
 Github
Github Huggingface
Huggingface 论文
论文中文 | English

Qwen2-Audio-7B 🤖 | 🤗 | Qwen-Audio-7B-Instruct 🤖 | 🤗 | Demo 🤖 | 🤗
📑 论文 | 📑 博客 | 💬 微信 | Discord
我们介绍了Qwen-Audio的最新进展,一个名为Qwen2-Audio的大规模音频-语言模型,它能够接受各种音频信号输入,并根据语音指令进行音频分析或直接给出文本回应。我们引入了两种不同的音频交互模式:
- 语音聊天:用户可以与Qwen2-Audio自由进行语音交互,无需文本输入;
- 音频分析:用户可以在交互过程中提供音频和文本指令进行分析;
我们发布了Qwen2-Audio系列的两个模型:Qwen2-Audio-7B和Qwen2-Audio-7B-Instruct。
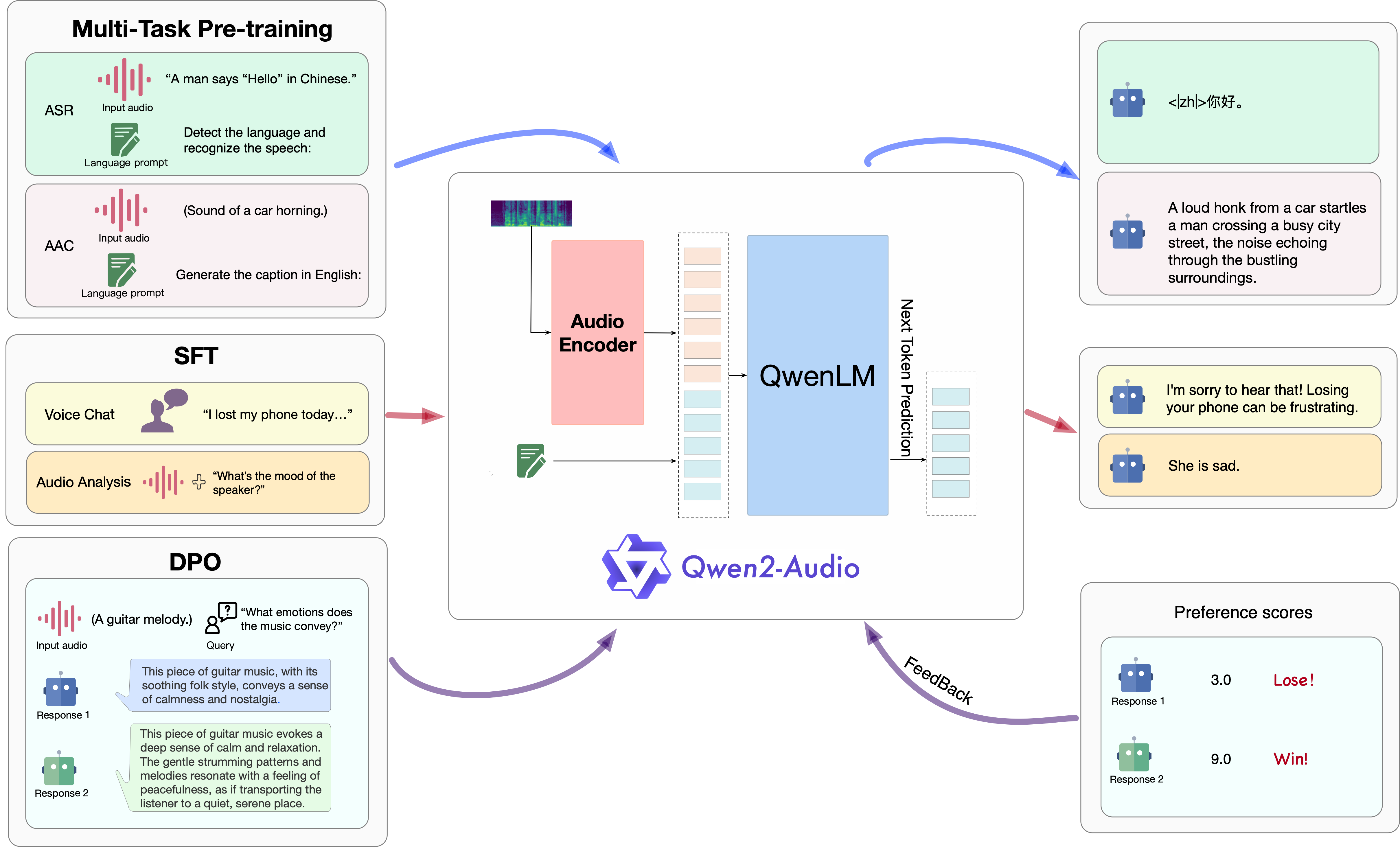
架构
Qwen2-Audio的三阶段训练过程概览。
新闻和更新
- 2024年8月9日 🎉 我们在ModelScope和Hugging Face上发布了
Qwen2-Audio-7B和Qwen2-Audio-7B-Instruct的检查点。 - 2024年7月15日 🎉 我们发布了Qwen2-Audio的论文,介绍了相关模型结构、训练方法和模型性能。详情请查看我们的报告!
