
 Github
Github Huggingface
Huggingface 论文
论文Youku-mPLUG 1000万中文大规模视频文本数据集
Youku-mPLUG:一个1000万规模的中文视频-语言预训练数据集和基准测试 下载链接在此

什么是Youku-mPLUG?
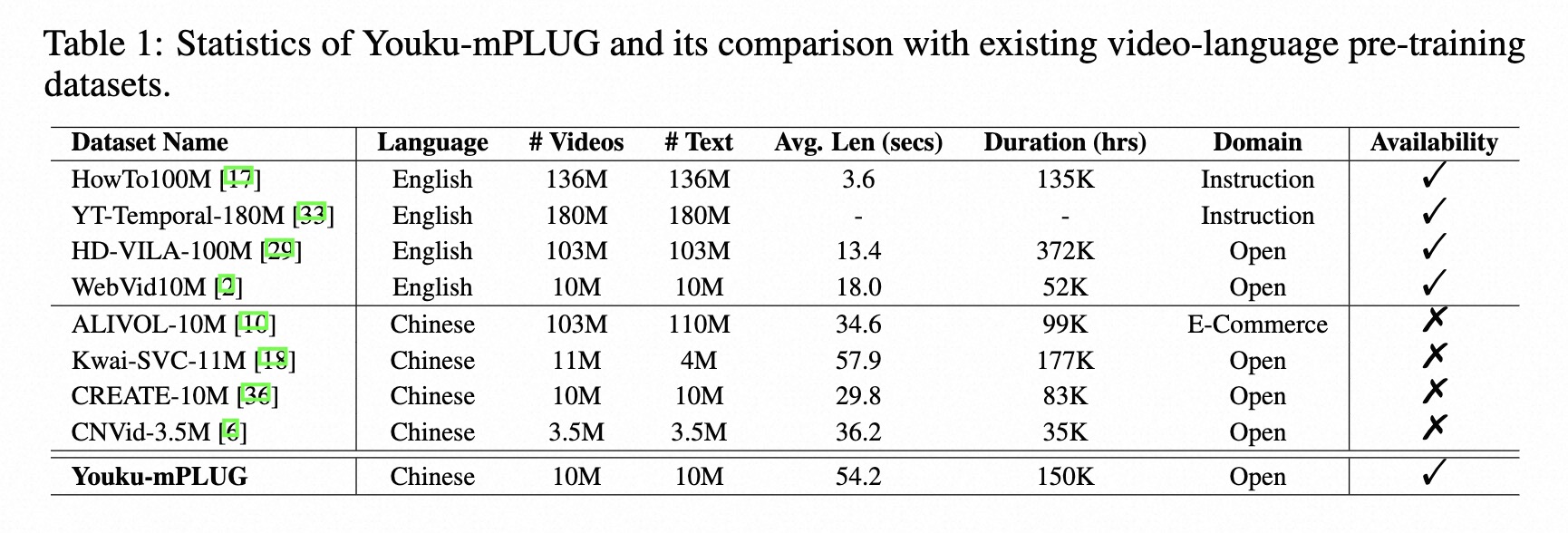
我们发布了迄今为止最大的中文高质量视频-语言数据集(1000万规模),名为Youku-mPLUG。该数据集来源于知名中文视频分享网站优酷,经过严格的安全性、多样性和质量筛选标准。

Youku-mPLUG数据集中视频片段和标题的示例。
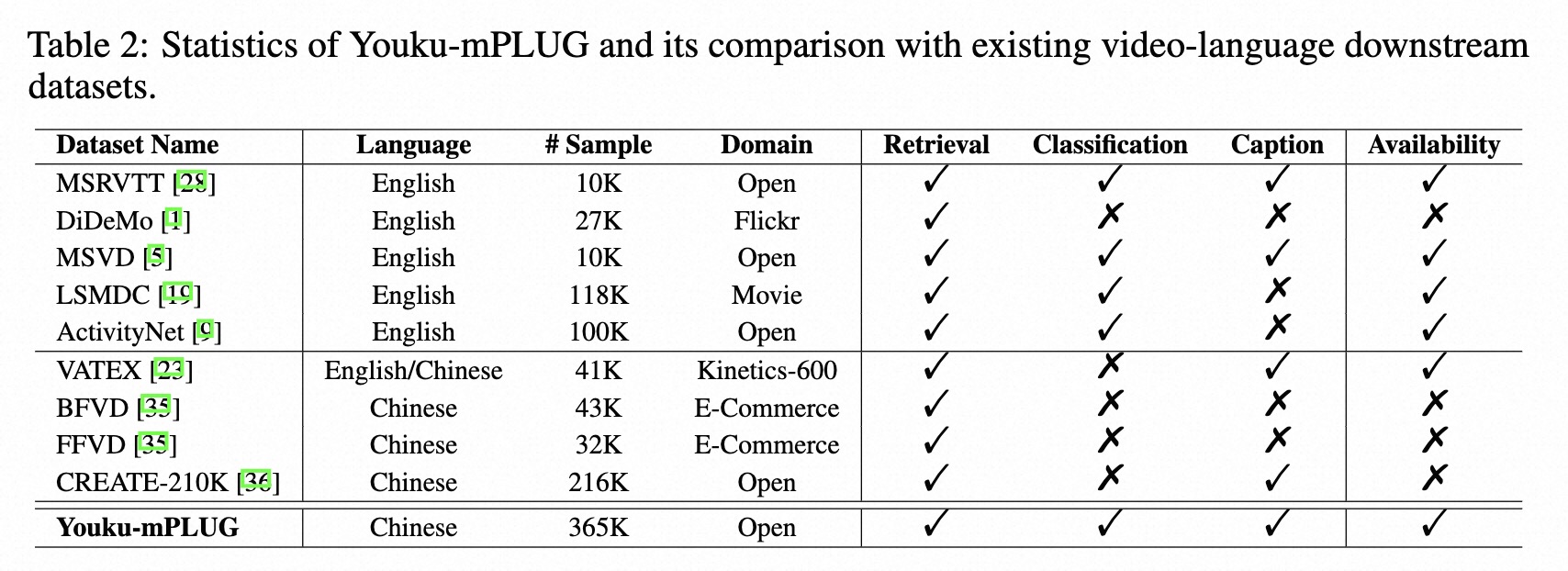
我们提供了3个不同的下游多模态视频基准数据集,用于评估预训练模型的能力。这3个不同的任务包括:
- 视频类别预测:给定一个视频及其对应的标题,预测该视频的类别。
- 视频-文本检索:在一些视频和文本存在的情况下,使用视频检索文本和使用文本检索视频。
- 视频描述:给定一个视频,描述视频的内容。
数据统计
该数据集总共包含1000万个高质量视频,分布在20个超类别和45个类别中。
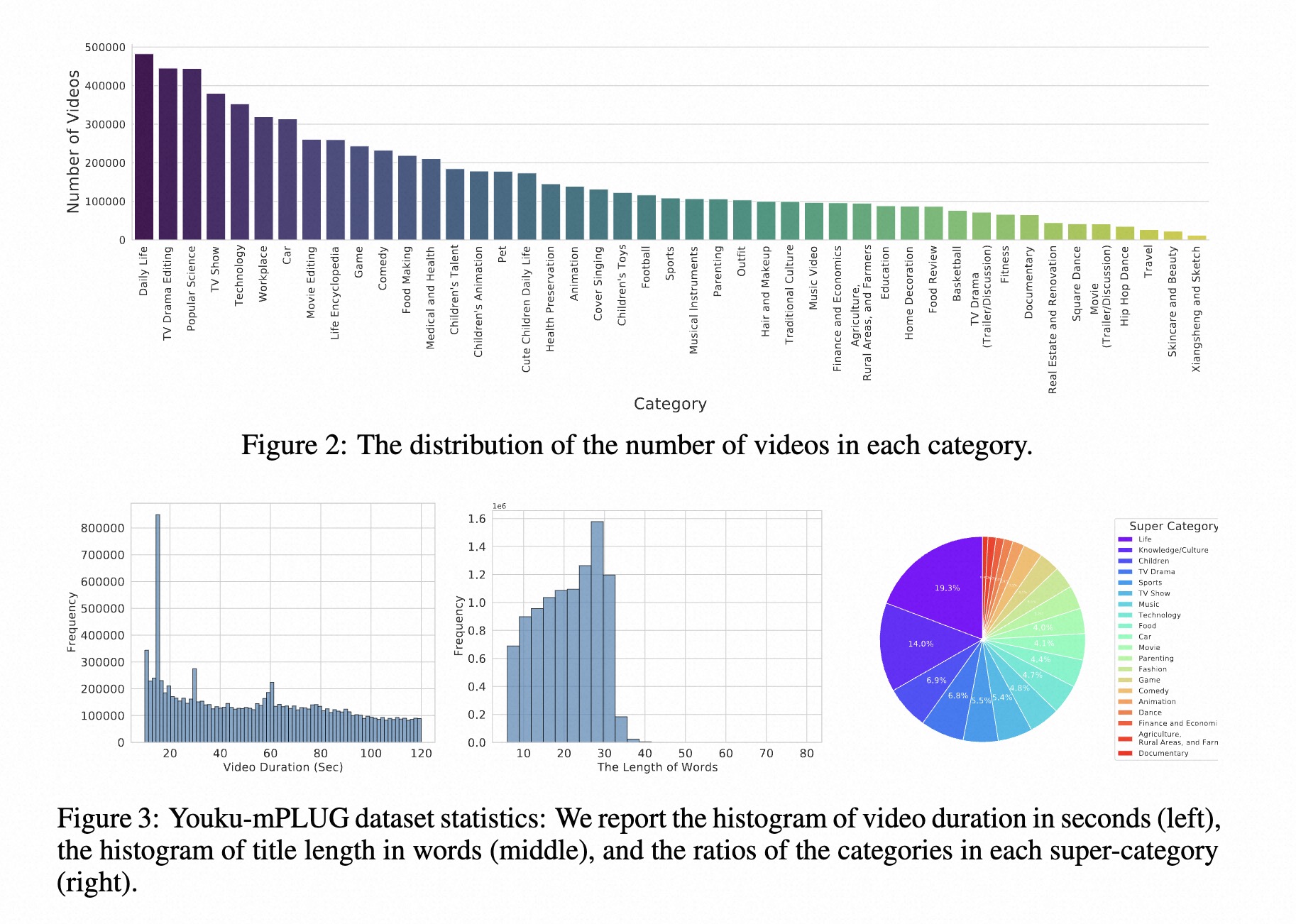
Youku-mPLUG数据集中类别的分布。
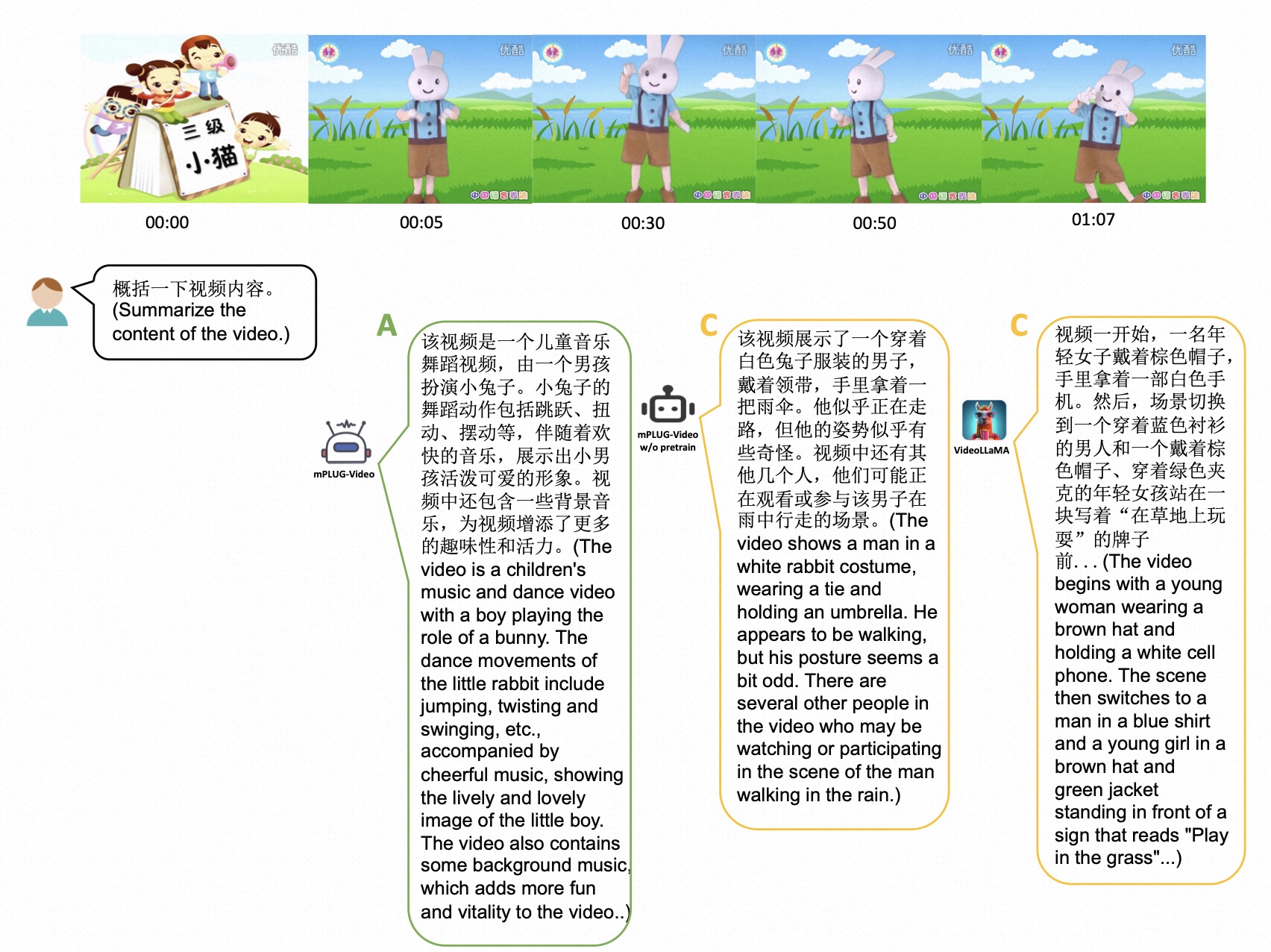
零样本能力

下载
您可以通过此链接下载所有视频和注释文件
设置
注意:由于megatron_util存在bug,安装megatron_util后,需要用当前目录下的initialize.py替换conda/envs/youku/lib/python3.10/site-packages/megatron_util/initialize.py。
