
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文tfcausalimpact





基于TensorFlow Probability实现的谷歌因果影响算法。
工作原理
该算法基本上是在过去观察到的数据上拟合一个贝叶斯结构模型,以预测未来数据的样子。过去的数据包括干预之前发生的所有情况(干预通常是指某个变量的存在与否发生变化,例如在某个时点开始运行的营销活动)。然后,它将反事实(预测)序列与实际观察到的情况进行比较,以得出统计结论。
运行模型非常简单,它需要观察到的数据y,协变量X通过线性回归帮助模型,一个pre-period区间选择干预前发生的所有事情,以及一个包含"影响"发生后数据的post-period。
更多相关内容请参考这篇中等文章。
安装
pip install tfcausalimpact
要求
- python{3.7, 3.8, 3.9, 3.10, 3.11}
- matplotlib
- jinja2
- tensorflow>=2.10.0
- tensorflow_probability>=0.18.0
- pandas >= 1.3.5
入门
我们推荐观看Kay Brodersen(R语言因果影响的创建者之一)的这个演讲。
我们还创建了这个入门ipython笔记本,其中包含如何使用此包的示例。
这篇中等文章还提供了一些关于该库背后的想法和概念。
示例
以下是在Python中运行的一个简单示例(也可以在原始的Google R实现中找到):
import pandas as pd
from causalimpact import CausalImpact
data = pd.read_csv('https://raw.githubusercontent.com/WillianFuks/tfcausalimpact/master/tests/fixtures/arma_data.csv')[['y', 'X']]
data.iloc[70:, 0] += 5
pre_period = [0, 69]
post_period = [70, 99]
ci = CausalImpact(data, pre_period, post_period)
print(ci.summary())
print(ci.summary(output='report'))
ci.plot()
摘要应该看起来像这样:
后验推断 {因果影响}
平均值 累计
实际 125.23 3756.86
预测 (标准差) 120.34 (0.31) 3610.28 (9.28)
95% 置信区间 [119.76, 120.97] [3592.67, 3629.06]