- 2023年11月30日 🔥 我们发布了Qwen-Audio系列。
评估
我们在以下13个标准基准测试上评估了Qwen2-Audio的能力:
| 任务 | 描述 | 数据集 | 划分 | 指标 |
|---|---|---|---|---|
| ASR | 自动语音识别 | Fleurs | dev | test | WER |
| Aishell2 | test | |||
| Librispeech | dev | test | |||
| Common Voice | dev | test | |||
| S2TT | 语音到文本翻译 | CoVoST2 | test | BLEU |
| SER | 语音情感识别 | Meld | test | ACC |
| VSC | 声音分类 | VocalSound | test | ACC |
| AIR-Bench | 语音聊天基准 | Fisher SpokenWOZ IEMOCAP Common voice | dev | test | GPT-4评估 |
| 声音聊天基准 | Clotho | dev | test | GPT-4评估 | |
| 音乐聊天基准 | MusicCaps | dev | test | GPT-4评估 | |
| 混合音频聊天基准 | Common voice AudioCaps MusicCaps | dev | test | GPT-4评估 |
以下是总体性能:
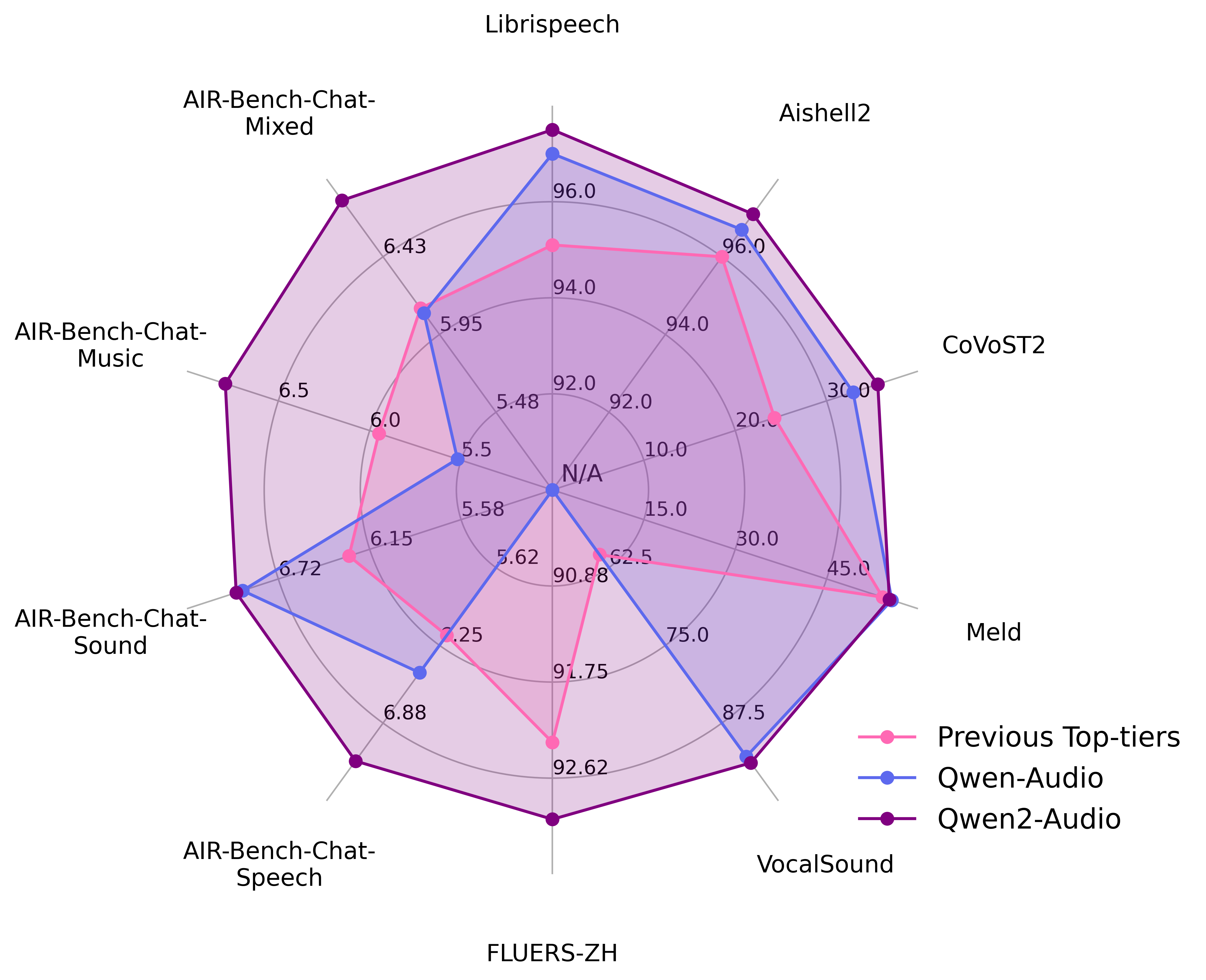
评估的详细信息如下:
(注:我们呈现的评估结果基于原始训练框架的初始模型。然而,在将框架转换为Huggingface后,分数出现了一些波动。在此,我们从论文中的初始模型结果开始,呈现我们的完整评估结果。)
| 任务 | 数据集 | 模型 | 性能 | |
|---|---|---|---|---|
| 指标 | 结果 | |||
| 语音识别 | Librispeech dev-clean | dev-other | test-clean | test-other | SpeechT5 | 词错误率 | 2.1 | 5.5 | 2.4 | 5.8 |
| SpeechNet | - | - | 30.7 | - | |||
| SLM-FT | - | - | 2.6 | 5.0 | |||
| SALMONN | - | - | 2.1 | 4.9 | |||
| SpeechVerse | - | - | 2.1 | 4.4 | |||
| Qwen-Audio | 1.8 | 4.0 | 2.0 | 4.2 | |||
| Qwen2-Audio | 1.3 | 3.4 | 1.6 | 3.6 | |||
| Common Voice 15 英语 | 中文 | 粤语 | 法语 | Whisper-large-v3 | 词错误率 | 9.3 | 12.8 | 10.9 | 10.8 | |
| Qwen2-Audio | 8.6 | 6.9 | 5.9 | 9.6 | |||
| Fleurs 中文 | Whisper-large-v3 | 词错误率 | 7.7 | |
| Qwen2-Audio | 7.5 | |||
| Aishell2 麦克风 | iOS | Android | MMSpeech-base | 词错误率 | 4.5 | 3.9 | 4.0 | |
| Paraformer-large | - | 2.9 | - | |||
| Qwen-Audio | 3.3 | 3.1 | 3.3 | |||
| Qwen2-Audio | 3.0 | 3.0 | 2.9 | |||
| 语音翻译 | CoVoST2 英德 | 德英 | 英中 | 中英 | SALMONN | BLEU | 18.6 | - | 33.1 | - |
| SpeechLLaMA | - | 27.1 | - | 12.3 | |||
| BLSP | 14.1 | - | - | - | |||
| Qwen-Audio | 25.1 | 33.9 | 41.5 | 15.7 | |||
| Qwen2-Audio | 29.9 | 35.2 | 45.2 | 24.4 | |||
| CoVoST2 西英 | 法英 | 意英 | | SpeechLLaMA | BLEU | 27.9 | 25.2 | 25.9 | |
| Qwen-Audio | 39.7 | 38.5 | 36.0 | |||
| Qwen2-Audio | 40.0 | 38.5 | 36.3 | |||
