
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文MotionLLM:通过人体运动和视频理解人类行为

陈凌昊😎 1, 3, 卢顺麟😎 2, 3, 曾爱玲3, 张昊3, 4, 王本友2, 张瑞茂2, 张磊🤗 3
😎共同第一作者。列出顺序随机。 🤗通讯作者。
1清华大学, 2香港中文大学(深圳)数据科学学院, 3国际数字经济研究院(IDEA), 4香港科技大学


📰 新闻
- [2024-06-17]:MoVid数据集的视频数据现已在HuggingFace上发布。可以在这里快速浏览我们的数据。
- [2024-06-11]:已支持CLI模式。MotionLLM现在在🤗HuggingFace演示上使用A100 GPU运行(Twitter上的帖子)。
- [2024-05-31]:论文、演示和代码已发布(Twitter上的帖子)。
🤩 摘要
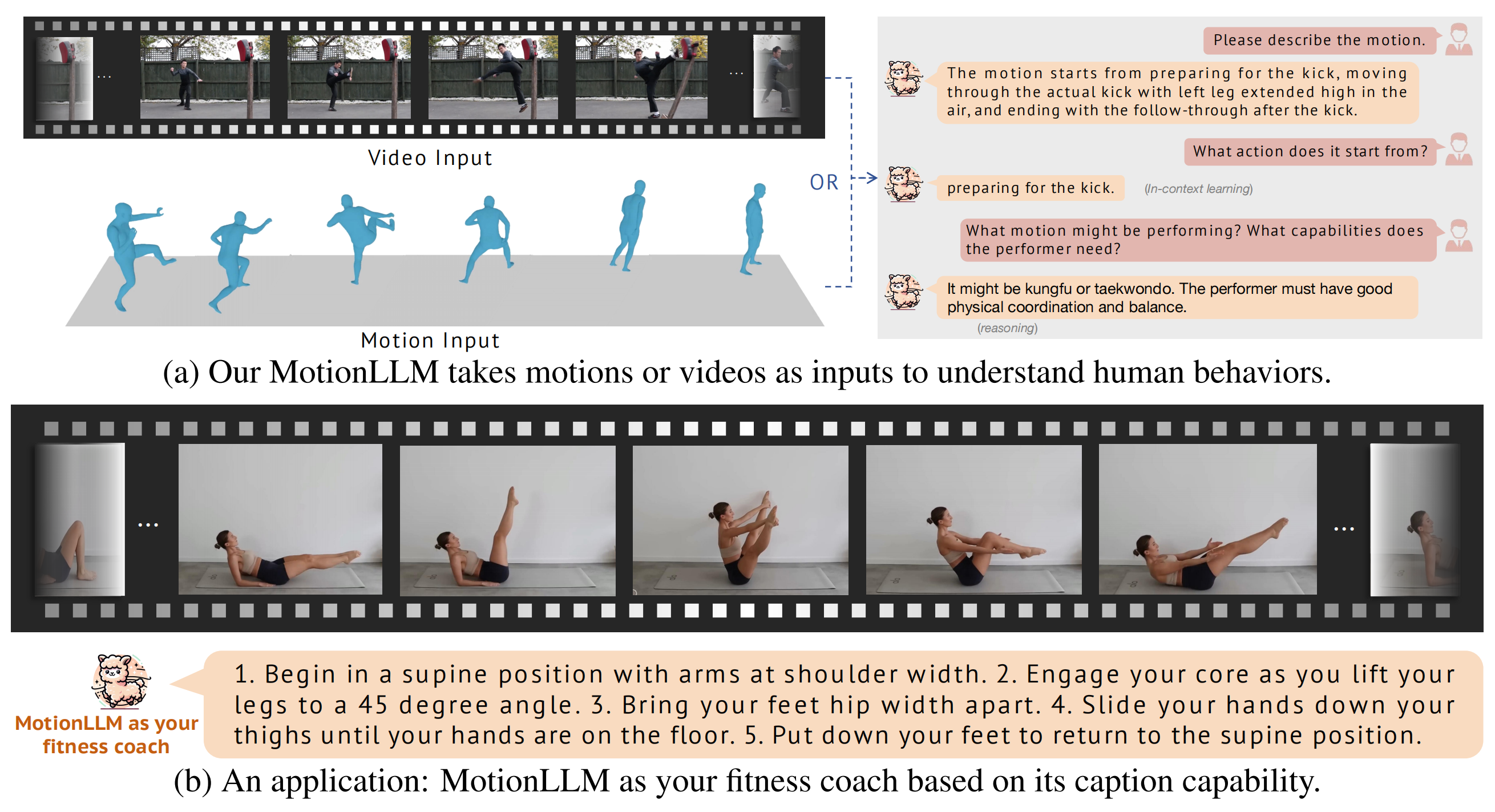
本研究深入探讨了利用大型语言模型(LLMs)的强大能力来理解多模态(即视频和动作模态)人类行为。与最近仅针对视频或仅针对动作理解设计的LLMs不同,我们认为理解人类行为需要同时从视频和动作序列(如SMPL序列)进行联合建模,以有效捕捉细微的身体部位动态和语义。鉴于此,我们提出了MotionLLM,这是一个简单而有效的人体动作理解、描述和推理框架。具体而言,MotionLLM采用统一的视频-动作训练策略,利用现有粗粒度视频-文本数据和细粒度动作-文本数据的互补优势,以获得丰富的时空洞察。此外,我们收集了一个大型数据集MoVid,包含多样化的视频、动作、描述和指令。我们还提出了MoVid-Bench,其中包含精心手动标注的数据,以更好地评估视频和动作上的人类行为理解。大量实验表明MotionLLM在描述、时空理解和推理能力方面的优越性。
🤩 亮点应用
🔧 技术方案