conda env create -f environment.yml
conda activate youku
pip install megatron_util==1.3.0 -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 用于描述评估
apt-get install default-jre
mPLUG-Video (1.3B / 2.7B)
预训练
首先,您应该从Modelscope下载GPT-3 1.3B和2.7B检查点。预训练模型可以在这里(1.3B)和这里(2.7B)下载。 运行 mPLUG-Video 的预训练如下:
exp_name='pretrain/gpt3_1.3B/pretrain_gpt3_freezeGPT_youku_v0'
PYTHONPATH=$PYTHONPATH:./ \
python -m torch.distributed.launch --nproc_per_node=8 --master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
--nnodes=$WORLD_SIZE \
--node_rank=$RANK \
--use_env run_pretrain_distributed_gpt3.py \
--config ./configs/${exp_name}.yaml \
--output_dir ./output/${exp_name} \
--enable_deepspeed \
--bf16
2>&1 | tee ./output/${exp_name}/train.log
基准测试
执行下游微调。以视频分类预测为例:
exp_name='cls/cls_gpt3_1.3B_youku_v0_sharp_2'
PYTHONPATH=$PYTHONPATH:./ \
python -m torch.distributed.launch --nproc_per_node=8 --master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
--nnodes=$WORLD_SIZE \
--node_rank=$RANK \
--use_env downstream/run_cls_distributed_gpt3.py \
--config ./configs/${exp_name}.yaml \
--output_dir ./output/${exp_name} \
--enable_deepspeed \
--resume path/to/1_3B_mp_rank_00_model_states.pt \
--bf16
2>&1 | tee ./output/${exp_name}/train.log
实验结果
以下展示了验证集上的结果以供参考。

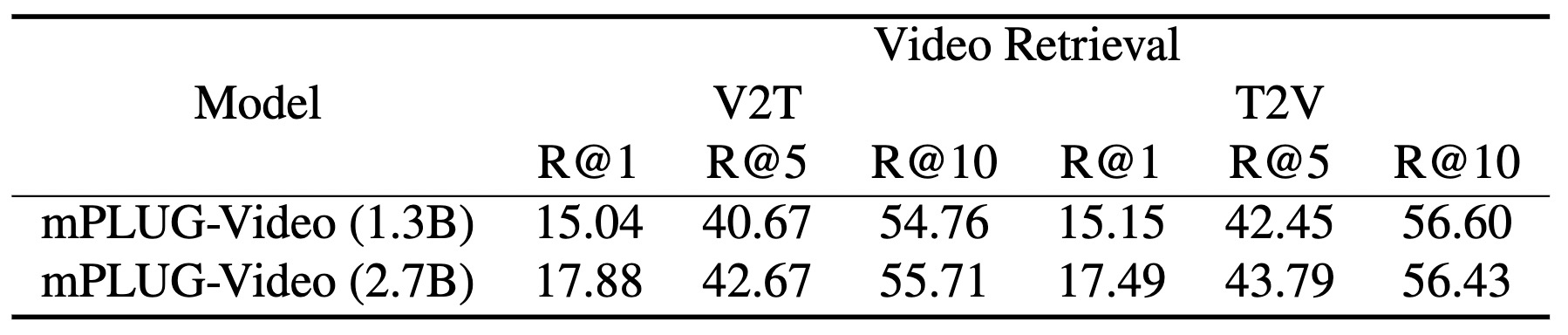
mPLUG-Video (BloomZ-7B)
我们基于 mPLUG-Owl 构建了 mPLUG-Video 模型。要使用该模型,你应该首先克隆 mPLUG-Owl 仓库:
git clone https://github.com/X-PLUG/mPLUG-Owl.git
cd mPLUG-Owl/mPLUG-Owl
指令微调后的检查点可在 HuggingFace 上获取。对于模型微调,你可以参考 mPLUG-Owl 仓库。要进行视频推理,你可以使用以下代码:
