
 Github
Github Huggingface
Huggingface 文档
文档 论文
论文[NeurIPS 2023] 弱监督3D开放词汇分割
本仓库包含了论文《弱监督3D开放词汇分割》的PyTorch实现。我们的方法可以使用开放词汇文本对3D场景进行分割,无需任何分割标注。
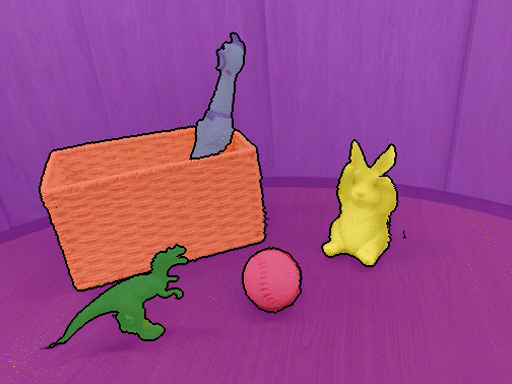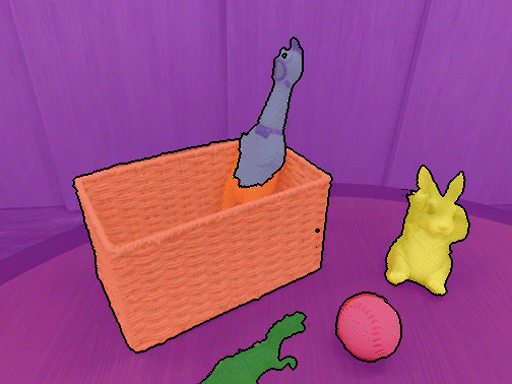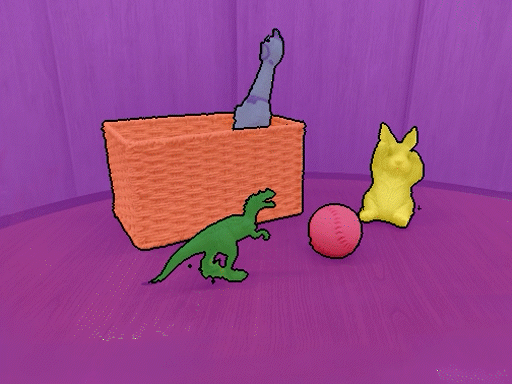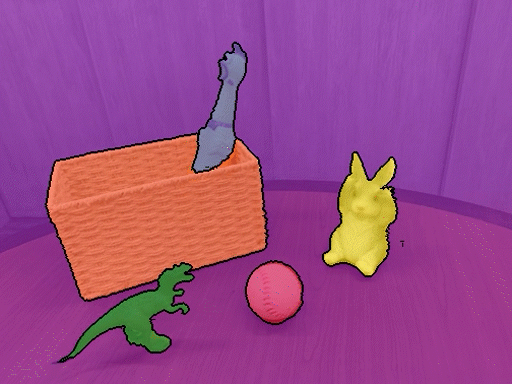



安装
在Ubuntu 20.04 + Pytorch 1.12.1上测试通过
安装环境:
conda create -n 3dovs python=3.9
conda activate 3dovs
pip install torch torchvision
pip install ftfy regex tqdm scikit-image opencv-python configargparse lpips imageio-ffmpeg kornia tensorboard
pip install git+https://github.com/openai/CLIP.git
数据集
请从此链接下载数据集并将其放在./data中。如果修改配置文件中的相应路径,也可以将数据集放在其他位置。数据集组织如下:
/data
| /scene0
| |--/images
| | |--00.png
| | |--01.png
| | ...
| |--/segmentations
| | |--classes.txt
| | |--/test_view0
| | | |--class0.png
| | | ...
| | |--/test_view1
| | | |--class0.png
| | | ...
| | ...
| |--poses_bounds.npy
| /scene1
| ...