绝对效应 (标准差) 4.89 (0.31) 146.58 (9.28)
95% 置信区间 [4.26, 5.47] [127.8, 164.19]
相对效应 (标准差) 4.06% (0.26%) 4.06% (0.26%)
95% 置信区间 [3.54%, 4.55%] [3.54%, 4.55%]
后验尾部区域概率 p:0.0
因果效应的后验概率:100.0%
欲了解更多详情,请运行命令:print(impact.summary('report'))
以下是绘图结果:
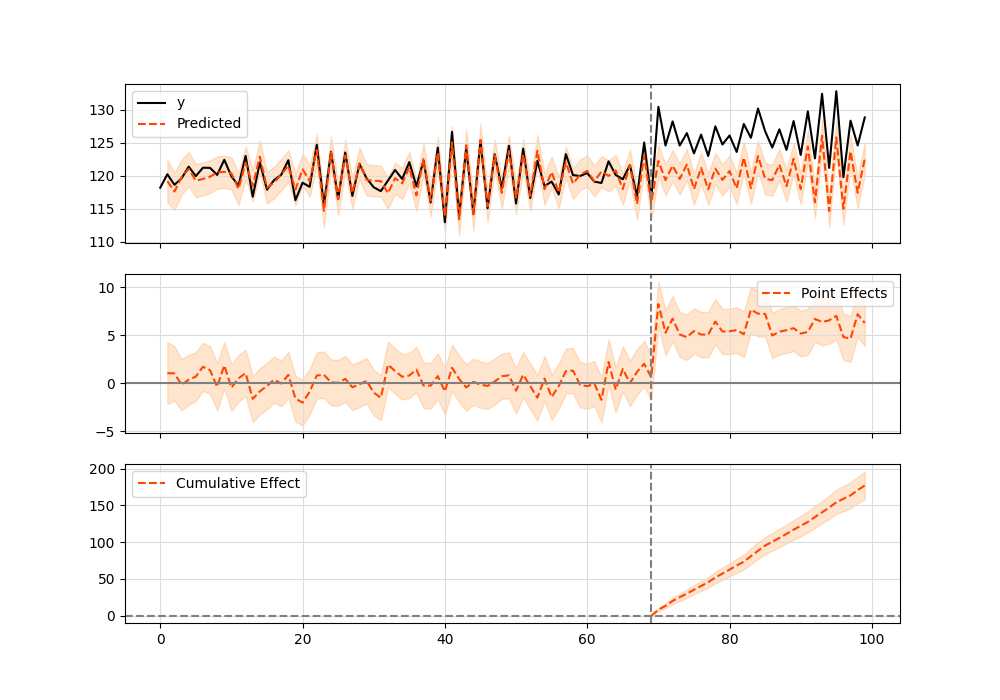
Google R 包与 TensorFlow Python 对比
两个包应该给出等效的结果。以下是使用 fixtures 文件夹中可用的 comparison_data.csv 数据集的示例。在原始 R 包中运行 CausalImpact 时,结果如下:
R
data = read.csv.zoo('comparison_data.csv', header=TRUE)
pre.period <- c(as.Date("2019-04-16"), as.Date("2019-07-14"))
post.period <- c(as.Date("2019-07-15"), as.Date("2019-08-01"))
ci = CausalImpact(data, pre.period, post.period)
摘要结果:
后验推断 {CausalImpact}
平均值 累计
实际 78574 1414340
预测 (标准差) 79232 (736) 1426171 (13253)
95% 置信区间 [77743, 80651] [1399368, 1451711]
绝对效应 (标准差) -657 (736) -11831 (13253)
95% 置信区间 [-2076, 832] [-37371, 14971]
相对效应 (标准差) -0.83% (0.93%) -0.83% (0.93%)
95% 置信区间 [-2.6%, 1%] [-2.6%, 1%]
后验尾部概率 p: 0.20061
因果效应的后验概率: 80%
更多详情,请输入:summary(impact, "report")
对应的图表:
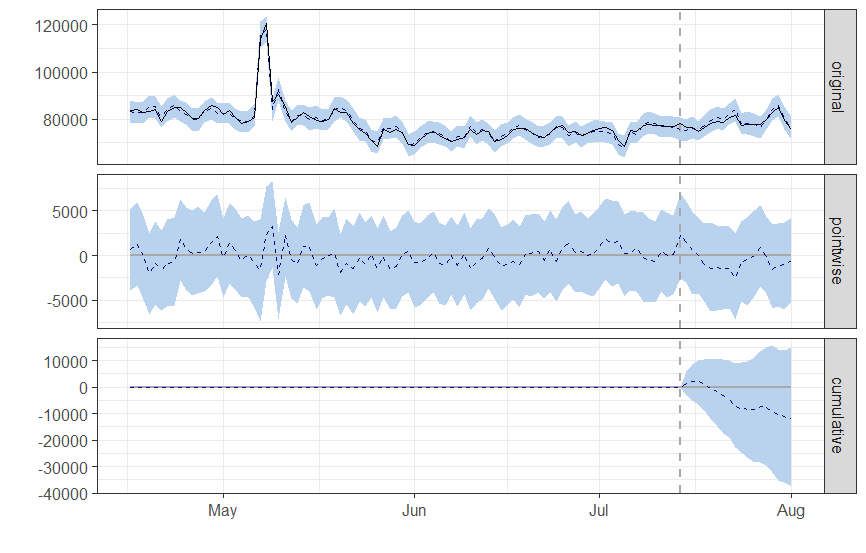
Python
import pandas as pd
from causalimpact import CausalImpact
