
![]()

Q-Bench:一个针对低层视觉的通用基础模型基准测试
多模态大语言模型在低层计算机视觉任务上的表现如何?

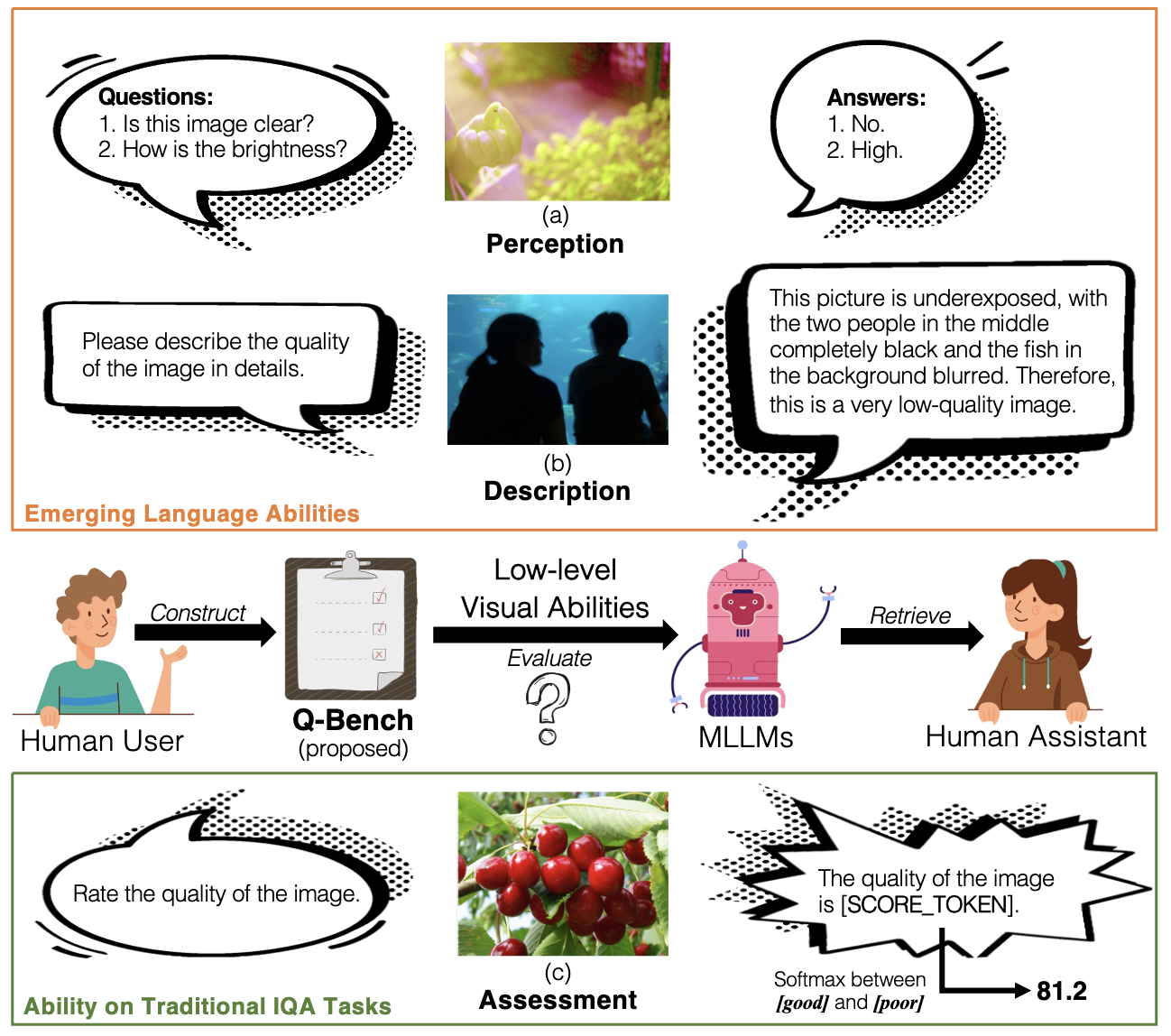
提出的Q-Bench包括低层视觉的三个领域:感知(A1)、描述(A2)和评估(A3)。
- 对于感知(A1)/描述(A2),我们收集了两个基准数据集LLVisionQA/LLDescribe。
- 我们欢迎对这两项任务进行基于提交的评估。提交的详细信息如下。
- 对于评估(A3),由于我们使用公开数据集,我们为任何人提供了一个抽象的评估代码,用于测试任意多模态大语言模型。
使用datasets API
对于Q-Bench-A1(包含多选题),我们已将其转换为HF格式数据集,可以通过datasets API自动下载和使用。请参考以下说明:
pip install datasets
Q-Bench(单图像)
from datasets import load_dataset
ds = load_dataset("q-future/Q-Bench-HF")
print(ds["dev"][0])
### {'id': 0,
### 'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,
### 'question': '这栋建筑的照明情况如何?',
### 'option0': '高',
### 'option1': '低',
### 'option2': '中等',
### 'option3': '不适用',
### 'question_type': 2,
### 'question_concern': 3,
### 'correct_choice': 'B'}
Q-Bench2(图像对)
from datasets import load_dataset
ds = load_dataset("q-future/Q-Bench2-HF")
print(ds["dev"][0])
### {'id': 0,
### 'image1': <PIL.Image.Image image mode=RGB size=4032x3024>,
### 'image2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,
### 'question': '与第一张图像相比,第二张图像的清晰度如何?',
### 'option0': '更模糊',
### 'option1': '更清晰',
### 'option2': '差不多',
### 'option3': '不适用',
### 'question_type': 2,
### 'question_concern': 0,
### 'correct_choice': 'B'}
发布
- [2024/8/8]🔥 Q-bench+(也称为Q-Bench2)的低级视觉比较任务部分刚刚被TPAMI接收!快来用Q-bench+数据集测试你的MLLM。
- [2024/8/1]🔥 Q-Bench已在VLMEvalKit上发布,快来用一行命令测试你的LMM,如`python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'。
- [2024/6/17]🔥 Q-Bench、Q-Bench2(Q-bench+)和A-Bench现已加入lmms-eval,这使得测试LMM变得更加容易!!
- [2024/6/3] 🔥 A-Bench的Github仓库已上线。想知道你的LMM是否擅长评估AI生成的图像吗?快来A-Bench上测试吧!!
- [3/1] 🔥 我们正在发布Co-instruct,迈向开放式视觉质量比较在此。更多细节即将公布。
- [2/27] 🔥 我们的工作Q-Insturct已被CVPR 2024接收,试试了解如何在低级视觉任务上指导MLLMs的细节!
- [2/23] 🔥 Q-bench+的低级视觉比较任务部分现已在Q-bench+(数据集)发布!
- [2/10] 🔥 我们正在发布扩展版Q-bench+,它用单图像和图像对在低级视觉任务上挑战MLLMs。排行榜已上线,快来查看你最喜欢的MLLMs在低级视觉能力上的表现!!更多细节即将公布。