| 语音情感识别 | Meld | WavLM-large | 准确率 | 0.542 |
| Qwen-Audio | 0.557 | |||
| Qwen2-Audio | 0.553 | |||
| 声音分类 | VocalSound | CLAP | 准确率 | 0.4945 |
| Pengi | 0.6035 | |||
| Qwen-Audio | 0.9289 | |||
| Qwen2-Audio | 0.9392 | |||
| AIR-Bench | 对话基准 语音 | 声音 | 音乐 | 混合音频 | SALMONN BLSP Pandagpt Macaw-LLM SpeechGPT Next-gpt Qwen-Audio Gemini-1.5-pro Qwen2-Audio | GPT-4 | 6.16 | 6.28 | 5.95 | 6.08 6.17 | 5.55 | 5.08 | 5.33 3.58 | 5.46 | 5.06 | 4.25 0.97 | 1.01 | 0.91 | 1.01 1.57 | 0.95 | 0.95 | 4.13 3.86 | 4.76 | 4.18 | 4.13 6.47 | 6.95 | 5.52 | 6.08 6.97 | 5.49 | 5.06 | 5.27 7.18 | 6.99 | 6.79 | 6.77 |
(第二个是转换为Hugging Face后的结果)
<表格>任务数据集模型性能指标结果语音识别Librispeech
dev-clean | dev-other |
test-clean | test-otherSpeechT5词错率2.1 | 5.5 | 2.4 | 5.8SpeechNet- | - | 30.7 | -SLM-FT- | - | 2.6 | 5.0SALMONN- | - | 2.1 | 4.9SpeechVerse- | - | 2.1 | 4.4Qwen-Audio1.8 | 4.0 | 2.0 | 4.2Qwen2-Audio1.7 | 3.6 | 1.7 | 4.0Common Voice 15
英语 | 中文 | 粤语 | 法语Whisper-large-v3词错率9.3 | 12.8 | 10.9 | 10.8Qwen2-Audio8.7 | 6.5 | 5.9 | 9.6
中文Whisper-large-v3词错率7.7Qwen2-Audio7.0Aishell2
麦克风 | iOS | AndroidMMSpeech-base词错率4.5 | 3.9 | 4.0Paraformer-large- | 2.9 | -Qwen-Audio3.3 | 3.1 | 3.3Qwen2-Audio3.2 | 3.1 | 2.9语音翻译CoVoST2
英德 | 德英 |
英中 | 中英SALMONNBLEU18.6 | - | 33.1 | -SpeechLLaMA- | 27.1 | - | 12.3BLSP14.1 | - | - | -Qwen-Audio25.1 | 33.9 | 41.5 | 15.7Qwen2-Audio29.6 | 33.6 | 45.6 | 24.0 CoVoST2
西英 | 法英 | 意英 |SpeechLLaMABLEU27.9 | 25.2 | 25.9Qwen-Audio39.7 | 38.5 | 36.0Qwen2-Audio38.7 | 37.2 | 35.2语音情感识别MeldWavLM-large准确率0.542Qwen-Audio0.557Qwen2-Audio0.535声音分类VocalSoundCLAP准确率0.4945Pengi0.6035Qwen-Audio0.9289Qwen2-Audio0.9395 AIR-Bench
对话基准
语音 | 声音 |
音乐 | 混合音频SALMONN
BLSP
Pandagpt
Macaw-LLM
SpeechGPT
Next-gpt
Qwen-Audio
Gemini-1.5-pro
Qwen2-AudioGPT-46.16 | 6.28 | 5.95 | 6.08
6.17 | 5.55 | 5.08 | 5.33
3.58 | 5.46 | 5.06 | 4.25
0.97 | 1.01 | 0.91 | 1.01
1.57 | 0.95 | 0.95 | 4.13
3.86 | 4.76 | 4.18 | 4.13
6.47 | 6.95 | 5.52 | 6.08
6.97 | 5.49 | 5.06 | 5.27
7.24 | 6.83 | 6.73 | 6.42
我们提供了所有评估脚本以复现我们的结果。详情请参阅 eval_audio/EVALUATION.md。
