
 访问官网
访问官网 Github
Github 文档
文档LitServe:闪电般快速部署AI模型 ⚡

高吞吐量AI模型服务引擎。 友好界面。企业级规模。
LitServe是基于FastAPI构建的可扩展AI模型部署引擎。批处理、流式处理和GPU自动缩放等功能消除了为每个模型重建FastAPI服务器的需求。
✅ 8倍更快的服务 ✅ 流式处理 ✅ 自动GPU、多GPU支持 ✅ 多模态 ✅ PyTorch/JAX/TF支持 ✅ 完全控制 ✅ 批处理 ✅ 基于Fast API构建 ✅ 自定义规格(Open AI)




快速开始
通过pip安装LitServe(或高级安装):
pip install litserve
定义服务器
这是一个hello world示例(探索真实示例):
# server.py
import litserve as ls
# 步骤1:定义模型API
class SimpleLitAPI(ls.LitAPI):
# 启动时调用一次。设置模型、数据库连接等...
def setup(self, device):
self.model = lambda x: x**2
# 将请求负载转换为模型输入。
def decode_request(self, request):
return request["input"]
# 在模型上运行推理,返回输出。
def predict(self, x):
return self.model(x)
# 将模型输出转换为响应负载。
def encode_response(self, output):
return {"output": output}
# 步骤2:启动服务器
if __name__ == "__main__":
api = SimpleLitAPI()
server = ls.LitServer(api, accelerator="auto")
server.run(port=8000)
现在通过命令行运行服务器
python server.py
LitAPI类提供完全控制和可定制性。
LitServer处理批处理、自动GPU缩放等优化。
查询服务器
使用自动生成的LitServe客户端:
python client.py
编写自定义客户端
import requests
response = requests.post(
"http://127.0.0.1:8000/predict",
json={"input": 4.0}
)
精选示例
使用LitServe部署任何类型的模型或AI服务(嵌入、LLM、视觉、音频、多模态等)。
精选示例 |
主要特点 |
性能
我们的基准测试显示,LitServe(基于FastAPI构建)能处理比FastAPI和TorchServe更多的同时请求(数值越高越好)。
完整的基准测试复现请点击这里。
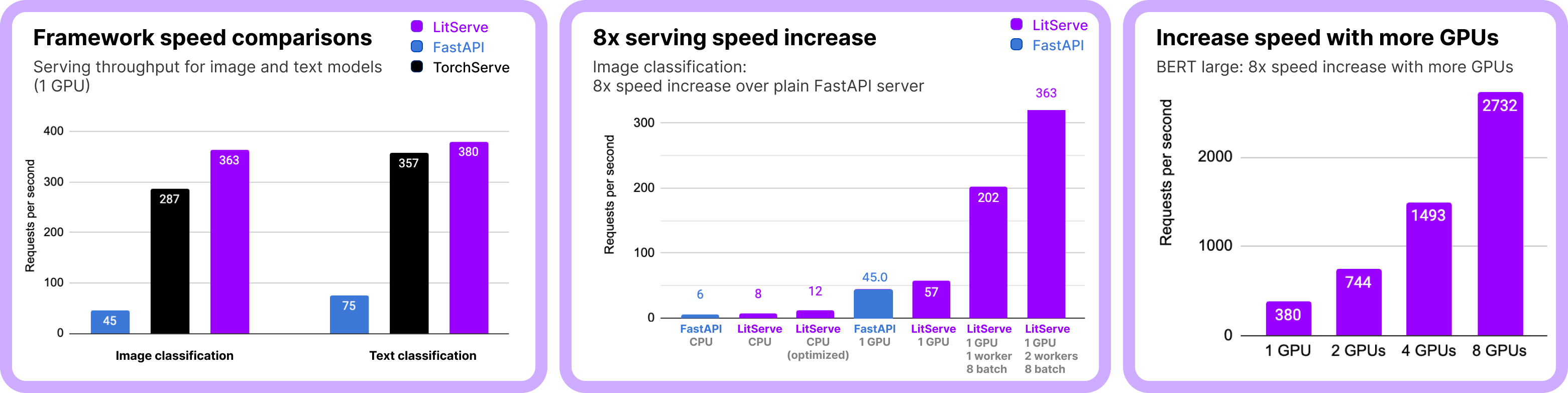
这些结果适用于图像和文本分类的机器学习任务。这种性能关系同样适用于其他机器学习任务(如嵌入、大语言模型服务、音频、分割、物体检测、摘要等)。
💡 大语言模型服务注意事项: 对于高性能的大语言模型服务(如Ollama/VLLM),请使用LitGPT或使用LitServe构建自定义的类VLLM服务器。优化措施如kv缓存(可通过LitServe实现)对于最大化大语言模型性能至关重要。
部署选项
您可以自行管理LitServe部署(只需在任何机器上运行!),或在Lightning AI上一键部署。
LitServe由Lightning AI开发,该公司提供AI模型部署的基础设施。

| 特性 | 自主管理 | Studios全托管 |
|---|---|---|
| 部署 | ✅ 自行部署 | ✅ 一键云部署 |
| 负载均衡 | ❌ | ✅ |
| 自动扩展 | ❌ | ✅ |
| 缩减至零 | ❌ | ✅ |
| 多机推理 | ❌ | ✅ |
| 身份验证 | ❌ | ✅ |
| 私有VPC | ❌ | ✅ |
| AWS, GCP | ❌ | ✅ |
| 使用您自己的云承诺 | ❌ | ✅ |
特性
LitServe支持多种先进的最新技术特性。
✅ 所有模型类型:大语言模型、视觉、时间序列等... ✅ 自动GPU扩展 ✅ 身份验证 ✅ 自动扩展 ✅ 批处理 ✅ 流式处理 ✅ 所有机器学习框架:PyTorch, Jax, Tensorflow, Hugging Face... ✅ OpenAI规范
注意: 我们的目标不是追逐每一个热点,而是支持能在最苛刻的企业部署中扩展的特性。
社区
LitServe是一个接受贡献的社区项目 - 让我们一起打造世界上最先进的AI推理引擎。
💬 在 Discord 上获取帮助
📋 许可证:Apache 2.0











