
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

DiffBIR: 基于生成扩散先验的盲图像恢复


林新琪1,*, 何婧雯2,3,*, 陈子言1, 吕昭阳2, 戴波2, 于方华1, 欧阳万里2, 乔宇2, 董超1,2
1中国科学院深圳先进技术研究院
2上海人工智能实验室
3香港中文大学


:star:如果DiffBIR对你有帮助,请给这个仓库点个星。谢谢!:hugs:
:book:目录
:new:更新
- 2024.04.08: ✅ 发布了关于我们更新后论文的所有内容,包括(1)在laion2b-en子集上训练的新模型和(2)一个更易读的代码库等。DiffBIR现在是一个通用的恢复流程,可以用统一的生成模块处理不同的盲图像恢复任务。
- 2023.09.19: ✅ 增加了对Apple Silicon的支持!查看installation_xOS.md以在CPU/CUDA/MPS设备上工作!
- 2023.09.14: ✅ 集成了基于补丁的采样策略(mixture-of-diffusers)。试试看! 这里有一个例子,分辨率为2396 x 1596。GPU内存使用将在未来继续优化,我们期待您的拉取请求!
- 2023.09.14: ✅ 在人脸增强中增加了背景上采样器(DiffBIR/RealESRGAN)的支持!:rocket: 试试看!
- 2023.09.13: :rocket: 在OpenXLab提供在线演示(DiffBIR-official),集成了通用模型和人脸模型。请尝试一下!camenduru也实现了一个在线演示,感谢他的工作。:hugs:
- 2023.09.12: ✅ 上传了潜在图像引导的推理代码并发布了real47测试集。
- 2023.09.08: ✅ 增加了对未对齐人脸的恢复支持。
- 2023.09.06: :rocket: 更新了colab演示。感谢camenduru!:hugs:
- 2023.08.30: 本仓库已发布。
:eyes:真实世界图像上的视觉效果
盲图像超分辨率
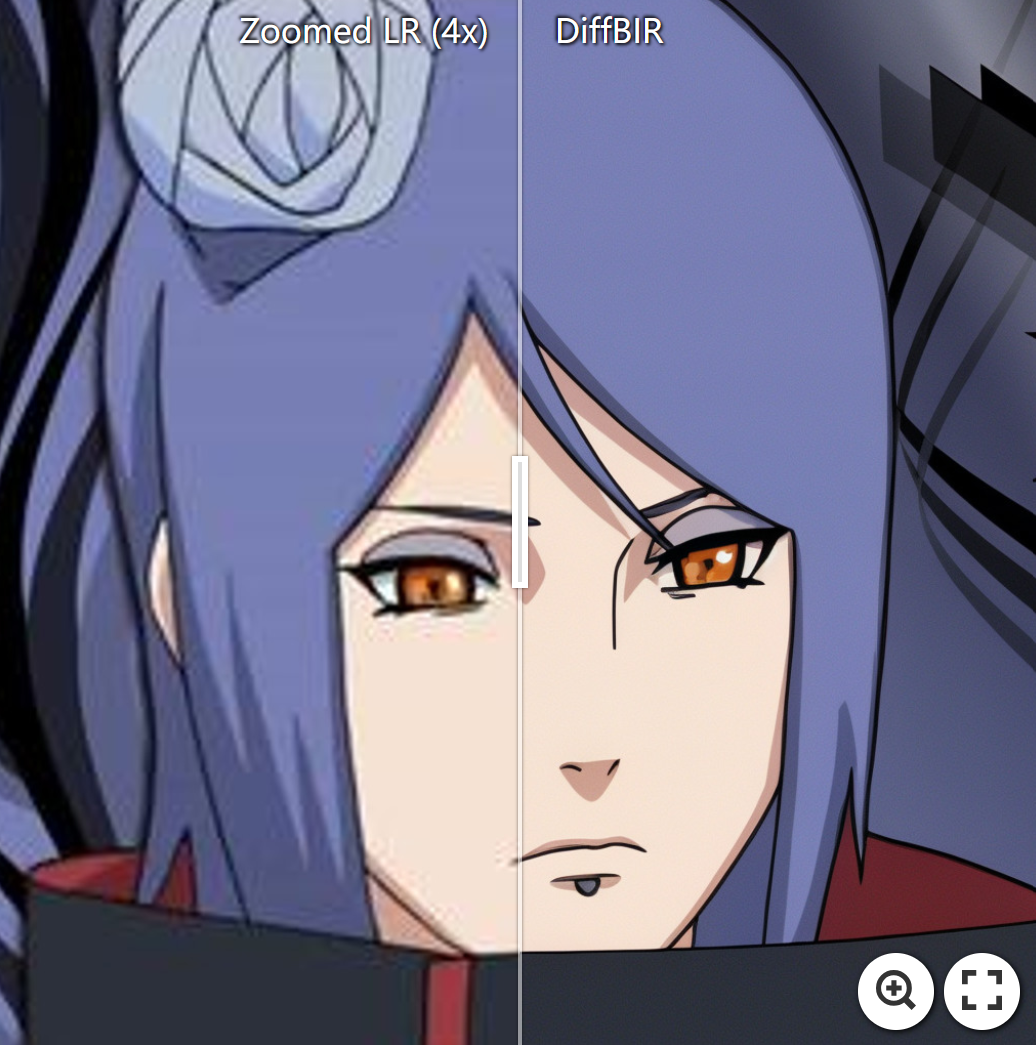


盲人脸修复
:star: 使用DiffBIR增强面部和背景。
盲图像去噪
8倍盲超分辨率与基于补丁的采样
我经常想起袋底洞。我想念我的书、我的扶手椅和我的花园。看,那才是我属于的地方。那里才是家。--- 比尔博·巴金斯
:climbing:待办事项
- 发布代码和预训练模型 :computer:。
- 更新论文和项目页面链接 :link:。
- 发布real47测试集 :minidisc:。