其中images包含RGB图像,segmentations包含测试视图的分割标注,segmentations/classes.txt存储类别的文本描述,poses_bounds.npy包含由Colmap生成的相机姿态。
快速开始
我们在此链接中提供了场景的检查点。然后您可以通过以下命令测试分割:
bash scripts/test_segmentation.sh [CKPT_PATH] [CONFIG_FILE] [GPU_ID]
配置文件存储在configs中,每个文件以configs/$scene_name.txt命名。结果将保存在检查点的路径中。更多细节可以在scripts/test_segmentation.sh中找到。
数据准备
我们需要从图像块中提取CLIP特征的层次结构用于训练。 您可以通过以下方式提取CLIP特征:(请将$scene_name修改为您要提取特征的场景名称)
bash scripts/extract_clip_features.sh data/$scene_name/images clip_features/$scene_name [GPU_ID]
提取的特征将保存在clip_features/$scene_name中。
训练
1. 训练原始TensoRF
此步骤用于重建场景的TensoRF。请修改configs/resonstruction.txt中的datadir和expname以指定数据集路径和实验名称。默认情况下,我们将datadir设置为data/$scene_name,将expname设置为$scene_name。然后您可以通过以下方式训练原始TensoRF:
bash script/reconstruction.sh [GPU_ID]
重建的TensoRF将保存在log/$scene_name中。
2. 训练分割
我们在configs下提供了数据集的训练脚本,命名为$scene_name.txt。您可以通过以下方式训练分割:
bash scripts/segmentation.sh [CONFIG_FILE] [GPU_ID]
训练好的模型将保存在log_seg/$scene_name中。训练大约需要1小时30分钟,消耗约14GB的GPU内存。
故障排除
1. 加载CLIP特征非常慢
这是因为CLIP特征非常大(有512个通道)并消耗大量内存。您可以通过在配置文件中将clip_input设置为0.5或更小的值来加载更少视图的CLIP特征。通常0.5就足够获得良好的性能。
2. 提示工程
要测试您的提示是否良好,您可以在配置文件中将test_prompt设置为一个视图编号。然后您将在clip_features/clip_relevancy_maps中看到该视图中每个类别的相关性图。每个相关性图名为scale_class.png。然后您可以检查每个类别的相关性图是否良好。如果不好,您可以修改segmentations/classes.txt中的提示并再次测试。在我们的实验中,我们发现包含对象纹理和颜色的具体物体描述效果更好。
3. 自定义数据
对于自定义场景,您可以按照此链接中的恢复相机姿态部分使用Colmap生成相机姿态。
如果您的自定义数据没有标注的分割图,您可以在配置文件中将has_segmentation_maps设置为0。
4. 分割结果不佳
分割结果不佳可能是由于几何重建不佳、相机姿态错误或文本提示不准确。如果以上都不是主要原因,您可以尝试调整配置文件中的dino_neg_weight。
通常,如果分割结果与对象边界不太吻合,您可以将dino_neg_weight设置为大于0.2的值,例如0.22。如果分割出现错误,您可以将dino_neg_weight设置为小于0.2的值,例如0.18。由于dino_neg_weight鼓励模型在DINO特征相距较远时分配不同的标签,因此它越高,模型就越不稳定,但也会鼓励更锐利的边界。
待办事项
- 目前我们只支持面向前方的场景,可以通过一些坐标变换来扩展支持无界360度场景。
致谢
这个仓库主要基于TensoRF。感谢他们分享了他们出色的工作!
引用
@article{liu2023weakly,
title={Weakly Supervised 3D Open-vocabulary Segmentation},
author={Liu, Kunhao and Zhan, Fangneng and Zhang, Jiahui and Xu, Muyu and Yu, Yingchen and Saddik, Abdulmotaleb El and Theobalt, Christian and Xing, Eric and Lu, Shijian},
journal={arXiv preprint arXiv:2305.14093},
year={2023}
}