- [1/16] 🔥 我们的工作"Q-Bench:低级视觉通用基础模型基准"被ICLR2024作为Spotlight Presentation接收。
闭源MLLMs(GPT-4V-Turbo、Gemini、Qwen-VL-Plus、GPT-4V)

我们测试了三个闭源API模型:GPT-4V-Turbo(gpt-4-vision-preview,替代了不再可用的旧版本GPT-4V结果)、Gemini Pro(gemini-pro-vision)和Qwen-VL-Plus(qwen-vl-plus)。与旧版本相比略有改进,GPT-4V仍然在所有MLLMs中表现最佳,几乎达到了初级人类的水平。Gemini Pro和Qwen-VL-Plus紧随其后,仍然优于最佳开源MLLMs(总体得分0.65)。
更新于[2024/7/18],我们很高兴发布BlueImage-GPT(闭源)的最新SOTA性能。
感知,A1-单图
| 参与者名称 | 是否 | 什么 | 如何 | 失真 | 其他 | 上下文失真 | 上下文其他 | 总体 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus (qwen-vl-plus) | 0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT (来自VIVO 新冠军) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro (gemini-pro-vision) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-Turbo (gpt-4-vision-preview) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V (旧版本) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| 人类-1-初级 | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| 人类-2-高级 | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
感知,A1-双图
| 参与者名称 | 是否 | 什么 | 如何 | 失真 | 其他 | 比较 | 联合 | 总体 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus (qwen-vl-plus) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
Qwen-VL-Max (qwen-vl-max) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT (来自VIVO 新冠军) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro (gemini-pro-vision) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V (gpt-4-vision) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| 初级人类 | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| 高级人类 | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
我们最近还评估了几个新的开源模型,并将很快发布它们的结果。
A1/A2提交指南
选项1:提交结果
步骤1:下载图像
我们现在提供两种方式下载数据集(LLVisionQA和LLDescribe)
步骤2:用您的模型进行测试
强烈建议将您的模型转换为Huggingface格式,以便顺利测试这些数据。请参考Huggingface的IDEFICS-9B-Instruct示例脚本作为示例,并修改它们以适应您的自定义模型进行测试。
请通过电子邮件haoning001@e.ntu.edu.sg以json格式提交您的结果。
选项2:提交模型