- 提供网页界面。
- 减少DiffBIR的显存使用 :fire::fire::fire:。
- 提供HuggingFace演示 :notebook:。
- 添加基于补丁的采样计划 :mag:。
- 上传潜在图像引导的推理代码 :page_facing_up:。
- 提高性能 :superhero:。
- 支持MacOS用户的MPS加速。
- DiffBIR-turbo :fire::fire::fire:。
- 加快推理速度,如使用fp16/bf16、torch.compile :fire::fire::fire:。
:gear:安装
# 克隆此仓库
git clone https://github.com/XPixelGroup/DiffBIR.git
cd DiffBIR
# 创建环境
conda create -n diffbir python=3.10
conda activate diffbir
pip install -r requirements.txt
我们的新代码基于pytorch 2.2.2,以内置支持内存高效注意力机制。如果你使用的GPU与最新的pytorch不兼容,只需将pytorch降级到1.13.1+cu116并安装xformers 0.0.16作为替代方案。
:dna:预训练模型
这里我们列出了第二阶段模型(IRControlNet)的预训练权重和我们训练的SwinIR,后者在第二阶段模型训练期间用于退化去除。
| 模型名称 | 描述 | HuggingFace | 百度网盘 | OpenXLab |
|---|---|---|---|---|
| v2.pth | 在过滤后的laion2b-en上训练的IRControlNet | 下载 | 下载 (密码: xiu3) | 下载 |
| v1_general.pth | 在ImageNet-1k上训练的IRControlNet | 下载 | 下载 (密码: 79n9) | 下载 |
| v1_face.pth | 在FFHQ上训练的IRControlNet | 下载 | 下载 (密码: n7dx) | 下载 |
| codeformer_swinir.ckpt | 在ImageNet-1k上训练的SwinIR | 下载 | 下载 (密码: vfif) | 下载 |
在推理过程中,我们使用其他论文中的现成模型作为第一阶段模型:BSR使用BSRNet,BFR使用SwinIR-Face(在DifFace中使用),BID使用SCUNet-PSNR,而训练好的IRControlNet在所有任务中保持不变。更多细节请查看代码。感谢他们的工作!