环境要求
Qwen2-Audio 的代码已包含在最新的 Hugging Face transformers 中,我们建议您使用以下命令从源代码安装:pip install git+https://github.com/huggingface/transformers,否则您可能会遇到以下错误:
KeyError: 'qwen2-audio'
快速开始
以下我们提供简单的示例,展示如何使用 🤗 Transformers 来使用 Qwen2-Audio 和 Qwen2-Audio-Instruct。 在运行代码之前,请确保您已设置好环境并安装了所需的软件包。请确保您满足上述要求,然后安装依赖库。 现在您可以开始使用 ModelScope 或 Transformers。Qwen2-Audio 模型目前对 30 秒以内的音频片段表现最佳。
🤗 Transformers
在下面,我们演示如何使用 Qwen2-Audio-7B-Instruct 进行推理,支持语音聊天和音频分析两种模式。请注意,我们使用了 ChatML 格式进行对话,在这个演示中我们展示了如何利用 apply_chat_template 来实现这一目的。
语音聊天推理
在语音聊天模式下,用户可以与 Qwen2-Audio 自由进行语音交互,无需文本输入:
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"},
]},
{"role": "assistant", "content": "是的,说话者是二十多岁的女性。"},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav"},
]},
]
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios = []
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
音频分析推理
在音频分析中,用户可以同时提供音频和文本指令进行分析:
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation = [
{'role': 'system', 'content': '你是一个有用的助手。'},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "那是什么声音?"},
]},
{"role": "assistant", "content": "那是玻璃碎裂的声音。"},
{"role": "user", "content": [
{"type": "text", "text": "当你听到这种声音时你会怎么做?"},
]},
{"role": "assistant", "content": "保持警惕和谨慎,检查是否有人受伤或财产损坏。"},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "这个人说了什么?"},
]},
]
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios = []
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(
librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
批量推理
我们还支持批量推理:
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation1 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "那是什么声音?"},
]},
{"role": "assistant", "content": "那是玻璃碎裂的声音。"},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/f2641_0_throatclearing.wav"},
{"type": "text", "text": "你听到了什么?"},
]}
]
conversation2 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "这个人说了什么?"},
]},
]
conversations = [conversation1, conversation2]
text = [processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False) for conversation in conversations]
