adapter生成的图像
- (e) 由HumanSD (我们的方法) 生成的图像
ControlNet、T2I-Adapter和HumanSD同时接收文本和姿势条件。
自然场景





素描场景


皮影戏场景

儿童绘画场景

油画场景


水彩场景

数字艺术场景

浮雕场景

雕塑场景

引用我们
@article{ju2023humansd,
title={Human{SD}: A Native Skeleton-Guided Diffusion Model for Human Image Generation},
author={Ju, Xuan and Zeng, Ailing and Zhao, Chenchen and Wang, Jianan and Zhang, Lei and Xu, Qiang},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2023}
}
@inproceedings{ju2023human,
title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
author={Ju, Xuan and Zeng, Ailing and Wang, Jianan and Xu, Qiang and Zhang, Lei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}
致谢
- 我们的代码是在Stable Diffusion的基础上修改的,感谢所有贡献者!
- 如果没有LAION及其创建开放、大规模数据集的努力,HumanSD将无法实现。
- 感谢Stability AI的DeepFloyd团队创建了用于训练HumanSD的LAION-5B数据集子集。
- HumanSD使用了由Romain Beaumont训练的OpenCLIP。