:crossed_swords:推理
我们提供了一些推理示例,更多参数请查看inference.py。预训练权重将自动下载。
盲图像超分辨率
python -u inference.py \
--version v2 \
--task sr \
--upscale 4 \
--cfg_scale 4.0 \
--input inputs/demo/bsr \
--output results/demo_bsr \
--device cuda
盲人脸修复
# 对于对齐的人脸输入
python -u inference.py \
--version v2 \
--task fr \
--upscale 1 \
--cfg_scale 4.0 \
--input inputs/demo/bfr/aligned \
--output results/demo_bfr_aligned \
--device cuda
# 对于未对齐的人脸输入
python -u inference.py \
--version v2 \
--task fr_bg \
--upscale 2 \
--cfg_scale 4.0 \
--input inputs/demo/bfr/whole_img \
--output results/demo_bfr_unaligned \
--device cuda
盲图像去噪
python -u inference.py \
--version v2 \
--task dn \
--upscale 1 \
--cfg_scale 4.0 \
--input inputs/demo/bid \
--output results/demo_bid \
--device cuda
其他选项
基于块的采样
添加以下参数以启用基于块的采样:
[命令...] --tiled --tile_size 512 --tile_stride 256
基于块的采样支持大比例因子的超分辨率。我们的基于块的采样是基于mixture-of-diffusers构建的。感谢他们的工作!
修复引导
修复引导用于在质量和保真度之间取得平衡。我们默认关闭它,因为我们更倾向于质量而非保真度。以下是一个示例:
python -u inference.py \
--version v2 \
--task sr \
--upscale 4 \
--cfg_scale 4.0 \
--input inputs/demo/bsr \
--guidance --g_loss w_mse --g_scale 0.5 --g_space rgb \
--output results/demo_bsr_wg \
--device cuda
你会看到结果变得更加平滑。
更好的采样起点
添加以下参数以提供更好的逆向采样起点:
[命令...] --better_start
此选项可防止我们的模型在图像背景中生成噪声。
:stars:训练
第一阶段
首先,我们训练一个SwinIR,它将在第二阶段训练期间用于退化去除。
-
生成训练集和验证集的文件列表,文件列表格式如下:
/path/to/image_1 /path/to/image_2 /path/to/image_3 ...你可以编写一个简单的Python脚本或直接使用shell命令来生成文件列表。以下是一个示例:
# 收集img_dir中的所有图像文件 find [img_dir] -type f > files.list # 随机打乱收集的文件 shuf files.list > files_shuf.list # 选取前train_size个文件作为训练集 head -n [train_size] files_shuf.list > files_shuf_train.list # 选取剩余文件作为验证集 tail -n +[train_size + 1] files_shuf.list > files_shuf_val.list -
在训练配置文件中填入适当的值。
-
开始训练!
accelerate launch train_stage1.py --config configs/train/train_stage1.yaml
第二阶段
- 下载预训练的Stable Diffusion v2.1以提供生成能力。:bulb::如果你已经运行过推理脚本,SD v2.1检查点可以在weights目录中找到。
wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt --no-check-certificate
-
按照上述方法生成文件列表。目前,第二阶段的训练脚本不支持验证集,所以你只需要创建训练文件列表。
-
在训练配置文件中填入适当的值。
-
开始训练!
accelerate launch train_stage2.py --config configs/train/train_stage2.yaml
引用
如果我们的工作对您的研究有帮助,请引用我们。
@misc{lin2024diffbir,
title={DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior},
author={Xinqi Lin and Jingwen He and Ziyan Chen and Zhaoyang Lyu and Bo Dai and Fanghua Yu and Wanli Ouyang and Yu Qiao and Chao Dong},
year={2024},
eprint={2308.15070},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
许可证
本项目根据Apache 2.0 许可证发布。
致谢
本项目基于ControlNet和BasicSR。感谢他们出色的工作。
联系方式
如果您有任何问题,欢迎通过linxinqi23@mails.ucas.ac.cn与我联系。