audios = []
for conversation in conversations:
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(
librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs['input_ids'] = inputs['input_ids'].to("cuda")
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
运行Qwen2-Audio预训练基础模型也很简单。
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import AutoProcessor, Qwen2AudioForConditionalGeneration
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B" ,trust_remote_code=True)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B" ,trust_remote_code=True)
prompt = "<|audio_bos|><|AUDIO|><|audio_eos|>用英语生成描述:"
url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Audio/glass-breaking-151256.mp3"
audio, sr = librosa.load(BytesIO(urlopen(url).read()), sr=processor.feature_extractor.sampling_rate)
inputs = processor(text=prompt, audios=audio, return_tensors="pt")
generated_ids = model.generate(**inputs, max_length=256)
generated_ids = generated_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
🤖 ModelScope
我们强烈建议用户特别是中国大陆的用户使用ModelScope。snapshot_download可以帮助你解决下载检查点的问题。
演示
Web UI
我们提供了代码让用户构建Web UI演示。在开始之前,请确保安装以下包:
pip install -r requirements_web_demo.txt
然后运行以下命令并点击生成的链接:
python demo/web_demo_audio.py
演示案例
更多令人印象深刻的案例将在我们的博客Qwen的博客上更新。
我们正在招聘
如果你有兴趣作为全职或实习生加入我们,请联系我们:qwen_audio@list.alibaba-inc.com。
许可协议
查看每个模型在其HF仓库内的许可证。你无需提交商业使用请求。
引用
如果你发现我们的论文和代码对你的研究有用,请考虑给一个星标 :star: 和引用 :pencil: :)
@article{Qwen-Audio,
title={Qwen-Audio: 通过统一的大规模音频-语言模型推进通用音频理解},
author={Chu, Yunfei and Xu, Jin and Zhou, Xiaohuan and Yang, Qian and Zhang, Shiliang and Yan, Zhijie and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2311.07919},
year={2023}
}
@article{Qwen2-Audio,
title={Qwen2-Audio 技术报告},
author={楚云飞 and 徐进 and 杨乾 and 魏浩杰 and 魏希品 and 郭志芳 and 冷一冲 and 吕远军 and 何金正 and 林俊阳 and 周畅 and 周靖人},
journal={arXiv预印本 arXiv:2407.10759},
year={2024}
}
联系我们
如果您想给我们的研究团队或产品团队留言,欢迎发送邮件至 qianwen_opensource@alibabacloud.com。












{kind=link}