import torch
from mplug_owl_video.modeling_mplug_owl import MplugOwlForConditionalGeneration
from transformers import AutoTokenizer
from mplug_owl_video.processing_mplug_owl import MplugOwlImageProcessor, MplugOwlProcessor
pretrained_ckpt = 'MAGAer13/mplug-youku-bloomz-7b'
model = MplugOwlForConditionalGeneration.from_pretrained(
pretrained_ckpt,
torch_dtype=torch.bfloat16,
device_map={'': 0},
)
image_processor = MplugOwlImageProcessor.from_pretrained(pretrained_ckpt)
tokenizer = AutoTokenizer.from_pretrained(pretrained_ckpt)
processor = MplugOwlProcessor(image_processor, tokenizer)
# 我们使用人类/AI模板将上下文组织为多轮对话。
# <|video|> 表示视频占位符。
prompts = [
'''以下是好奇的人类与AI助手之间的对话。助手对用户的问题给出有帮助、详细且礼貌的回答。
Human: <|video|>
Human: 视频中的女人在干什么?
AI: ''']
video_list = ['yoga.mp4']
# generate kwargs(与transformers中相同)可以在do_generate()中传递
generate_kwargs = {
'do_sample': True,
'top_k': 5,
'max_length': 512
}
inputs = processor(text=prompts, videos=video_list, num_frames=4, return_tensors='pt')
inputs = {k: v.bfloat16() if v.dtype == torch.float else v for k, v in inputs.items()}
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
res = model.generate(**inputs, **generate_kwargs)
sentence = tokenizer.decode(res.tolist()[0], skip_special_tokens=True)
print(sentence)
引用 Youku-mPLUG
如果你发现这个数据集对你的研究有用,请考虑引用我们的论文。
@misc{许海洋2023优酷_mplug,
title={优酷-mPLUG:一个包含1000万规模的中文视频-语言数据集用于预训练和基准测试},
author={许海洋, 叶青昊, 吴轩, 闫明, 缪远, 叶家博, 徐国海, 胡安文, 史亚亚, 李晨亮, 钱琪, 阙茂飞, 张继, 曾晓, 黄飞},
year={2023},
eprint={2306.04362},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