data = pd.read_csv('https://raw.githubusercontent.com/WillianFuks/tfcausalimpact/master/tests/fixtures/comparison_data.csv', index_col=['DATE'])
pre_period = ['2019-04-16', '2019-07-14']
post_period = ['2019-7-15', '2019-08-01']
ci = CausalImpact(data, pre_period, post_period, model_args={'fit_method': 'hmc'})
摘要如下:
后验推断 {因果影响}
平均值 累计
实际 78574.42 1414339.5
预测 (标准差) 79282.92 (727.48) 1427092.62 (13094.72)
95% 置信区间 [77849.5, 80701.18][1401290.94, 1452621.31]
绝对效应 (标准差) -708.51 (727.48) -12753.12 (13094.72)
95% 置信区间 [-2126.77, 724.92] [-38281.81, 13048.56]
相对效应 (标准差) -0.89% (0.92%) -0.89% (0.92%)
95% 置信区间 [-2.68%, 0.91%] [-2.68%, 0.91%]
后验尾部概率 p:0.16
因果效应的后验概率:84.12%
更多详情请运行命令:print(impact.summary('report'))
图表:
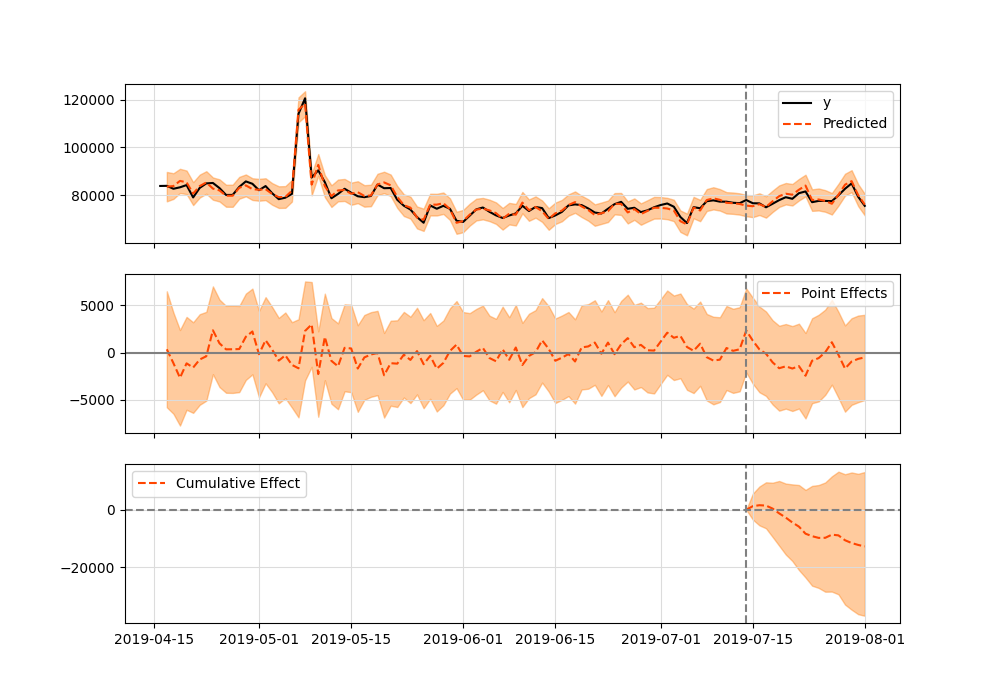
两个结果是等效的。
性能
该包默认使用 TensorFlow Probability 的 变分推断 方法,这种方法更快,在大多数情况下都应该可以工作。对于较复杂的时间序列,收敛可能需要 2~3 分钟。你也可以尝试在 GPU 上运行该包,看看结果是否有所改善。
另一方面,如果在进行因果影响分析时精度是最重要的要求,可以通过操作输入参数来切换算法,如下所示:
ci = CausalImpact(data, pre_period, post_period, model_args={'fit_method': 'hmc'})
这将使用 哈密顿蒙特卡罗 算法,该算法是寻找分布贝叶斯后验的最先进方法。不过,请记住,对于包含数千个数据点和涉及各种季节性组件的复杂建模的复杂时间序列,这种优化可能需要 1 小时甚至更长时间才能完成(在 GPU 上)。为了获得更高的精度,牺牲了性能。
错误与问题
如果您在运行此库时发现bugs或遇到任何问题,请考虑在GitHub上开启一个Issue,并提供完整的描述和可复现的环境,这样我们就能更好地帮助您解决问题。