💻 试用
我们提供了一个简单的在线演示供您试用MotionLLM。以下是在本地机器上部署演示的指南。
步骤1:设置环境
pip install -r requirements.txt
步骤2:下载预训练模型
2.1 下载LLM
请按照[Lit-GPT](https://github.com/Lightning-AI/litgpt)的说明准备LLM模型(vicuna 1.5-7B)。这些文件将是:./checkpoints/vicuna-7b-v1.5
├── generation_config.json
├── lit_config.json
├── lit_model.pth
├── pytorch_model-00001-of-00002.bin
├── pytorch_model-00002-of-00002.bin
├── pytorch_model.bin.index.json
├── tokenizer_config.json
└── tokenizer.model
如果您有任何疑问,我们将在几天内更新更详细的说明。
我们现在发布了一个版本的MotionLLM检查点,即v1.0(在这里下载)。向陈令豪和卢顺林征集建议。
wget xxx
将它们保存在一个命名的文件夹中,并记住路径(LINEAR_V和LORA)。
2.3 运行演示
选项1: gradio演示
GRADIO_TEMP_DIR=temp python app.py --lora_path $LORA --mlp_path $LINEAR_V
如果在下载huggingface模型时遇到错误,可以尝试使用以下带有huggingface镜像的命令。
HF_ENDPOINT=https://hf-mirror.com GRADIO_TEMP_DIR=temp python app.py --lora_path $LORA --mlp_path $LINEAR_V
GRADIO_TEMP_DIR=temp将临时目录定义为./temp,用于Gradio存储数据。您可以将其更改为自己的路径。
之后,您可以打开浏览器并通过命令行输出提示访问本地主机。如果未加载,请将IP地址更改为您的本地IP地址(通过ifconfig命令)。
选项2: CLI演示
我们还提供了一个CLI演示,供您尝试MotionLLM。您可以运行以下命令来尝试MotionLLM。python cli.py --lora_path $LORA --mlp_path $LINEAR_V
在推理过程中,您可以输入视频路径和您的问题来获取答案。
# 示例
输入视频路径: xxx.mp4
您的问题: 什么xxx?
================================
这个人打算xxx。
================================
💼 待办事项
- 发布MotionLLM的CLI演示。
- 发布MotionLLM的视频演示。
- 发布MotionLLM的动作演示。
- 发布MoVid数据集和MoVid-Bench。
- 发布MotionLLM的调优说明。
💋 致谢
作者团队要向很多人表示衷心的感谢。蒋青在MoVid Bench的部分手动标注和解决MotionLLM的一些伦理问题方面提供了很大帮助。胡景程为高效训练提供了一些技术建议。刘世龙和资博嘉为LLM调优提供了一些重要的技术建议。刘嘉乐、杨文浩和钱辰来为我们完善论文提供了一些重要建议。李宏扬在图形设计方面给予了很大帮助。庞以仁在我们的密钥暂时配额不足时提供了GPT API密钥。代码基于Video-LLaVA、HumanTOMATO、MotionGPT、lit-gpt和HumanML3D。感谢所有贡献者!
📚 许可证
本代码根据IDEA LICENSE分发。请注意,我们的代码依赖于其他库和数据集,每个库和数据集都有各自的许可证,也必须遵守。
如果您有任何问题,请联系:thu [DOT] lhchen [AT] gmail [DOT] com 和 shunlinlu0803 [AT] gmail [DOT] com。
🌟 Star历史
📜 引用
@article{chen2024motionllm,
title={MotionLLM: Understanding Human Behaviors from Human Motions and Videos},
author={Chen, Ling-Hao and Lu, Shunlin and Zeng, Ailing and Zhang, Hao and Wang, Benyou and Zhang, Ruimao and Zhang, Lei},
journal={arXiv preprint arXiv:2405.20340},
year={2024}
}