你也可以向我们提交你的模型(可以是Huggingface AutoModel或ModelScope AutoModel),以及你的自定义评估脚本。你的自定义脚本可以从适用于LLaVA-v1.5的模板脚本修改而来(用于A1/A2),以及这里的脚本(用于图像质量评估)。
如果你在中国大陆以外,请发邮件至haoning001@e.ntu.edu.sg提交你的模型。
如果你在中国大陆境内,请发邮件至zzc1998@sjtu.edu.cn提交你的模型。
A1: 感知
以下是LLVisionQA基准数据集对MLLM低级感知能力的快照。查看这里的排行榜。
![图片]
我们以MLLM的答案准确率(提供问题和所有选项)作为这里的评估指标。
A2: 描述
以下是LLDescribe基准数据集对MLLM低级描述能力的快照。查看这里的排行榜。
![图片]
我们以MLLM描述的完整性、精确性和相关性作为这里的评估指标。
A3: 评估
MLLMs能够预测IQA的定量分数,这是一项令人兴奋的能力!
方法
![图片]
预测分数
伪代码
与上面类似,只要模型(基于因果语言模型)具有以下两个方法:embed_image_and_text(允许多模态输入)和forward(用于计算logits),就可以实现模型的图像质量评估(IQA),如下所示:
from PIL import Image
from my_mllm_model import Model, Tokenizer, embed_image_and_text
model, tokenizer = Model(), Tokenizer()
prompt = "##用户: 评估图像的质量。\n" \
"##助手: 图像的质量是" ### 这一行可以根据MLLM的默认行为进行修改。
good_idx, poor_idx = tokenizer(["good","poor"]).tolist()
image = Image.open("image_for_iqa.jpg")
input_embeds = embed_image_and_text(image, prompt)
output_logits = model(input_embeds=input_embeds).logits[0,-1]
q_pred = (output_logits[[good_idx, poor_idx]] / 100).softmax(0)[0]
*注意,你可以根据你的模型的默认格式修改第二行,例如对于Shikra,"##助手: 图像的质量是"被修改为"##助手: 答案是"。如果你的MLLM首先回答"好的,我很乐意帮忙!图像质量是",那也没问题,只需将其替换到提示的第2行即可。
IDEFICS的实际代码示例
我们进一步提供了IDEFICS在IQA上的完整实现。查看这个示例了解如何使用这个MLLM运行IQA。其他MLLMs也可以以相同的方式修改以用于IQA。
使用IQA数据库计算SRCC/PLCC
我们已经准备了JSON格式的人工意见分数(MOS),用于我们基准测试中评估的七个IQA数据库。
详情请查看IQA数据库。
IQA数据库的官方结果
已移至排行榜。请点击查看详情。
联系方式
如有疑问,请联系本文的任何一位第一作者。
- Haoning Wu,
haoning001@e.ntu.edu.sg, @teowu - Zicheng Zhang,
zzc1998@sjtu.edu.cn, @zzc-1998 - Erli Zhang,
ezhang005@e.ntu.edu.sg, @ZhangErliCarl
引用
如果你觉得我们的工作有趣,欢迎引用我们的论文:
@inproceedings{wu2024qbench,
author = {Wu, Haoning and Zhang, Zicheng and Zhang, Erli and Chen, Chaofeng and Liao, Liang and Wang, Annan and Li, Chunyi and Sun, Wenxiu and Yan, Qiong and Zhai, Guangtao and Lin, Weisi},
title = {Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision},
booktitle = {ICLR},
year = {2024}
}











